

我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode 。
0x0. 预览版
上周 MiniMax 开源了他们 4560 亿参数的 MoE 大模型,其中一个亮点是这个模型是一个Lightning Attention和Softmax Attention的混合架构,技术报告链接见:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf 。关于这个模型更多的细节推荐感兴趣的朋友读 @sonta 的回答:https://www.zhihu.com/question/9630107500/answer/79882585725
提到 Linear Attention 我也不困了,去年就对RWKV架构产生过兴趣也做过开源贡献,同时也了解了Linear Attention架构的一些算法原理和做推理的优势,具体可以参考我之前的几篇blog:
-
在GPU上加速RWKV6模型的Linear Attention计算 -
flash-linear-attention的fused_recurrent_rwkv6 Triton实现精读 -
flash-linear-attention中的Chunkwise并行算法的理解 -
硬件高效的线性注意力机制Gated Linear Attention论文阅读
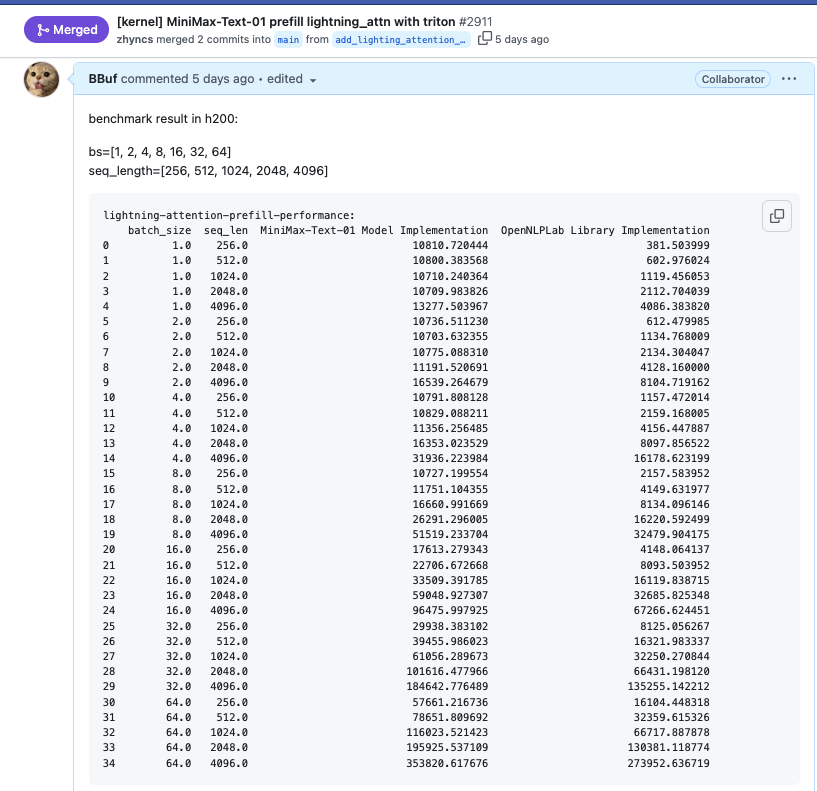
如果要在 SGLang 推理框架中去支持MiniMax Text01 模型,首先就需要实现 https://huggingface.co/MiniMaxAI/MiniMax-Text-01/blob/main/modeling_minimax_text_01.py 中的 MiniMaxText01LightningAttention 模块,这个正是我所擅长的。所以几乎用了一个完整的周末在 SGLang 中建立了 MiniMaxText01LightningAttention 这个模块的 Prefill 和 Decode 过程的优化算子和 Benchmark,对于 Prefiil 来说我只建立了一个 Benchmark ,使用了 OpenNLPLab 提供的lightning_attn2的 Triton 算子 https://github.com/OpenNLPLab/lightning-attention/blob/main/lightning_attn/ops/triton/lightning_attn2.py 。这个 Triton 算子相比于 HuggingFace 的原始实现把 Prefill 端到端耗时提升了数倍,可以参考下面的截图:
而对于 Decode 阶段来说,这是一个典型的 Memory Bound 的算子,这个算子的Python代码单独抽出来非常简单。也是我这篇文章的起点,就是把这个算子的性能优化一下,提升带宽利用率和降低执行时间。然后我展示了一下如何正确的使用Cursor结合NCU来尝试做CUDA优化。
首先,这个算子的PyTorch代码可以写成下面这几行:
def lightning_attention_decode_naive(q, k, v, past_kv, slope):
"""Naive implementation of lightning attention decode"""
original_dtype = q.dtype
ratio = torch.exp(-slope) # [h, 1, 1]
kv = past_kv
b, h, n, d = q.shape
output = []
for i in range(n):
kv = ratio * kv.to(torch.float32) + torch.einsum(
"... n d, ... n e -> ... d e",
k[:, :, i : i + 1],
v[:, :, i : i + 1],
)
qkv = torch.einsum(
"... n e, ... e d -> ... n d",
q[:, :, i : i + 1].to(torch.float32),
kv.to(torch.float32),
)
output.append(qkv)
output = torch.concat(output, dim=-2)
