

Z Highlights
-
最佳的小模型公司是大型实验室,这不是我之前会想到的,开源的长尾会成为小模型。
-
今天大多数人构建的Agent擅长遵循指令,但不太擅长从你那里提取指令。
-
OpenAI也推出了MLEbench,专注于机器学习研究和自举方法,对研究人员来说这意味着可以实现自己工作的自动化,那将是加速曲线中的一个关键拐点。
-
在人工智能或机器学习领域,很多公司都在争夺如何提高推理(即模型的推理能力)效率和性能的竞争。
人工智能工程:崛起与影响
Alessio Fanelli:大家好,欢迎来到Latent Space播客。我是Alessio,Decibel Partners的合伙人兼首席技术官,今天我和我的搭档SWYX一起迎来了第100期节目。
SWYX:耶,我们非常高兴,大家一直跟随我们走过了这段旅程。你对100期有什么感想?
Alessio Fanelli: 我们已经做了将近两年了,经历了四个不同的工作室,发生了很多变化。刚开始的时候做过一次“闪电回答”,但我们并不喜欢,所以尝试改变问题。
SWYX: 答案是cursor和perplexity。
Alessio Fanelli: 我喜欢MidJourney。但你真的不喜欢其他东西吗?比如,有什么独特的东西吗?,我们也做了更多研究驱动的内容。我们有3DAO,还有Jeremy Howard,还有更多类似的人。我们明年也想做更多类似的内容,比如邀请一些Gemini的人,无论是研究还是应用方面的人。但这段时间真的很有趣。我们一开始并不是开玩笑,我们当时只是觉得,哦,我们应该做个播客。我们抓住了正确的浪潮,显然是这样。你写的《AI工程师的崛起》那篇文章让人们聚集在一起,然后就有了AI工程师峰会。所以当我看到我们的增长图表时,它有点像整个AI工程行业的缩影,即使我们不做太多事情,我们也会继续增长,因为现在有越来越多的AI工程师。你预料到这种增长了吗?还是你觉得AI工程师这个概念需要更长时间才能像今天这样被大家讨论?
SWYX: 所以,我们成功的标志是Gartner现在把它放在了炒作曲线的顶端。我没有预料到会达到这个程度。我知道当我提出这个概念时我是对的,因为我花了两个月的时间去研究。你知道的,我不知道它会发生得这么快,显然我也有可能错。但,大多数人已经接受了这个概念。Hacker News讨厌它,这是个好兆头。而已经有足够多的人定义了它,GitHub在推出GitHub Models时,这是Hugging Face的克隆版,他们把AI工程师放在了横幅上,放在最显眼的位置。所以它已经成为一个有意义且有用的定义了。人们正在试图弄清楚它的边界在哪里。这就是六月份世界博览会上发生的所谓“幕后戏剧”的原因。因为有很多人怀疑或质疑机器学习工程在哪里结束,AI工程从哪里开始。这是一个有用的辩论。在某种程度上,我其实也预料到了这一点。所以我故意没有给出一个明确的定义,因为大多数成功的定义都是必然不完整的,而且实际上有不同的观点是有用的,你不需要从一开始就定义一切。
Latent Space直播与人工智能会议
Alessio Fanelli: 我在AWS re:Invent上,排队参加AI工程讲座的人非常多,应用AI之类的讲座,排队的人有几百个。这就是让我明白的原因。对吧?就像你说的,嘿,你其实不需要博士学位,只需要用模型就行了。然后我们可能会讨论一些你作为工程师在早期文章中遇到的盲点。我们在Substack上也有Ilya的帖子,但这两年真不可思议。
SWYX: 我试图把会议看作是新闻,NeurIPS大概有16,000到17,000人参加。我们在那里举办的Latent Space Live活动有950人报名。AI世界,机器学习世界仍然非常注重研究。这是应该的,因为机器学习还处于研究阶段。但随着整个领域进入生产应用,这个比例会反转,工程会变得更加重要。所以至少工程应该和研究的地位相当,即使它永远不会像研究那样有威望,因为最终你只是在操作API之类的。包装GPTs,但会有越来越多的堆栈和艺术考量。这就是我们为播客、会议以及我做的所有事情所关注的焦点。我们会讨论这里适用的趋势。这很奇怪。所以,就像,既要跟上研究,又不是研究员,然后把研究应用到生产应用中。
所以,人们总是问我,为什么你要关注NeurIPS?这是一个机器学习研究会议,我说,我们不会理解所有的东西,或者复现每一篇论文,但这里发现的东西最终会进入生产应用,你希望如此。然后当我和研究员们交谈时,他们其实非常兴奋,因为他们说,哦,你们真的关心这些东西如何进入生产应用,这正是他们真正想要的。成功的衡量标准以前只是同行评审,对吧?在他们的学术评审会议上得到7分或8分,另外引用次数是一个指标,但钱是更好的指标。
Alessio Fanelli: 直播时大约有2,200人?
SWYX: 直播时有2,200人。
Alessio Fanelli: 我尽力去调解,但与Jonathan和Dylan面对面时,现场的气氛比YouTube聊天要热烈得多。
SWYX: 我实际上也是为了应对我在学术会议上所感知到的缺陷而创建了Latent Space现场活动。这不是NeurIPS特有的,ICML、NeurIPS都是这样。基本上,它非常面向博士生市场,就业市场,对吧?基本上所有人都在那里宣传他们的研究和技能,找工作。然后显然所有的公司都去那里招聘他们。这对个体研究员来说很好,但对于去那里获取信息的人来说并不好,因为你必须读懂字里行间,带入大量背景才能理解每一篇论文。因此,缺失的东西实际上是我最终所做的,即逐个领域回顾年度最佳,调查该领域的进展。
像NeurIPS有一个职位论文轨道,ICML有一个基准数据集轨道,这些都是解决这个问题的方法。每个会议也总是有最后一天的研讨会,提供更多的概述,但他们并没有特别被要求这样做。组织会议的关键是找到好的演讲者,并给他们正确的提示。然后他们就会去做,而且做得非常好。所以Sarah在初创公司提示方面做得非常出色。我不能一一列举所有人,但我们做了2024年最佳初创公司、视觉、开放模型、后Transformer、合成数据、小模型和代理。然后最后一个,显然是最受关注的辩论。那场辩论非常尴尬。我非常感谢John Franco,他站出来挑战Dylan。因为Dylan说他支持扩展。所有在AI领域的人都支持扩展,对吧?所以你需要有人公开说,不,我们已经遇到瓶颈期了。所以这意味着你在说Sam Altman错了。你在说,其他人都错了。这有帮助的是,就在Ilya上台前一天,他说预训练已经碰壁了。数据也碰壁了。所以实际上Jonathan最终赢了,然后Ilya支持了那个说法,然后Noam Brown在最后一天也支持了那个说法。
所以这很有趣,共识是,我们还没有完成扩展,你应该相信更好的。然后,连续四天有Sepp Hochreiter,他是LSTM的创造者,还有大家最喜欢的AI OG,Juergen Schmidhuber。他说,我们在预训练中碰壁了,或者我们遇到了另一种瓶颈。然后我们有,John Frankel、Ilya,然后Noam Brown都在说类似的话,我们在大规模预训练模型的现状中碰壁了,我们需要新的东西。
显然,对人们来说,新的东西要么是推理时间计算,要么是测试时间计算。集体术语是推理时间,这很有道理,因为测试时间意味着有很强的预训练偏见,意味着运行推理的唯一原因是测试你的模型。这不是真的。是的。所以,我同意OpenAI似乎已经采用了这个术语,或者社区似乎已经采用了ITC而不是TTC。这很有道理,因为现在我们关心推理,甚至到了计算最优性。我其实采访了这篇论文的作者,他回顾了Chinchilla论文。Chinchilla论文是关于计算最优训练的,但里面没有提到的是,它是预训练计算最优训练。一旦你开始关心推理计算最优训练,你就会有不同的Scaling law。这是我们去年不知道的。
Alessio Fanelli: John也是“注意力即一切”的支持者,他和Sasha有过争论,所以我很好奇他是否仍然相信扩展。
SWYX: 我告诉他在这场辩论中扮演一个角色,对吧?他仍然相信我们可以进一步扩展,他只是假设了一个角色,愿意在这场辩论中扮演这个角色,因此对他来说,能够假设一个他不相信的立场并且仍然赢得辩论,值得更多的赞扬。
Alessio Fanelli: 赢得了Dylan。你想快速浏览一下这些事情吗,比如Sarah的演讲?
竞争激烈的人工智能领域
SWYX: 我们不能逐个浏览每个人的幻灯片,但提取了一些我们要讨论的内容。我们会在这个频道上发布2024年最佳内容,希望人们能从我们演讲者的工作中受益。这些都是很好的幻灯片,我一直在寻找一些年终总结。
这个领域进展很大,2023年LMSYS的最大ELO(ZP注:LMSYS是一个专注于LLMs及其系统基础设施的非营利组织,全称为Large Model Systems Organization。ELOs是LMSYS在其Chatbot Arena 平台上使用的ELO评分系统,用于评估和比较不同LLMs的性能)曾经是1200,现在每个人的ELO至少在1275。这是Gemini、ChatGPT、Grok、o1等的竞争,当然这是一个竞争非常激烈的比赛,有多个Frontier Labs在竞争。但现在有一个明确的Tier 0 Frontier,然后是Tier 1,其他一切都在Tier 0之间,其中竞争非常激烈。
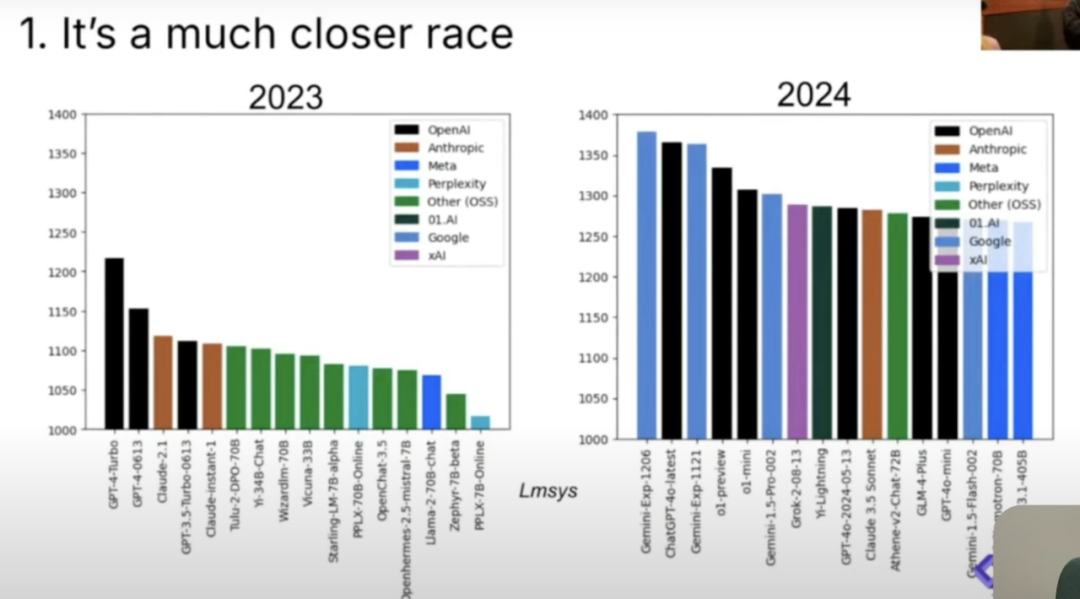
图片来源:Latent Space
现在是Gemini、Anthropic和OpenAI之间的三方竞争。人们仍然对xAI抱有希望,可能是因为他们的API推出得很慢,所以在这些指标中并没有包括它。作为一个也做图表的人,xAI总是被忽视,因为他们与基准测试的人合作得不好。所以这是一个小趣闻,解释了为什么xAI总是被忽视。
另一个是市场份额。这些是Sarah的幻灯片,我们在屏幕上展示了它。它的市场份额从非常依赖OpenAI开始,这些数字和估计来自Ramp。2023年12月,基本上是GPT 3.5和GPT 4占95%的生产流量。如果你将其与我们在Langchain节目中问Harrison Chase的内容进行关联,那是正确的。Claude 3在今年3月推出的,Claude 3.5 Sonnet是在6月推出的,你可以开始看到市场份额向Anthropic转移,非常迅速。最近是Gemini,所以如果我稍微向下滚动一下,这是一个更近期的数据集,Ramp的数据集截至2024年9月,Gemini基本上在低端发起了价格战,Gemini Flash基本上是个人使用免费。人们不理解免费层的含义,它每天大约有十亿个Token,除非你试图滥用它,否则你几乎无法耗尽Gemini的免费层。他们真的在努力让你使用它,他们知道自己处于第三或第四的位置,具体取决于你如何计算,因此他们首先针对低端市场,然后也许稍后再考虑高端市场。但根据Open Router的说法,Gemini Flash现在占他们Open Router请求的50%。显然,这些是小而便宜的请求,聪明的请求显然仍然会去OpenAI,但这是市场上非常大的变化。基本上在2023年到2024年之间,OpenAI的市场份额从95%下降到合理的50%到75%之间。
Alessio Fanelli: 我很好奇Ramp如何对模型进行归因,如果是API。
SWYX: 这是信用卡支出。
Alessio Fanelli: 好吧,但所有的信用卡并没有说明,也许他们在做费用时上传PDF。但先前谈到的Gemini行为是有道理的。这是我2024年主要的收获之一,即最佳的小模型公司是大型实验室,这不是我之前会想到的,开源的长尾会成为小模型。
SWYX: 这里讨论的小模型有不同的大小。因此,Gemini的小模型是AB,而mini我们不知道小模型的大小,但可能在个位数或两位数之间。开源社区已经专注于1到3B的规模,可能是0.5B,那是Moon Dream,如果那对你来说是小的,那很好。我们现在有一个范围,可能是1到5B,我甚至会把它放在高端,这包括Gemini的Gemma,但也包括Apple Foundation模型,Apple Foundation是3B。
Alessio Fanelli: 这很好。一开始“小”只是意味着便宜,但今天“小”实际上是一个更细致的讨论,之前人们并没有真正进行这样的讨论。
SWYX: 这是Sarah的幻灯片,我有点不同意她的观点。她指向了Scale SEAL排行榜。我在NeurIPS上交谈的研究员们对此持积极态度,因为基本上你需要私有测试集来防止污染。Scale AI是今年为数不多的几家真正努力做出可信私有测试集排行榜的公司之一。
Llama 405B在与Gemini和GPT 4o的比较中表现良好。一个如此庞大的开源模型在这些指标中表现良好是件好事。但任何将405B投入生产应用的人都会告诉你,如果你稍微向下滚动一下Artificial Analysis数字,该模型在推理时非常慢且非常昂贵。他的规模甚至超出了单个H100节点的处理能力,虽然Cerebras公司宣称可以在他们的超大芯片上承载405B,但如果你需要对其进行任何定制化开发,你仍然会受到限制。
那么,405B真的那么重要吗?业界的普遍观点是,405B模型主要被用作“教师模型”,用以提炼出更小的模型,甚至Meta也在这样做。当Llama 3.3推出时,仅发布了70B,这表明他们使用405B来提炼70B。
至于开源社区是否能够跟上这一趋势,开源产业的倡导者们热衷于强调开源与闭源解决方案之间的差距正在缩小。然而,我对此持有保留态度。他们离o1差距正在扩大,有许多才华横溢的人在努力缩小这个差距,他们应该这样做,我也期待他们的成功。但你不能用一个接近100的饱和图表说开源和闭源的差距在缩小。当然它会缩小,因为你接近100了。所以这种观点是荒谬的。真正的问题在于,在那些至关重要的指标上,开源社区是否正在迎头赶上?对于o1这一指标,开源社区可能还需要一段时间才能达到与闭源解决方案相媲美的水平,这真的取决于开源的人们是否能找到匹配的方法。
Alessio Fanelli: 推理时间计算对开源不利,因为Doc可以在训练时间上捐赠计算能力,但在推理时间上却无法捐赠。因此,实际上开源很难在大型商业模型转变中跟上。我不知道这对GPU云意味着什么,但显然大型实验室有很多优势,因为这不是你放入计算机的静态产物。你仍然在这样做,但你还在进行大量的计算推理。
SWYX:Llama 4将是以推理为导向的。我们与Thomas Shalom进行了交谈,感谢他让这一集得以成型,时机非常好。实际上,我在NeurIPS上联系了Meta的AI负责人,我们会为Llama4协调一些事情。
Alessio Fanelli: 我们的朋友Clari刚刚加入Meta,负责商业Agent方面的工作。所以我肯定我们会在新年里邀请她。
SWYX: 我对商业模式转变的评论是,这非常有趣。显然,OpenAI希望为他们的融资筹集超过66亿美元,他们希望筹集更多,但没有成功。这意味着,实际上,GPT 5不会推出,这本应是一个更大的预训练模型,应该有更多的前期资金。相反,我们正在将固定成本转化为可变成本,并有效地将其转嫁给客户。这样做更容易获得利润,因为你可以直接将其归因于“哦,你使用得越多,你就支付更多的成本”,我只需在其中加上一个利润。因此,这让你能够控制你的毛利率,并相应地调整你的支出或推理支出。这真的很有趣,这种推理范式的变化正好发生在预训练资金环境基本上枯竭的时候。VC们其实很了解研究,所以他们可能已经注意到了这一点,但这很有趣。
Alessio Fanelli: 我回顾了去年的年度回顾,最大的事情是Mixtral价格战。现在几乎没有地方可去,Gemini Flash几乎是免费提供的,所以这是实验室生成更多收入并传递下去的好方法。