return output.to(original_dtype), kv
其中,输入Tensor的形状如下截图:

其次,我这里的目标就是优化一下这个Kernel,尽可能的提升带宽利用率并且降低kernel的耗时。总的来说,我在Cursor的协助下写了2个版本的Triton Kernel,以及几个版本的CUDA Kernel,最后无论是在lightning_attention_decode这个算子的Micro Benchmark还是端到端的Lightning Attention模块的耗时相比于原始的PyTorch实现都实现了加速,对于算子来说在batch较小时可达到2倍加速。
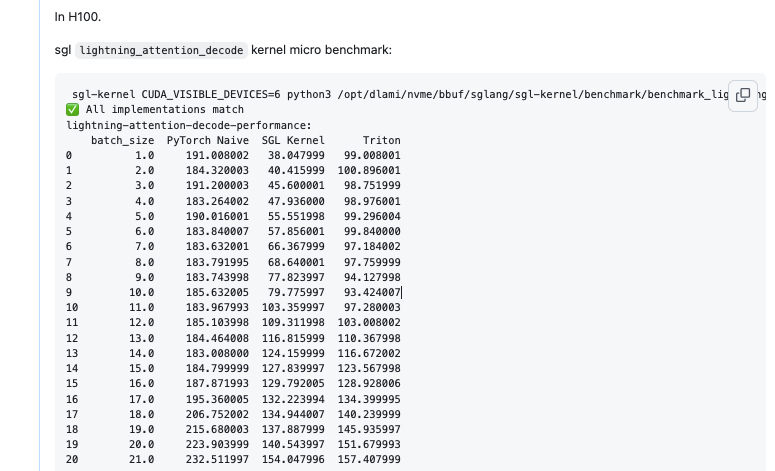
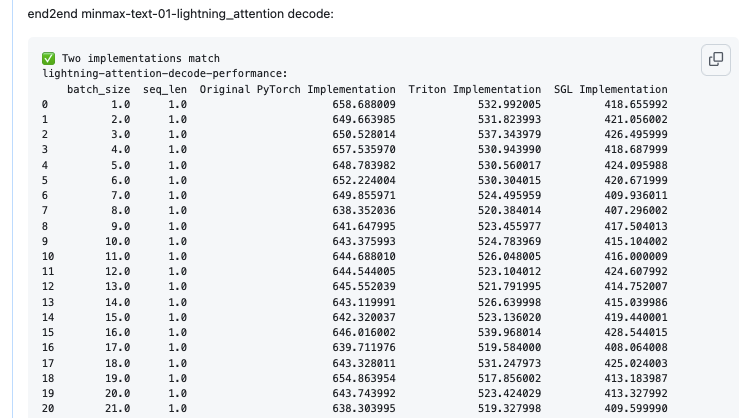
详细数据可以参考 https://github.com/sgl-project/sglang/pull/3030
最后,这个kernel还有非常大的可提升空间,不过这不是本文重点,本文的重点是我将在下一节演示一下我是如何使用Cursor+NCU来联合优化CUDA Kernel的,如果你想在Cursor中使用最先进的Claude-3.5-sonnet-20241022来直接给你写出性能不错的CUDA kernel,根据我的使用记录来看是非常困难的。大模型既不会给你避免Bank Conflict,也不会给你合并内存访问,并且大多数时候还会给你写出效率非常低的Python直译cuda代码。然而Cursor下的Claude-3.5-sonnet-2024102有多模态功能是可以看懂图片的,所以我们可以把NCU的一些关键Profile信息给他,手工强化学习,我稍后会演示如何利用NCU的结果让Cursor更聪明,从而写出我们想要的优化代码。
0x1. 实操版
0x1.1 Triton naive版本
kernel代码:https://github.com/sgl-project/sglang/pull/2920/files#diff-16ed66afc4b7f52545a3fffd55c9fd6daaf87189d9a0d252fccba42951c1cc40R14-R105
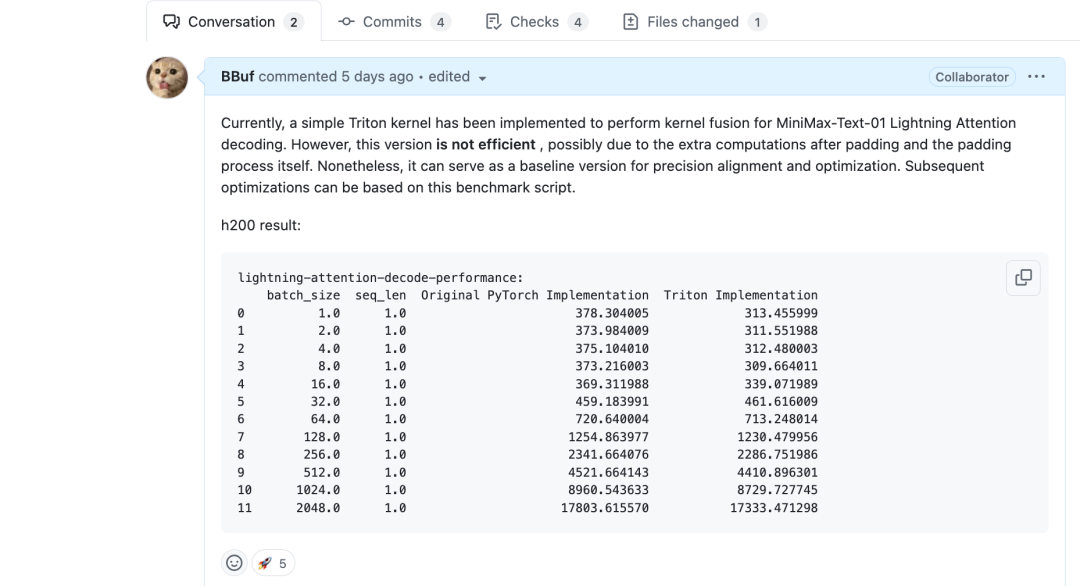
首先是一个最Naive的版本,对于q,k,v的每个头使用一个Block来计算,也就是一共有个Block,然后每个头的维度都从92 padding到128来满足Triton kernel的计算需求。
从上面的性能结果来看,和原始的PyTorch实现几乎没有区别。
0x1.2 Triton 优化版本
https://github.com/sgl-project/sglang/pull/2966

把上面的naive版本的Triton kernel之前的手动Padding到128移除了,然后在kernel中使用Mask的方式来解决dim维度没有对齐到2的幂次的问题。从上面的结果可以看到,Lightning Attention模块的端到端时间确实是下降了一些。
0x1.3 CUDA 版本
把上面那几行 Lighting Attention Decode Python代码直接扔给Cursor Sonnet 3.5 20241022模型,然后它很快就产生了一份cuda kernel。
#define THREADS_PER_BLOCK 128
template<typename T>
__global__ void lightning_attention_decode_kernel(
const T* __restrict__ q, // [b, h, 1, d]
const T* __restrict__ k, // [b, h, 1, d]
const T* __restrict__ v, // [b, h, 1, e]
const float* __restrict__ past_kv, // [b, h, d, e]
const float* __restrict__ slope, // [h, 1, 1]
T* __restrict__ output, // [b, h, 1, e]
float* __restrict__ new_kv, // [b, h, d, e]