SWYX: 他们会继续下去,2,000美元的ChatGPT会到来。
Alessio Fanelli: 我完全同意。明年我做的第一件事就是注册Devin,注册专业版ChatGPT,只是想看看每月花费1000美元的AI是什么样子。
SWYX: 如果你的工作是至少AI内容创作者、风险投资者,或者某个需要跟上事物的人,你应该已经在这些东西上花费了1,000美元,显然,花费很容易,使用很难。你必须真正使用它。好消息是,谷歌现在让你免费做很多事情,因此他们刚刚推出的Deep Research使用了大量推理,而在预览期间是免费的。
Alessio Fanelli: 他们需要把它放到Lindy里。我最近一直在用Lindy,构建了一些东西,因为我们有了工作流。我喜欢这个新东西,它相当不错。我甚至做了一个电话助手。
SWYX: 他们刚刚推出了Lindy Voice。
Alessio Fanelli: 一旦他们获得了先进的语音能力,就像今天的语音转文本一样,那么它在预订和类似的事情上就会很好。所以我有一个会议准备工具,它很好用。
SWYX: 好的,我们已经覆盖了很多内容。我们将在单独的节目中讨论各个演讲。我不想在这些事情上花太多时间,但可以说每个领域都有很多进展。
我们讨论了视觉。基本上这些都是观众投票选出他们想要的内容的。然后我邀请了每个领域我能找到的最好的人,尤其是Agent方面。Graham,我在维也纳的ICML上与他交谈过,他目前仍然是第一名。保持在SWE基准的第一名是非常困难的。他对Agent有很好的看法,我会为大家强调这一点。每个人都在说2025年是Agent的年份,就像去年说的那样,但他对解决Agent的前沿问题有八个方面的看法,我会强调那次演讲。
Alessio Fanelli: 第六个问题是Agent如何更多地了解环境,这对我们来说也非常有趣。如何将Agent放入企业,而企业中的大多数事情从未公开过。很多工具,比如代码库之类的。
SWYX: 索引和RAG。
Alessio Fanelli: 但更像是你无法RAG,因为事情没有文档化,但人们知道它们是如何做的。因此,几乎有一种“哦”。
SWYX: 机构知识(institutional knowledge)。
Alessio Fanelli: 乏味的事是商业流程提取。实际上,如何理解这些事情是如何完成的。今天大多数人构建的Agent擅长遵循指令,但不太擅长从你那里提取指令。
SWYX: 这将是一个巨大的突破。简单提一下Jeff Dean的事情,这很有趣。重点是,如何使用机器学习来优化系统,而不仅仅是专注于机器学习去做其他事情。我们之前和RWKB的Eugene在播客上聊过,他正在和Fetterless AI做很多这方面的工作。
SWYX: 每个人都在做。这是常态。我对它的成本有点不安,因为它确实在每次调用中使用了更多的GPU,但因为每个人都如此热衷于快速推理,所以这很有意义。
Alessio Fanelli: 确实Jeff很棒。
合成数据与未来趋势
SWYX:Jeff的演讲更多的是关于谷歌如何处理机器学习,以及如何使用机器学习来设计系统,然后系统反馈到机器学习中。这与Lubna关于合成数据的演讲有关,基本上是人类在AI研究或生产应用中的引导故事。她的演讲是关于合成数据的,具体是2024年合成数据在预训练、后训练和评估方面的增长。Jeff随后也将其扩展到芯片设计,因此他花了很多时间谈论芯片,而我们大多数观众都在想,“我们不做硬件,伙计们,你们很棒,TPU很棒。我们会买TPU。”
Alessio Fanelli: 然后还有Ilya的演讲。我们还有一篇与之相关的文章,这只是Latent Space支持者的额外内容,因为他们没有得到任何东西。然后我想要一种更高频率的方式来写东西。
基本上我们现在有了对Ilya所看到的东西的答案,现在我们不仅知晓了Ilya在2014年的所见所感,也了解了他在2024年的观察和发现。他给出了一些线索,同时对于2023年的发现也给出了一些模糊的暗示。
还有2016年,因为Elon和OpenAI的诉讼,OpenAI发布了Sam的个人短信给Siobhan、Zelis之类的。我们同样获得了Ilya的邮件,这些邮件揭示了我们在OpenAI内部所见证的一切,以及为何我们坚信需要扩展GPU资源的紧迫性。在2016年写下这些内容是非常有先见之明的。Ilya的洞察力表明,他与Greg在推动OpenAI的扩张上发挥了关键作用。即便在他们沉迷于DOTA游戏的同时,他们也坚定地宣称:“不,我们清楚地看到了这里的路径。”
Alessio Fanelli: 是的。有趣的是,他们甚至提到,我们只能在1对1的DOTA上训练,我们需要在5对5上训练,这需要太多的GPU。
SWYX: 至少对我来说,我可以为自己发言,我没有看到从DOTA到我们今天所处的路径。即使你问他们,他们也不一定会画出一条直线。
Alessio Fanelli: 我绝对同意,但这几乎是强化学习的整个理念。我们与Nathan在他的播客中讨论过,强化学习可以在特定事情上变得非常出色,但你不能真正做到更广泛的概括。语言模型正好相反,你将所有这些数据扔给它们并扩展它们,但然后你真的需要在特定任务上进行微调。稍后我们会讨论OpenAI的强化学习微调公告等等。但“规模就是一切”将是人们对他的记忆。
也许要澄清一下人们喜欢推的“预训练结束了”这一点。演讲的重点是,每个人都在扩展这些芯片,扩展计算能力,但第二个成分——数据并没有以同样的速度扩展。因此,预训练并不是结束,而是我们到达这里的方式不会让我们到达那里。在他的电子邮件中,他预测每两年增长10倍或类似的东西,现在可能是,你可以再次将芯片扩展10倍。
SWYX: 是每年10倍吗?我不知道。
Alessio Fanelli: 确实如此,摩尔定律是2倍,所以远远快于这个速度。我喜欢用化石燃料来类比。有点像,背景token的事情。所以OpenAI的强化微调基本上是,你不是在数据上微调,而是在奖励模型上微调。所以基本上,它不是数据驱动的,而是任务驱动的。人们有任务要做,他们并没有很多数据,所以我很好奇这将如何改变人们的微调方式,因为这就是人们遇到的问题。人们会说,“哦,你可以微调Llama,”然后问,“好吧,我在哪里可以找到数据来微调它呢?”所以很高兴我们在推进这个事情。我很喜欢他的一个图表,显示大脑质量和身体质量的关系,基本上是哺乳动物的规模线性增长,像大脑和身体大小,然后人类几乎打破了这个斜率。因此,可能哺乳动物的斜率就像预训练的斜率,而后训练的斜率就像人类的斜率。
SWYX: 我想知道Ilya的SSI的y轴是什么。我们会试着邀请他们。
Alessio Fanelli: Ilya,如果你在听,你随时欢迎来这里。agent、合成数据、推理、计算等,所有这些都很有趣。
SWYX: 他没有透露任何方向性指标。
Alessio Fanelli: 是的。还有其他新的亮点吗?
SWYX: 相对而言,工作量更多。哦,顺便说一下,我需要宣传一下,我的朋友Yi做了一个很好的小东西。
Alessio Fanelli: 那真的很好。
SWYX: 她称之为2024年必读论文的清单,所以我在NeurIPS上列出了一些,结果大家都很喜欢,因为人们渴望对每篇论文进行小指导和可视化。因此,这真的很不错,我们得到了这个。
Alessio Fanelli: 我们应该为每年做一本Latent Space书吗?
SWYX: 我考虑过做一本书。
Alessio Fanelli: 好的,把它放进去。Will,顺便说一下,我们还没有介绍你。
SWYX: 我看到的一个有趣的事情,是关于Agent共谋的论文。这是一篇关于Secret Collusion的论文,关于AI Agent之间的秘密共谋,通过生成的文本进行多Agent欺骗。我试图去NeurIPS寻找这些类型的论文,因为今年NeurIPS有一个抽奖系统,很多人实际上甚至不去买票,因为他们只是去参加边会。而且,去的人最终会围着最受欢迎的论文,这些论文你在到达欧洲之前就已经知道并阅读过。因此,你去那里唯一的理由是与论文作者交谈,然而还有大约10,000篇其他论文,这是人们在这一年中所做的工作,他们因某种原因未能获得关注。这就是其中之一,位于最后面。这是一篇DeepMind的论文,实际上专注于AI Agent之间的共谋,通过在他们生成的文本中隐藏消息。
秘密共谋就是这样。一个非常简单的例子是每个单词的第一个字母,如果你挑出来,会得到与之不同的消息。但我一直强调的是,对于LLMs来说,我们是从左到右阅读的,而LLMs可以上下、横向、随机字符顺序阅读,对它们来说是一样的。因此,如果我们有自我驱动的LLMs,试图合作征服地球,这将是它们的做法。它们在我们生成的消息中传播消息。他开发了一个共谋的扩展法则,他标记了我现在在屏幕上展示的现象。例如,对于Cipher编码,GPT-2、Llama 2、Mixtral、GPT 3.5零能力和GPT 4的突然出现。这是人们寻找的Jason Way类型的出现特性。这篇论文突出的地方是,他开发了共谋的基准,并且他还关注了Shelling Point共谋,这几乎没有协调。为了达成编码格式的协议,你需要对其有一些协议,但Shelling Point意味着几乎没有协调。例如,如果我问某人,唯一给你的消息是“在纽约见我”,而你不知道何时何地,你可能会在Grand Central Station见我。Grand Central Station是一个Shelling Point,可能在白天的某个地方。因此,Shelling Points是我们讨论过的常见解码方法。在未来某个时刻,当我们担心对齐时,这并不有趣,但DeepMind已经在思考这个问题,这很有趣。
Alessio Fanelli: 觉得这是NeurIPS最难的事情之一就是长尾。
SWYX: 我发现了一个非常长尾的定价专家,我打算在播客中介绍他。他来自Nvidia,研究了语言模型的最佳定价。这基本上是一篇在NeurIPS上的计量经济学论文,当其他人都在谈论GPU时,这个有GPU的家伙却在谈论经济学。
Alessio Fanelli: 是的。
SWYX: 这算是有趣的一点。我看到的更广泛的趋势是,NeurIPS上的模型论文基本上已经死了,没人再真正展示模型了,只有数据集,因为所有的研究生都在做这个。所以有一个数据集的分会场,然后我发现其实不需要一个数据集的分会场,因为每篇论文都是数据集论文。因此,数据集和基准测试实际上是同一事物的两个方面。所以,如果你是研究生,你就会在这方面工作,然后人们就会在模型中挑选他们喜欢的模型,然后使用它,这就是它的发展方式。去年有像Haotian这样的人,他在做lava,就是把Llama和视觉结合在一起,然后显然xAI雇佣了他,他把视觉添加到了Grok,现在他是视觉Grok的专家。今年没有这样的情况。
Alessio Fanelli: 去年最受欢迎的口头报告是什么?Mixed Monarch是最受欢迎的。
SWYX: 我需要查一下。
Alessio Fanelli: 如果没有什么印象,那也是一种回答。但去年有很多关于进一步模型和不同架构的兴趣。
SWYX: 今年的口头报告选择不是很好,或者说这可能只是突显了我对论文看法的变化。在我看来,今年关于数据集的两篇最佳论文是datacomp和fineweb。这两篇实际上是工业上使用的论文,但没有被突出展示。另外,DCLM得到了关注,而fineweb甚至没有得到关注,所以选择是不同的。
但有一件事引起了很多讨论,很多人都在争论关于The Road Less Scheduled。今年在机器学习社区中,关于优化学习率等相关事物的讨论很多。大多数我问过的大型实验室的人说这很不错,但并不重要。我不知道,但这是一个被讨论得非常热门的话题。
Alessio Fanelli: 关于AI的四个战争(War)总结,也许我们可以快速开始,你想从数据开始吗?
SWYX: 提醒大家,这是我们今年早些时候做的四个部分之一,左边是好战者,右边是记者、作家、艺术家,基本上是任何拥有知识产权的人,比如《纽约时报》、Stack Overflow、Reddit、Getty、Sarah Silverman、George RR Martin。

图片来源:Latent Space
今年我们可以把Scarlett Johansson也加入到这一方。所以任何起诉OpenAI的人,基本上,我实际上想要获取所有诉讼的快照,我相信某些律师可以做到。这是数据质量战争。在右边,我们有合成数据的人,我们谈到了Lubna的演讲,真的展示了合成数据在今年的发展。Scale AI和合成数据社区之间有一点争斗,因为Scale AI发表了一篇论文,声称合成数据不起作用,惊喜,Scale AI是非合成数据的领先供应商。
Alessio Fanelli: 只有无笼和标注的数据才有用。
SWYX: 所以这里有一些争论,但至少合成数据的理由在Lubna的演讲中是有意义的。我不知道你对此有什么看法。
Alessio Fanelli: 回到强化微调,这会稍微改变人们的看法。今天人们主要使用合成数据,主要是为了蒸馏和从大模型中微调小模型。我对前沿实验室如何使用它并不太了解,除了像Apple做的重新表述网络的事情。但这会很有用。这是否能让我们迈出下一步,可能还要待定。人们喜欢谈论数据,因为这就像是一个GPU贫民的事情。合成数据是人们可以做的事情,所以他们对它的看法更有主见,而不是关于优化器的东西,因为他们并不真正参与。
人工智能的法律与伦理问题
SWYX: 合成数据的推理有一个角度。今年我们在论文俱乐部中讨论了这系列论文,基本上帮助你合成推理步骤,或者至少从验证者那里提炼推理步骤。如果你看看他们发布或宣布的OpenAI RFT API,基本上他们要求你提交评分者,或者从预设的评分者列表中选择,这感觉像是为他们创建有效的合成数据,以便微调推理路径。因此,这是另一个开始有意义的角度。
基本上所有的数据质量战争在音乐产业、报纸出版产业或教科书产业与大型实验室之间,都是在预训练时代。在新的推理时代,没人对所有的推理有任何问题,尤其是因为它都是数学和科学导向的,配有非常合理的评分者。更有趣的下一步是它如何超越STEM。
我们已经在AI新闻上使用o1一段时间了,在摘要、创意写作和遵循指令方面,它被低估了。我开始在Latent Space介绍歌曲中使用o1,尽管我们后来取消了介绍歌曲,但它在写歌词方面非常出色。o1 Pro的一个演示是Noom展示的,你可以写出整整一段或三段没有字母A的内容。在任何一种token,甚至不是token级别的操作和计数以及遵循指令方面,它非常强大。因此,当我要求它押韵并创作歌曲时,它会比以前的模型做得更好,它在创意写作方面被低估了。
Alessio Fanelli: 在法庭上,他们可能会提出一些辩护理由,尽管他们并未向我们展示o1的思维过程,但他们希望我们了解,他们正因使用其他出版商的数据而面临法律诉讼。然而,他们同时又主张,他人不应使用他们的数据来训练模型。这种情况确实令人好奇,我对于案件的进展和他们如何自圆其说充满了疑问。
SWYX: OpenAI有很多方法可以惩罚人们,而不需要把他们告上法庭。他们已经禁止了字节跳动,因为字节跳动提炼了他们的信息,所以任何被发现提炼思维链的人将被禁止继续使用API,这没什么大不了的。我甚至认为这根本不是问题,思维链是相当隐蔽的,你必须非常努力才能让它泄露,即使它泄露了思维链,你也不知道它是否是重写的。因此,这里关注的事情要少得多。
更大的担忧实际上是,背后并没有太多的知识产权隐藏在其中,正如我们讨论过的,我们在开发日上与他交谈过的可以微调4o以超越o1。Claude Sonnet到目前为止在编码任务上击败了o1,至少在o1预览中没有成为推理模型,Gemini Pro或Gemini 2.0也是如此。
那么,推理有多重要?在这种专有的训练数据中有多少模式?因为像DeepSeek这样的公司也能够做到这一点,他们有两个月的时间来做这个R1,所以实际上不清楚有多少模式。显然,如果你和o1的团队交谈,他们会说“我们花了过去两年在这上面”,所以我们不知道。这将会很有趣,因为会有很多噪音来自那些声称他们有推理时间计算但实际上没有的人,因为他们只是有花哨的思维链,而其他人实际上确实有非常好的思维链,你不会看到他们与OpenAI处于同一水平,因为OpenAI在建立他们团队的神话方面投入了很多,这很有意义,现实在某种程度上介于两者之间。
GPU贫民与GPU富豪
Alessio Fanelli: 这就是GPU贫民与GPU富豪之间主要数据战争的发展。你认为我们处于什么阶段?再次回到小模型的事情,曾经有一段时间,GPU贫民或类似叛军的派系在研究这些开放、小型和廉价的模型。今天人们对GPU的关注不再那么强烈了。你也可以在GPU的价格中看到这一点,那个市场已经崩溃,因为人们不想再依赖GPU,他们甚至不想再贫困,他们只想完全摆脱它们。你如何看待这场战争的发展?