const int batch_size,
const int num_heads,
const int dim,
const int embed_dim) {
const int32_t tid = threadIdx.x;
const int32_t current_head = blockIdx.x;
const int32_t b = current_head / num_heads;
const int32_t h = current_head % num_heads;
if (b >= batch_size) return;
const int32_t qk_offset = b * num_heads * dim + h * dim;
const int32_t v_offset = b * num_heads * embed_dim + h * embed_dim;
const int32_t kv_offset = b * num_heads * dim * embed_dim + h * dim * embed_dim;
// 1. 计算新的kv: new_kv = ratio * past_kv + k * v^T
const float ratio = expf(-1.0f * slope[h]);
for (int d = tid; d < dim; d += THREADS_PER_BLOCK) {
T k_value = k[qk_offset + d];
for (int e = 0; e < embed_dim; e++) {
const int32_t kv_index = kv_offset + d * embed_dim + e;
new_kv[kv_index] = ratio * past_kv[kv_index] + k_value * v[v_offset + e];
}
}
__syncthreads(); // 确保所有线程完成new_kv的计算
// 2. 计算qkv attention输出: output = q * new_kv
for (int e = tid; e < embed_dim; e += THREADS_PER_BLOCK) {
float sum = 0.0f;
但是测试Benchmark之后可以发现这个版本的kernel性能相比于Triton算子的耗时会慢5倍左右。
想找出性能差异的原因,最靠谱的方法就是分析下nuc的结果,我写了下面的profile脚本:
import math
import torch
import triton
import triton.language as tl
from sgl_kernel import lightning_attention_decode
def next_power_of_2(n):
return 2 ** (int(math.ceil(math.log(n, 2))))
@triton.jit
def _decode_kernel(
Q,
K,
V,
KV,
Out,
S,
b: tl.constexpr,
h: tl.constexpr,
n: tl.constexpr,
d: tl.constexpr,
d_original: tl.constexpr,
e: tl.constexpr,
e_original: tl.constexpr,
):
off_bh = tl.program_id(0)
off_h = off_bh % h
qk_offset = off_bh * n * d
v_offset = off_bh * n * e
o_offset = off_bh * n * e
kv_offset = off_bh * d * e
s = tl.load(S + off_h)
ratio = tl.exp(-s)
d_idx = tl.arange(0, d)
e_idx = tl.arange(0, e)
# Create masks for original dimensions
d_mask = d_idx < d_original
e_mask = e_idx < e_original
# Load with masking
q = tl.load(Q + qk_offset + d_idx, mask=d_mask, other=0.0)
k = tl.load(K + qk_offset + d_idx, mask=d_mask, other=0.0)
v = tl.load(V + v_offset + e_idx, mask=e_mask, other=0.0)
# Load KV with 2D masking
kv = tl.load(
KV + kv_offset + d_idx[:, None] * e + e_idx[None, :],
mask=(d_mask[:, None] & e_mask[None, :]),
other=0.0,
)
# Compute outer product using element-wise operations
k_v_prod = k[:, None] * v[None, :]
kv = ratio * kv + k_v_prod
# Store KV with 2D masking
tl.store(
KV + kv_offset + d_idx[:, None] * e + e_idx[None, :],
kv.to(KV.dtype.element_ty),
mask=(d_mask[:, None] & e_mask[None, :]),
)
# Compute matrix-vector multiplication using element-wise operations and reduction
o = tl.sum(q[:, None] * kv, axis=0)
# Store output with masking
tl.store(Out + o_offset + e_idx, o.to(Out.dtype.element_ty), mask=e_mask)
def triton_lightning_attn_decode(q, k, v, kv, s):
"""Triton implementation of Lightning Attention decode operation"""
b, h, n, d = q.shape
e = v.shape[-1]
assert n == 1, "Sequence length must be 1 in decode mode"
# Get padded dimensions (power of 2)
d_padded = next_power_of_2(d)
e_padded = next_power_of_2(e)
# Create output tensor (padded)
o_padded = torch.empty(b, h, n, e_padded, dtype=v.dtype, device=v.device)
# Create padded tensors without actually padding the data
q_padded = torch.empty(b, h, n, d_padded, dtype=q.dtype, device=q.device)
k_padded = torch.empty(b, h, n, d_padded, dtype=k.dtype, device=k.device)
v_padded = torch.empty(b, h, n, e_padded, dtype=v.dtype, device=v.device)
kv_padded = torch.empty(
b, h, d_padded, e_padded, dtype=torch.float32, device=kv.device
)
# Copy data to padded tensors
q_padded[..., :d] = q
k_padded[..., :d] = k
v_padded[..., :e] = v
kv_padded[..., :d, :e] = kv
# Launch kernel
grid = (b * h, 1)
_decode_kernel[grid](
q_padded,
k_padded,
v_padded,
kv_padded,
o_padded,
s,
b=b,
h=h,
n=n,
d=d_padded,
d_original=d,
e=e_padded,
e_original=e,
)