SWYX: 你可以告诉我关于这个的事情,但我感觉对GPU丰富的初创公司的需求已经消失了。比如,融资计划是我们将筹集6000万美元,其中5000万美元将给Nvidia,这种情况已经不复存在了。没有人再提出这样的计划了。这实际上是去年的确切计划。
所以,GPU丰富的初创公司已经消失了,但GPU超富裕的公司仍在继续。现在,我们有Leopold关于万亿集群的文章,虽然我们还没有达到那个水平,但我们有多个实验室。xAI非常著名,Jensen Huang称赞他们在12天内启动了100,000个GPU集群。
同样,Meta、OpenAI和其他实验室也在这样做。GPU超富裕的公司将继续这样做,部分原因是这已经成为一种信仰,你只需要它。你甚至不知道你将用它做什么,但你就是需要它。如果我们进入研究领域,尤其是从2020到2023年扩展大模型的领域,因为我们在2020年有GPT-3,我们想从175B扩展到1.8T,这就是从GPT-3到GPT-4的过程。这已经完成了。
就大家而言,Claude的Opus 3.5并没有推出,GPT-4.5也没有推出,Gemini 2我们没有Pro。我们已经碰到了一个瓶颈期,我称之为2万亿参数瓶颈期。我们不会达到10万亿,没人认为这是个好主意,至少从训练成本和数据量来看,或者从推理的角度来看,你会愿意支付GPT-4价格的10倍吗?可能不会。你想要一些其他的东西,至少是更有用的东西。
所以人们在推理范式上转变是有道理的。当它变得更研究导向时,你实际上需要更多的通用计算来进行实验,同时旧范式的生产部署仍在积极增长。因此,GPU丰富的公司正在增长。
我们现在已经采访了Together、Fireworks和Replicate。我们还没有进行任何技能方面的采访,但Amazon可能是一个潜在的黑马。在re:invent上,我没想到他们会做得这么好,但他们现在是一个基础模型实验室,这有点有趣。David去了那里,开始训练模型。
AI模型的新兴趋势
Alessio Fanelli: 这就是预付合同的力量。很多AWS客户,他们签订了大额的预留实例合同,现在他们必须使用这些资金。这就是为什么这么多初创公司通过AWS市场被收购,以便他们可以将它们捆绑在一起以获得优先定价。
SWYX: 好的,也许GPU超级富裕的公司表现得很好,GPU中产阶级也不错,而GPU贫民者则……
Alessio Fanelli: 我的想法是每个人都应该成为GPU富豪者。实际上,GPU贫民者的存在是否有意义?如果你是GPU贫民者,你应该使用云模型。未来可能会出现一种情况,一旦我们弄清楚这些模型的大小和形状,像Tiny Box这样的东西会出现,让你在家里成为GPU贫民者,但今天的情况是,为什么你要努力让这些模型在非常小的集群上运行,而运行这些模型的成本是如此之低。
SWYX: 大多数人认为这很酷,他们认为这仍然是一个扩展的过程,所以他们渴望有一天成为GPU富豪者,他们正在研究新的方法,像是今年他们做的最深的技术就是Distro,或者新的名字。对异构计算和分布式计算的兴趣很大。我通常倾向于淡化这一点,但可能现在是开始变得相关的时候了。可能SF Compute今年推出了他们的计算市场,谁在使用它?这是一堆小集群,分散的计算类型。如果你能让它变得有用,那将对更广泛的社区非常有益,但也许仍然不是前沿模型的来源。它只是为人们解锁的第二层计算,这没问题。
但今年我会说更多的设备计算。现在我在手机上有Apple Intelligence,除了总结我的通知外没有其他功能,但这也不错,它是多模态的。通知摘要还行,在我看来,它们确实为生活增添了乐趣。Chrome Nano以及Gemini Nano即将在Chrome中推出,虽然仍然是功能标记,但如果你使用Alpha版本,现在可以尝试一下。
我们正在获得许多这些东西的GPU贫民版本,这非常有用。Windows也在每个部门推出RWKB,这非常酷。我在这场GPU贫民战争中从未提到的最后一件事是,许多GPU贫民的初创公司仍在良好扩展,作为基础模型实验室或GPU云的包装者。GPU云将Suno评为今年增长最快的初创公司之一。最后的公开数字是今年的ARR从0到2000万美元,而Suno本身并不富裕,但他们只是将训练放在模型上,我们也在播客中与他们交谈过。另一个是Bolt,Straight CLA,他们现在宣布的2000万美元的ARR是我们之前提到的800万美元的又一步。
所以,所有这些GPU贫民者都在找出路,而GPU富豪者也在找出路。然后,我有一个GPU微笑曲线,边缘表现良好,因为你要么靠近机器,成为机器上的第一,要么靠近客户,成为客户侧的第一,而处于中间的公司表现不佳。Character在所有公司中表现最好。你在这里提到的,我们显然说Character的价格标签是10亿美元,是吗?我说过吗?
Alessio Fanelli: 你说Google应该以10亿美元收购他们,仿佛这是个疯狂的数字,但他们支付了27亿美元。
SWYX: 为什么要支付这个?我不知道战争是什么样的,也许起始价格是10亿美元。
多模态战争
Alessio Fanelli: 无论如何,这对所有相关方来说都是有利的。这场多模态战争中,我们从未在第一版中拥有文本和视频,现在这是最热门的。
SWYX: 我会说这是图像的一个子集,但没错。
Alessio Fanelli: 但当时人们并没有真正在做这个。现在我们有昨天刚刚发布的Veo2,Sora则在上周发布。
SWYX: 你试过Sora吗?
Alessio Fanelli: 我还没有试过Sora,因为我试的那天……
SWYX: 现在它已经普遍可用,你可以去sora.com试试。
Alessio Fanelli: 他们发生了故障,这也起了一定作用。
SWYX: 小事。
Alessio Fanelli: 今天发布的另一个模型是什么?在Replicate上,Video-O1-Live。
SWYX: 名字非常不起眼,但它来自Mini Max,这是一个中国实验室。中国实验室在视频模型方面表现得出奇地好。
Alessio Fanelli: 很好。
SWYX: 中国人喜欢视频,我能说他们有很多视频训练数据。
Alessio Fanelli: 当然在某种程度上是这样。
SWYX: 在图像方面仍然是开放的。
Alessio Fanelli: 11 Labs现在是独角兽。那么,什么是多模态战争?多模态战争是指,你是专注于单一模态,还是拥有一个能够处理所有模态的上帝模型?所以这在11 labs的层面上肯定还在继续,现在11 labs成为了独角兽,PicoLabs也做得很好,他们最近推出了Pico 2.0。HeyGen已经达到了1亿的ARR。至于Assembly,我不太确定,但他们在各地都有广告牌,所以我猜他们做得非常好。这些都是专业模型和专业初创公司。
然后还有那些大型实验室,他们正在做的是一站式服务。在这里,我想强调Gemini 2,因为它具有原生图像输出。你见过演示吗?跟上进度很难,他们上周刚刚推出,向Paige Bailey致敬。她在发布当天来到Latent Space活动进行演示,她没有准备好,她只是说我只是想给你们展示一下。
他们有语音、有图像输入、可以生成代码等等OpenAI和Meta都有的新功能,但他们还没有推出的是图像输出。他们的演示视频是你放入一张车的图片,然后请求对那辆车进行小的修改,他们可以准确地生成你所要求的修改。因此,不需要像Stable Diffusion或Comfy UI那样的工作流程,比如在这里遮罩,然后在那儿填充,所有这些小模型导致的无聊步骤。有大模型的人会说,嘿,我们把你放进了Transformer的所有内容中。这就是多模态战争,你是押注于全能模型,还是像个傻瓜一样将一堆小模型串在一起?
Alessio Fanelli:我不知道,但这会很有趣。我使用MidJourney制作我们所有的缩略图,他们在产品上做了很多工作。我会说他们推出了一个新的MidJourney编辑器,他们做了很多工作。因为人们认为Black Forest模型在像素级别上比Midjourney更好。但当你把它们放在一起时…
SWYX: 你在Black Forest上试过同样的提示吗?
Alessio Fanelli: 但问题是,Black Forest只生成一张图像,然后你必须重新生成,你没有所有这些UI功能。像我所做的。
SWYX: 这是个技能问题,兄弟。
Alessio Fanelli: 不,但这就是时间问题。在MidJourney上……
SWYX: 调用API四次。
Alessio Fanelli: 不,但那没有变化。MidJourney的好处在于你可以直接进入,操作起来非常简单。人们低估了这一点,这并不完全是技能问题,因为我在支付MidJourney的费用,而Black Forest则是技能问题,因为我没有支付他们的费用。
SWYX:这就是一个用户体验的问题。至少Black Forest应该能够做到所有这些。我还想提到Recraft在Artificial Analysis所做的图像竞技场中脱颖而出,显然取代了Flux的位置,这仍然成立吗?所以Artificial Analysis现在是一家公司,我在年初的AI新闻中强调过他们,他们推出了一系列竞技场,所以他们试图与LM Arena、Anastasio和团队竞争,他们有一个图像竞技场。
哦,Recraft V3现在已经超越了Flux 1.1,这非常令人惊讶,因为Flux和Black Forest实验室是旧的Stable Diffusion团队,他们在经历管理问题后离开了Stability。因此,Recraft从无到有成为了顶级图像模型,这非常奇怪。我还想强调的是,Grok现在推出了Aurora,这是Grok和Black Forest Labs之间非常有趣的动态,因为Grok的图像最初是与Black Forest实验室合作推出的,作为一个薄包装,然后Grok说不,我们自己做。
所以他们做了自己的,没有API或基准测试,他们只是宣布了。所以,这就是多模态战争。到目前为止,小模型、专用模型的人正在获胜,因为他们专注于自己的任务,但大模型的人总是追赶上来。当我看到Gemini 2的图像编辑演示时,我可以放入一张图像并直接请求修改,这就是应该的工作方式,而不是一堆复杂的步骤。
这确实是一个问题,我们今年还没有看到的一个前沿是,显然视频表现得很好,并将继续增长。我们今天刚刚发布了Sora Turbo,但在某个时候,我们将获得完整的Sora,或者至少好莱坞实验室将获得完整的Sora。我们还没有看到视频到音频或视频同步音频,因此我与之交谈的研究人员已经开始讨论这作为下一个前沿,但可能还有五年的视频才能真正实现。
我会说Gemini与OpenAI的比较,Gemini或DeepMind在视频方面的做法似乎更为成熟,因为如果你查看我发布的ICML回顾,迄今为止没有人听过。即使人们听过,但这绝对是不同的。
Alessio Fanelli: 只有七个小时,但人们不听。
SWYX: 所以DeepMind正在开发Genie,他们还推出了Gen 2和VideoPoet。因此,他们在世界建模方面可能有四年的优势,而OpenAI没有,因为OpenAI基本上是在去年雇佣了两位专家后才开始融合Transformer的。
DeepMind在这里有一点优势,在展示方面,Veo 2挑选了他们的视频,所以显然看起来比Sora更好,但我相信Veo 2在完全推出时会表现得很好,因为他们在视频方面做了多年的背景工作。就像去年的新闻,我已经采访了他们的一些视频团队,我忘记了他们的模型名称,但对于那些忠实的粉丝,他们可以去纽约2023年查看那篇论文。
Alessio Fanelli: 最后但并非最不重要的是– LLMOS,之前称为RAG /Ops War。
SWYX: 我在Brain Trust的最新图表中放了这个,我会将这些文章与节目笔记分开。顺便说一下,我之所以这样做,是因为我想让它在Hacker News上出现。我希望播客能在Hacker News上出现,所以我总是把一篇文章放在里面,因为Hacker News的人喜欢阅读而不是听。
Alessio Fanelli: 所以节目文章…
SWYX: 你说Lang Chain、Llama Index仍在增长。
Alessio Fanelli: 我查看了PIIE的统计数据,你知道我不在乎星星。在PIIE上,你可以看到Lang Chain仍在增长,过去六个月Llama Index仍在增长。我基本上看到的是,显然这些东西是商业产品,所以人们在购买并坚持使用,而不是在不同的东西之间跳来跳去。例如,Crew AI的增长并不明显,虽然在GitHub上的星星在增长,但过去六个月的使用量基本上是平稳的。
SWYX: 他们是否进行了某种重组,分拆了包,现在变成了一系列包?有时会发生这种情况。
Alessio Fanelli: 我没有看到。
SWYX: 我可以看到这两种情况同时发生,Crew AI非常响亮,但并没有被使用。
Alessio Fanelli: 但无论如何,这类似于AutoGPT,仍然有一个等待列表来使用AutoGPT。
SWYX: 他们仍在继续且最近宣布了一些事情。
Alessio Fanelli: 但这是另一个,它是GitHub历史上增长最快的项目。但当你可能计算一下星星的价值和炒作的价值时,在AI中你会看到这一点,很多星星,以前在开源中没有看到的速度,没有人会急于启动一个NoSQL数据库,这种情况并不常见。
SWYX: 确实,人工智能领域有一个有趣的现象:你可以通过承诺未来的成果来获得资金支持,然后再逐步交付这些成果。人们对AI的耐心相对较高,但这种耐心会随着时间的流逝而逐渐减少。以Devin为例,它在今年三月份做出了许多承诺,经过九个月的努力,终于达到了一般可用性(GA)。尽管如此,人们依然对Devin保持着关注,它的产品也在不断改进,甚至有可能吸引你成为付费用户。这表明,像Devin这样的项目是能够取得成功的。
AutoGPT则是一个有趣的案例,它展示了AI领域中正在发生的动态。这是一种非常特定于AI的现象,即过度承诺和不足交付的问题,这在任何初创公司都可能发生,但在AI领域尤其明显,因为人们普遍认为AI具有通用性,几乎可以完成任何任务。
AutoGPT最初的目标是盈利,增加净资产,这吸引了许多人对这个项目的兴趣,也是它获得众多关注的原因。然而,由于项目涉及的范围太广,或者缺乏足够的专注,最终未能取得预期的成功。这就是我对为什么兴趣与使用比率如此之低的解释。
另一方面,成功的关键在于团队的执行力。一个有远见的团队需要能够将愿景转化为实际行动。去年,核心团队在工程师峰会后失去了一半的成员,这可能影响了项目的进展。这也许是为什么那些通用性的承诺,如ChatGPT和今年的Notebook LM,能够取得成功的原因。这些模型能够处理各种任务,如编写代码、进行PR审查等,虽然它们可能只是完成了一些小事情。
Alessio Fanelli: 代码解释我们已经讨论过很多次,我们在这个播客上软性宣布了E2B的融资。Code Sandbox上周被Together AI收购,他们现在也有提供API。有越来越多诸如此类的活动表明这很好。然后,在两集之前与Bolt的讨论中,我们谈到了他们正在进行的Web容器工作。代码解释的范围是专用SDK,像是模型的世界,嘿,我们现在有一个SandBox,你只需运行命令并协调所有这些。这非常疯狂,因为每个人都需要运行代码。现在所有的产品和每个人都在升级到“好吧,仅仅做聊天是不够的”,所以Perplexity作为2B客户,他们为金融和所有这些不同的事情做了很多漂亮的图表,产品正在成熟,这正变得越来越像一种“火急火燎”的问题。
SWYX: 主要是因为我试图将其限制在Rag和Ops上,但现在Frontier在核心工具集方面已经扩展。核心工具集将包括代码解释器–每个Agent都需要的工具。Graham在他的Agent状态演讲中也提到了这一点,这对我来说很有趣,因为每个人都发现相同的一组东西。基本上,大家都需要网页浏览,大家都需要代码解释器,然后每个人都需要某种记忆或规划,我们会随着时间的推移进一步发现这一点,但这是我们迄今为止发现的。
我想提到Morphlabs推出的时间旅行虚拟机。这些东西的状态性需要被严格控制。基本上,你不能只是启动一个虚拟机,运行代码,然后杀掉它,因为有时你可能需要回到过去,像是展开或分叉,以探索不同的路径,类似于树搜索方法来进行Agent开发。我会提到更新的实现来作为新兴的前沿,关于人们将需要什么,以便Agent能够进行非常广泛的代码执行。
我还想提到,ChatGPT Canvas与他们在12天的Shipmas中推出的功能,意外地超越了代码解释器。代码解释器是去年的热门功能。现在,Canvas也可以编写代码并运行代码,并且比代码解释器过去能做的更多。所以,目前它还没有取代代码解释器。在创建新的自定义GPT时,现在有一个切换框用于Canvas和代码解释器。我以前的论文认为自定义GPT是投资的路线图,因为这是每个人都需要的。
现在有一个新的框叫Canvas,所有人都可以访问,但基本上没有理由使用代码解释器而不是Canvas。Canvas 已经整合了差异模式(diff mode),Anthropic和OpenAI以及Fireworks都已经发布了这一功能,这将成为明年的新常态。每个人都需要某种diff模式的代码解释器。
Alessio Fanelli: 你想谈谈记忆吗?你认为它不真实?