# Get unpadded outputs
o = o_padded[..., :e]
kv_out = kv_padded[..., :d, :e]
return o, kv_out
dtype = torch.bfloat16
device = torch.device("cuda")
num_heads = 64
head_dim = 96
seq_len = 1
batch_size = 1
q = torch.randn(batch_size, num_heads, seq_len, head_dim, device=device, dtype=dtype)
k = torch.randn(batch_size, num_heads, seq_len, head_dim, device=device, dtype=dtype)
v = torch.randn(batch_size, num_heads, seq_len, head_dim, device=device, dtype=dtype)
past_kv = torch.randn(batch_size, num_heads, head_dim, head_dim, device=device)
slope = torch.randn(num_heads, 1, 1, device=device)
output_triton, new_kv_triton = triton_lightning_attn_decode(q.clone(), k.clone(), v.clone(), past_kv.clone(), slope.clone())
output_kernel = torch.empty_like(output_triton)
new_kv_kernel = torch.empty_like(new_kv_triton)
lightning_attention_decode(
q.clone(), k.clone(), v.clone(), past_kv.clone(), slope.clone(),
output_kernel, new_kv_kernel
)
print('end')
然后执行 /usr/local/NVIDIA-Nsight-Compute-2024.3/ncu --set full -o lightning_attention_decode_bs=1 python3 test_lighting_attention.py
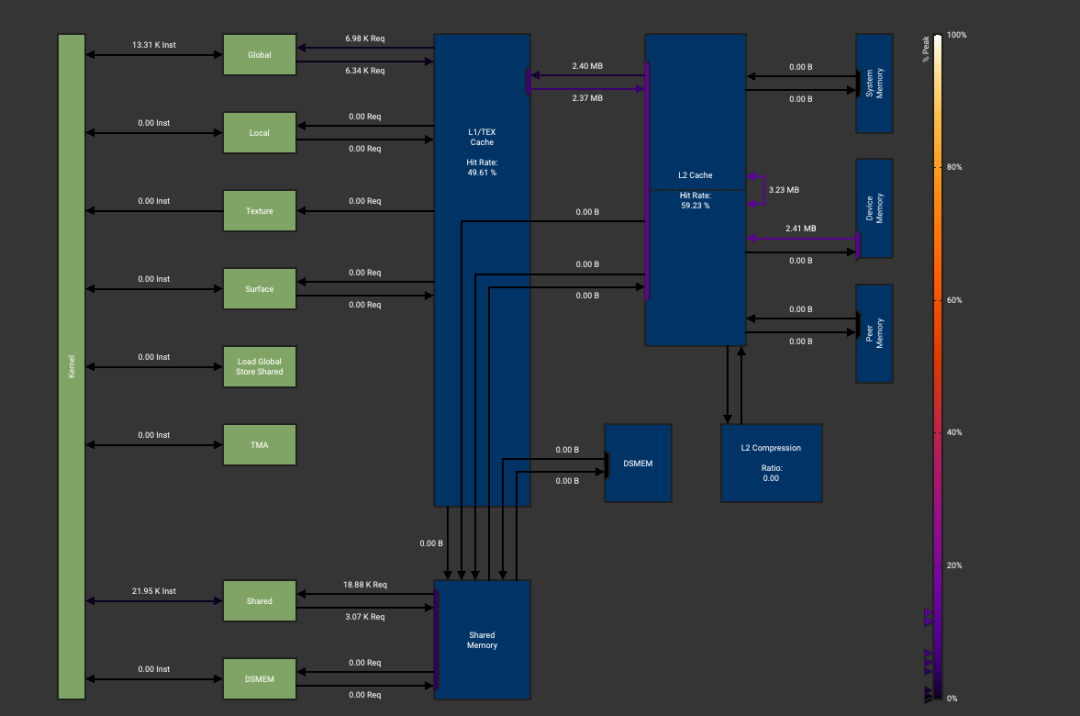
得到ncu文件之后可以重点关注一下Memory Wordload Analysis这一列:
Triton版本:
CUDA版本:
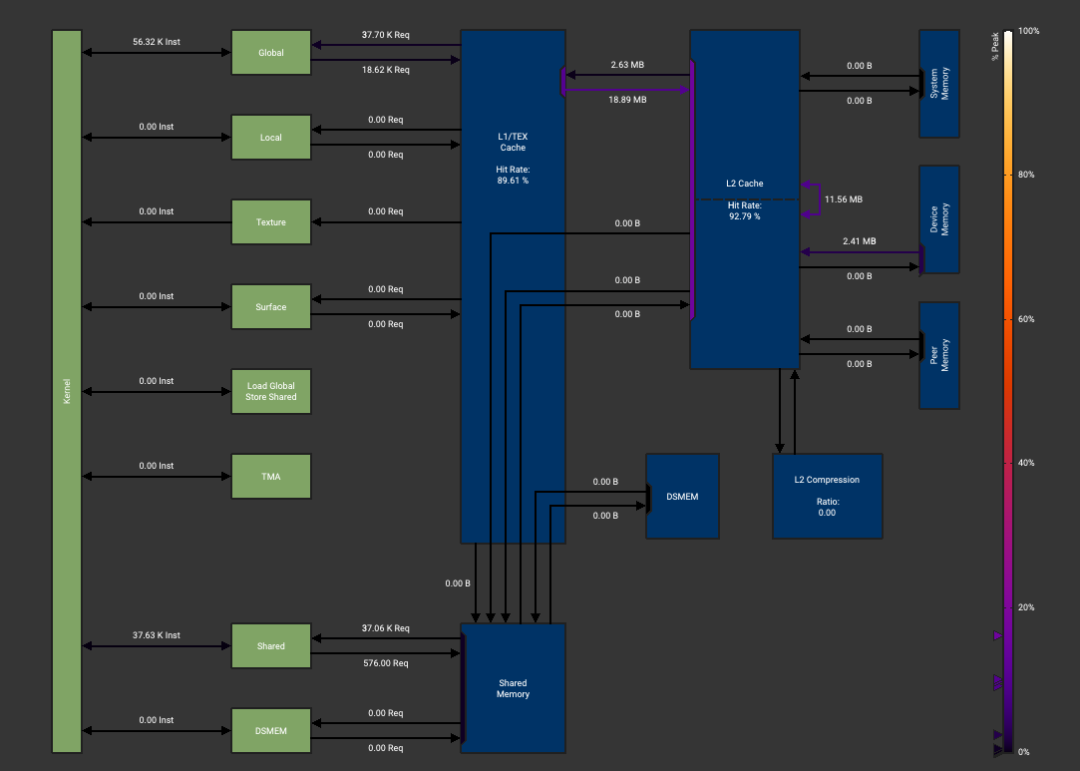
有两个主要区别,首先CUDA版本没有使用Shared Memory加速读取和写入,第二个区别是Triton版本写回全局内存的数据量要小得多。
接下来可以让Cursor辅助我们写一个Shared Memory的版本,把q,k,v,new_kv的计算都放在Shared Memory里面。Cursor确实可以写,但是如果我们不指出是否存在Bank Conflict,它是不会管的。这就导致它实现的第一个Shared Memory版本的kernel执行时间比最开始的全局内存读写版本还要慢4倍,这里我就不贴代码了。接下来需要给Cursor手动解释一下它存在Bank Conflict,主要是计算new_kv_shared的时候存在大量Bank Conflict,我们要求他执行一个padding来避免Bank Conflict,这样Cursor就可以写出看起来正常的代码了。
#define THREADS_PER_BLOCK 128
template<typename T>
__global__ void lightning_attention_decode_kernel(
const T* __restrict__ q, // [b, h, 1, d]
const T* __restrict__ k, // [b, h, 1, d]
const T* __restrict__ v, // [b, h, 1, e]
const float* __restrict__ past_kv, // [b, h, d, e]