Alessio Fanelli: 我只是觉得大多数记忆产品今天就像是总结和提取。它们非常不成熟。没有隐式记忆,它是你所写的显式记忆。没有隐式提取,比如说你对这个说了十次“不”,你不喜欢在清晨6点去徒步旅行。没有任何记忆产品会这样做,它们只会总结你明确说过的内容。
SWYX: 当你说记忆产品时,你是指那些提供记忆作为服务的初创公司吗?
Alessio Fanelli: 它是基于我所说的内容来记住的。所以这更少关于记忆我的偏好,而更多是关于我明确说过的内容。我在试图弄清楚在什么层面上可以解决这个问题。这些记忆产品,像MemGPTs这样的产品,是否创造了一种更好的方式来隐式提取偏好,或者这是否可以很好地完成。这就是为什么我不认为记忆不真实,我只是认为今天的方法实际上并不是你需要助手所拥有的记忆。
SWYX: 我实际上同意这一点,但我只是想指出它不成熟,而不是不需要。显然,这是我们在某个时候会想要的东西,因此现在开发它的人并不是很擅长。我可以肯定地预测明年会更好,后年会更好。上次我们与Harrison作为客座主持人进行的播客中,我过于关注LangMem作为一个独立产品。他现在已经将其整合到Lang graph中,作为一种记忆服务,使用相同的API。每个人都需要某种记忆,这现在已经与普通的Rag向量数据库区分开来。你将需要一个记忆层,无论它是在向量数据库之上还是下面,这取决于你。记忆数据库和向量数据库是两种不同的东西。我实际上不得不为此辩护很多次,实际上我在Latent Space仪表板上有一篇草稿,基本上说记忆和知识之间的区别。
对我来说,这非常清楚。知识是关于你周围世界的,而你拥有的知识是你公司的Rag语料库,或者其他什么东西。还有外部知识,就是你在谷歌上查找的东西。所以你使用像EXA这样的东西。然后是记忆,就是我与你的互动。两者都可以通过向量数据库或知识图谱来表示,这并不重要。时间在记忆中是一个特别重要的因素,因为你需要一个衰减函数,然后你还需要一个审查函数。很多人将其实现为睡眠,就像你睡觉时,你实际上会处理一天的记忆,并得出新的见解,然后你将这些见解持久化并在未来带入上下文中。因此,这正在被开发。Langraph有这个版本,Zep也是一个基于Neo4j知识图谱的版本,MGPT曾经有这个,但自从它获得了Qui Capital的资金后,它已经扩展到更通用的LLMOS类型的初创公司,现在有很多这样的公司。
Alessio Fanelli: 你认为这是一个LLMOS产品,还是应该是一个消费产品?
SWYX: 这是一个构建块。每个消费产品最终都会想要一个网关,用于管理他们的请求、操作工具以及类似的东西。代码解释器可能不会暴露代码,但肯定会在后台执行代码。因此,它将需要长生命周期的记忆。作为一个消费者,假设你是一个新的计算机用户,他们推出了自己的小Agent,或者如果你是friend.com,你会想在某个时候投资记忆。也许不是今天,可能是更久的将来,像是百万个token的上下文,但在某个时候你需要压缩你的记忆并选择性地检索它。然后你该怎么办?你必须重新发明整个记忆堆栈,而这些人已经做了一年了。
Alessio Fanelli: 对我来说,更像是我想带来记忆,几乎就像它们是我的记忆。为什么每次我去一个新产品时,它都需要重新学习一切?
SWYX: 你想要可移植的记忆。
Alessio Fanelli: 这像是一个协议,这怎么运作?
SWYX: 说到协议,Anthropic推出的模型上下文协议有一个300行代码的记忆实现,非常简单,但这对所有记忆初创公司来说都是个坏消息,但这就是你所需要的。拥有一个可移植的记忆,能够传递给其他人,简单的答案是,暂时没有标准化,因为每个人都会尝试自己的东西。Anthropic在MCP上的成功表明,基本上除了大型实验室之外,没有其他人能做到这一点,因为没有其他人有能力做到这一点。除非你有一些愚蠢的东西,比如说某种标准化,基本上来自Georgie Granov的Llama CPP,而那是完全开源的,完全自下而上。这是因为需要完成的工作量非常庞大,然后人们从那里建立起来。另一种标准化形式是Comfy UI来自Comfy Anonymous。因此,这种标准化可以做到,所以基本上必须有人为角色扮演社区创建这个,因为那些人现在拥有最长的记忆。根据我的理解,角色扮演社区,我查看了S Tavern和Cobalt。他们只分享角色卡,并且有四五种不同的标准化版本,但还没有人有可导出的记忆。如果有人首先开发出记忆并成为标准,那将是这些人。
AI基准的未来
SWYX:我们讨论了在LMSYS的ELO评分中,每个人的成绩都在提升,竞争非常激烈。基准测试也同样如此。我今天看了OpenAI的直播,他们介绍了具有结构化输出等功能的o1API。而他们现在谈论的基准测试与去年这个时候我们谈论的基准完全不同。去年此时,我们还在讨论MMLU,以及一些像GSMAK这样的内容。这些内容基本上还停留在V1版本上,就像Hugging Face开放模型排行榜中的内容。我们还与Clementine讨论了她升级到V2版本的决策。此外,今年还出现了LM Sys,现在称为LM Arena,这成为了大前沿实验室之间的主要战场。同时,我们还看到了SuiBench、LiveBench、MMU Pro和Amy等的出现。其中Amy是2020到2025年间被引用最多的基准之一。有些内容已经饱和并被解决,现在大家更加关注前沿数学编码,甚至有一个基准叫做Frontier Math,我在NeurIPS上谈论过它。还有Amy、Livebench、MMORPG Pro和SweetBench。这挺好的。
去年这个时候GPQA还很流行。数学和GPQA是去年的顶级基准。很遗憾的是,在NeurIPS上,GPQA被宣布’死亡’。不过人们仍然在谈论GPQA Diamond,GPQA的全称是“Google Proof Question Answering”(防谷歌搜索问答),所以它应该能在一段时间内抵抗饱和。Noam Brown表示GPQA已经死了。所以我们现在只关心SweetBench、LiveBench、MMORPG Pro和Amy。即使是SuiteBench,我们也不关心真正的SuiteBench,我们关心的是SuiteBench Verified,是SuiteBench的多模态版本。此外,我们还关注Andy Kowinski新推出的Kowinski奖,他推出了一种类似于Arc AGI的SweetBench类型指标,这个尝试可能更加实用。
OpenAI也推出了MLEbench,专注于机器学习研究和自举方法,这可能是与前沿实验室最相关的指标。因为对研究人员来说这意味着可以实现自己工作的自动化,如果可以实现的话,那将是加速曲线中的一个关键拐点。
Alessio Fanelli:我很好奇,我记得Dylan在辩论中提到,SweetBench80%是明年年底的目标,类似于一个标杆,这意味着模型仍在持续改进当中。
SWYX:我们年初开始时是13%。
Alessio Fanelli:没错。
SWYX:现在大约是50%,OpenAI大概也在那个水平。而80%听起来不错。Kowinski奖是90%。
Alessio Fanelli:然后当我们达到100%时开源技术会逐步缩小与闭源技术之间的差距。
SWYX:我的建议是,密切关注基准语言的发展,因为那些不在前沿的实验室会继续使用去年的基准来衡量自己,而真正的前沿实验室则会告诉你一些你从未听说过的新基准。你会觉得原来还有新的领域可以探索。也许我不会过多阐述这一点。也许Veo引入了一些新的视频基准测试,几乎每个新的前沿技术都会引入新的基准。我们接下来要讨论的内容便是如此。我们还会简要谈谈Ruler这一新方法。去年我们就像是“大海捞针”,而Ruler基本上就是一个多维的“大海捞针”。
Alessio Fanelli:我们会链接到相关的节目作为对我们所做节目的一个回顾。
SWYX:这是我在Dev Day演讲中使用的一张幻灯片。所以我们讨论的重点正在从基准测试转向技术水平。我有一个有用的分类方法一直在推广,很想听听你们的反馈或修改意见。我挺喜欢这个思路的。MMLU是一个正在崛起的展示成熟的前沿和小众模型的框架。所以“成熟的技术”指的是你可以在生产环境中完全依赖的技术,它已经得到解决,大家都能使用。已经解决的技术包括通用知识,比如MMLU。另一个已经解决的技术是长上下文处理,现在每个人的模型都有128K。今天o1宣布了200K,但这非常昂贵,具体价格我不清楚。已经基本解决的技术是RAG。RAG有大约18种不同的类型,但大部分问题已经解决了。在语音转录方面, 我会推荐Whisper ,你可以多使用它。至于代码生成,基本上也算是已经解决了。代码的生成有不同的层次,而我确实需要区分单行自动补全和多文件生成。工具使用绝对是正在崛起的的一股热潮。所以在新兴领域,工具的使用已经差不多解决了。可以算是新兴的领域,也可以算有些成熟了。但它们今年才推出了短输出功能,所以它仍然属于新兴领域。视觉语言模型,现在每个人都有视觉能力了,包括Owen也是。这很清楚。视觉技术的一个子集是 PDF解析。在与CodePoly和CodeQuin的相关工作中,研究界对这些进展非常兴奋。
Alessio Fanelli:对于你来说,视觉技术成熟的转折点是什么时候?