const float* __restrict__ slope, // [h, 1, 1]
T* __restrict__ output, // [b, h, 1, e]
float* __restrict__ new_kv, // [b, h, d, e]
const int batch_size,
const int num_heads,
const int dim,
const int embed_dim) {
extern __shared__ char smem[]; // 动态共享内存声明
// 为所有数组在共享内存中分配空间
T* q_shared = reinterpret_cast<T*>(smem);
T* k_shared = reinterpret_cast<T*>(smem + dim * sizeof(T));
T* v_shared = reinterpret_cast<T*>(smem + 2 * dim * sizeof(T));
float* new_kv_shared = reinterpret_cast<float*>(smem + (2 * dim + embed_dim) * sizeof(T));
T* output_shared = reinterpret_cast<T*>(smem + (2 * dim + embed_dim) * sizeof(T) + dim * (embed_dim + 1) * sizeof(float));
const int32_t tid = threadIdx.x;
const int32_t current_head = blockIdx.x;
const int32_t b = current_head / num_heads;
const int32_t h = current_head % num_heads;
if (b >= batch_size) return;
const int32_t qk_offset = b * num_heads * dim + h * dim;
const int32_t v_offset = b * num_heads * embed_dim + h * embed_dim;
const int32_t kv_offset = b * num_heads * dim * embed_dim + h * dim * embed_dim;
for (int d = tid; d < dim; d += blockDim.x) {
q_shared[d] = q[qk_offset + d];
k_shared[d] = k[qk_offset + d];
}
for (int e = tid; e < embed_dim; e += blockDim.x) {
v_shared[e] = v[v_offset + e];
}
__syncthreads();
const float ratio = expf(-1.0f * slope[h]);
for (int d = tid; d < dim; d += blockDim.x) {
T k_val = k_shared[d];
for (int e = 0; e < embed_dim; ++e) {
int past_kv_idx = kv_offset + d * embed_dim + e;
T v_val = v_shared[e];
float new_val = ratio * past_kv[past_kv_idx] + k_val * v_val;
int shared_idx = d * (embed_dim + 1) + e;
new_kv_shared[shared_idx] = new_val;
}
}
__syncthreads();
for (int idx = tid; idx < dim * embed_dim; idx += blockDim.x) {
int d = idx / embed_dim;
int e = idx % embed_dim;
int shared_idx = d * (embed_dim + 1) + e;
int global_idx = kv_offset + idx;
new_kv[global_idx] = new_kv_shared[shared_idx];
}
__syncthreads();
for (int e = tid; e < embed_dim; e += blockDim.x) {
float sum = 0.0f;
for (int d = 0; d < dim; ++d) {
int shared_idx = d * (embed_dim + 1) + e;
sum += q_shared[d] * new_kv_shared[shared_idx];
}
output_shared[e] = static_cast<T>(sum);
}
__syncthreads();
if (tid == 0) {
for (int e = 0; e < embed_dim; ++e) {
output[v_offset + e] = output_shared[e];
}
}
}
但是当我们测试Benchmark的时候发现这个版本的速度虽然在bs<=4的时候比Triton快不少,但是当继续增大bs的时候速度越来越慢,是Triton是2-3倍执行时间。
继续打开NCU的Memory Wordload Analysis,我们发现这次它抛出了一个写Global Memory不连续导致性能降低的问题。

把这个结果反馈给Cursor,Cursor现在可以知道主要问题是写new_kv的时候内部循环·for (int e = 0; e < embed_dim; ++e)·导致线程在访问全局内存时stride太大,然后内存没有合并访问,且每个线程需要写入多次全局内存,增加了内存事务数。这也是我们看到这个kernel写全局内存的时候比Triton多了几倍的原因。知道原因之后Cursor就可以改成正确的代码了。代码如下:
#define THREADS_PER_BLOCK 128
template<typename T>
__global__ void lightning_attention_decode_kernel(
const T* __restrict__ q, // [b, h, 1, d]
const T* __restrict__ k, // [b, h, 1, d]
const T* __restrict__ v, // [b, h, 1, e]
const float* __restrict__ past_kv, // [b, h, d, e]
const float* __restrict__ slope, // [h, 1, 1]
T* __restrict__ output, // [b, h, 1, e]
float* __restrict__ new_kv, // [b, h, d, e]
const int batch_size,
const int num_heads,
const int dim,
const int embed_dim) {
extern __shared__ char smem[]; // 动态共享内存声明
// 为所有数组在共享内存中分配空间
T* q_shared = reinterpret_cast<T*>(smem);
T* k_shared = reinterpret_cast<T*>(smem + dim * sizeof(T));
T* v_shared = reinterpret_cast<T*>(smem + 2 * dim * sizeof(T));
float* new_kv_shared = reinterpret_cast<float*>(smem + (2 * dim + embed_dim) * sizeof(T));
T* output_shared = reinterpret_cast<T*>(smem + (2 * dim + embed_dim) * sizeof(T) + dim * (embed_dim + 1) * sizeof(float));
const int32_t tid = threadIdx.x;
const int32_t current_head = blockIdx.x;
const int32_t b = current_head / num_heads;
const int32_t h = current_head % num_heads;
if (b >= batch_size) return;
const int32_t qk_offset = b * num_heads * dim + h * dim;
const int32_t v_offset = b * num_heads * embed_dim + h * embed_dim;
const int32_t kv_offset = b * num_heads * dim * embed_dim + h * dim * embed_dim;
for (int d = tid; d < dim; d += blockDim.x) {
q_shared[d] = q[qk_offset + d];
k_shared[d] = k[qk_offset + d];
}
for (int e = tid; e < embed_dim; e += blockDim.x) {
v_shared[e] = v[v_offset + e];
}
__syncthreads();
const float ratio = expf(-1.0f * slope[h]);
for (int d = tid; d < dim; d += blockDim.x) {
T k_val = k_shared[d];
for (int e = 0; e < embed_dim; ++e) {
int past_kv_idx = kv_offset + d * embed_dim + e;
T v_val = v_shared[e];
float new_val = ratio * past_kv[past_kv_idx] + k_val * v_val;
int shared_idx = d * (embed_dim + 1) + e;
new_kv_shared[shared_idx] = new_val;
}
}
__syncthreads();
for (int idx = tid; idx < dim * embed_dim; idx += blockDim.x) {
int d = idx / embed_dim;
int e = idx % embed_dim;
int shared_idx = d * (embed_dim + 1) + e;
int global_idx = kv_offset + idx;
new_kv[global_idx] = new_kv_shared[shared_idx];
}
__syncthreads();
for (int e = tid; e < embed_dim; e += blockDim.x) {
float sum = 0.0f;
for (int d = 0; d < dim; ++d) {
int shared_idx = d * (embed_dim + 1) + e;
sum += q_shared[d] * new_kv_shared[shared_idx];
}
output_shared[e] = static_cast<T>(sum);
}
__syncthreads();
if (tid == 0) {
for (int e = 0; e < embed_dim; ++e) {
output[v_offset + e] = output_shared[e];
}
}
}
这里重构了new_kv的内存访问模式,让相邻线程访问连续的内存地址,达到内存合并访问的目的。
这个kernel还有很多优化空间,例如一个Block中实际上还有一个warp没有工作,因为一个Block是128个线程,但是dim=96,所以可以优化成一个warp处理一行这种版本。此外,我们没有使用向量化读取进一步降低内存事务等等。
不过从我kernel Micro Benchmark以及end2end的Lighting Attention模块Benchmark结果来看,它已经超越了Triton的优化版本,在各个Batch下都取得了优势。
0x3. 总结
基于 MiniMax Lighting Attention Decode 算子演示了下Cursor Claude-sonnet-3.5-20241022这种最先进的大模型目前写CUDA底层优化的限制,以及我们如果要使用这种工具应该怎么人工给他一些反馈,让它可以真正的正确工作起来。不要轻易相信AI生成的任何代码,特别是涉及到优化的代码。
(文:GiantPandaCV)