SWYX:基本上就是现在。这个可能是两个月前的事了。NVIDIA,现在是世界上最有价值的公司。这是在六月时发生的,之后他们的第三季度财报也让人非常惊讶,表现远超预期。我在AI新闻中标注的引用是:“Blackwell是公司历史上最畅销的系列。”它们已经卖光了,显然它们总是供不应求。但是他能做出这个声明,这再次表明,从H系列到B系列的过渡将会非常顺利。
Alessio Fanelli:那如果你只是买了NVIDIA然后把你的BT游戏拿出来的话那将会很疯狂。
SWYX:你认为NVIDIA和比特币哪个更值钱呢?是NVIDIA。
Alessio Fanelli:从收益来看,确实是的。
SWYX:问题是为什么不投资NVIDIA,理由是什么?关键在于他们已经承诺了这一点。他们把两年的周期改成了一年的周期。所以,一旦出现失误,可能会导致延迟。过去也有过延迟的情况。而且,当延迟发生时,通常是非常好的买入机会。
Pionote 和前沿模型
SWYX:然后我们来说说前沿技术,它基本上是在即将到来的阶段,但还没有准备好广泛应用。这些技术展示给大家看很有意思,但我们还没有真正弄清楚,例如如何日常使用这些技术、如何通过长时间推理、实时中断、实时API语音模式的设备端模型以及其他所有模态来赚取大量资金。
利基模型和基础模型
SWYX:然后是细分模型。我经常强调,基础模型被大大低估了。人们总是喜欢谈论基础模型但是我们获得它们的机会越来越少了。Sam Altman在谈到2025年时提到过,当他询问人们希望他发布什么,或者希望他开源什么时,人们表示他们真的很想要GPT-3基础版。我们可能会得到它,也可能不会,我们无法预料,这只能由历史决定。但目前来说,我们很有可能会得到它。对Sam Altman来说,GPT-3基础版显然不再是一个重要的知识产权了。所以,我们拭目以待。 OpenAI现在有很多其他事情要处理,而不是发布基础模型,但如果能为大家做这件事,那将是非常非常好的事情。
状态空间模型和 RWKB
SWYX:尽管今年关于状态空间模型的炒作很多,特别是在Linspace Live 上关于“后 Transformer”的讲座引起了极大的关注,并且有很多人参加和观看,但相比之下,今年的状态空间模型的热度有所下降。我不知道为什么。看起来状态空间模型和RWKBs似乎正在向外扩展。所以Cartesia做得非常好。它们在很多方面都表现出色,特别是在Smalltalks和我们的一些Notebook LN播客克隆中,我们都用到了它。它们是真正的11 Labs的竞争者。当然,RWKB也正在Windows上逐步推出。所以我还是觉得这些都属于小众领域。
从技术角度看,我们现在已经处于比去年更远的未来,但我们现在说的内容和去年说的一模一样。那么,发生了什么变化呢?xLSTM论文值得一看,我们会在讨论NeurIPS论文时涉及这篇论文。他们非常清楚地知道如何修复LSTM。接下来我们还想稍微谈谈今年的主要主题。我们打算按月回顾。
推理竞赛与价格战
SWYX:其中一个主要的主题是底层的推理竞赛。在人工智能或机器学习领域,很多公司都在努力提高推理(即模型的推理能力)效率和性能的竞争力。在这个领域,谁能提供更快、更精准的推理,谁就可能占据市场的优势。从去年这个时候开始,2023年的价格战就已经拉开了帷幕。混合模型的价格从每个token1.80美元降到了1.27美元,仅仅在几周内就发生了变化。
很多人也对今年的价格战以及今年的价格智能曲线很感兴趣。随着Haiku的发布,我大概在2024年3月开始跟踪这个情况。如果你在看YouTube的话,这就是我最初绘制的图表:这里是前沿,大家的LMSYS ELO和模型定价大致都在一个相对紧密的范围内,你可以支付更多的费用来获得更高的智能,也可以支付更少的费用来获得较低的智能,但大体上它们相互对齐,并且呈现出一个趋势线。然后我可以在7月再次更新它,看到一切都向右移动了。所以对于相同的ELO值,比如说2023年的GPT-4,Claude3大概是11.75的ELO,而以前你需要花费每百万个token40美元来获得这个ELO,现在你可以用0.5美元获得相同ELO的Claude3 Haiku。所以在大约一年内,这是两个数量级的提升。但更重要的是,最近发布的大模型,如今年3月发布的Claude3 Opus,现在基本上完全被Gemini 1.5 Pro取代,后者不仅更便宜,每百万个token只要5美元,而且更智能,其职能性也稍微高于Elo。所以,从3月的前沿到7月的前沿,基本上是每个ISO ELO的提升约为一个数量级。
现在你开始看到的情况是,4.0 Mini和DeepSeq v2作为7月前沿的离群值出现,而7月的前沿曾由4.0、Llama405、Gemini 1.5 Flash、Mistral和Nemo维持。这些模型突破了前沿技术。如果你更新一个月后,回顾一下,你会看到更多的模型开始出现在8月的前沿技术中,Gemini 1.5 Flash在8月的更新中推出,价格大幅下降,ELO基本相同。然后,我们更新了9月的情况,这就是其中一个关键时刻,真的开始理解定价曲线是实际存在的,而不是某个网络上的人随便画的图。因为Gemini 1.5降低了价格,并且价格的降低与其他模型的ELO定价图完全一致。
如果你绘制9月的图表,你会看到o1预览的定价、成本和ELO情况,因此9月的前沿是o1预览和GPT-4、0.0.1 mini,4.0.0.0 mini,以及低端的Gemini Flash,这些是截至9月的前沿技术。当时,Gemini 1.5 Pro并不在这个前沿之上。然后它们降低了价格,价格减半后,突然间它们就进入了前沿。因此,这条线非常紧密且具有预测性,这既有趣又引人入胜。这挺酷的。到11月,我们有了3.5版本的Haiku更新,显然我们也有Sonnet版本。Sonnet在这张图上不确定是否出现过,但Haiku的新版本基本上是旧版Haiku价格的4倍,或者说,3.5版本的Haiku是3.0版本的4倍价格,大家对此有些不满。
这有一个合理的假设,这并不是价格上涨,而是因为这是一个更大的模型,所以成本更高。但我们并不知道这一点,因为没有透明度,所有的结论都只能靠我们自己去推断。这就是现状,这就是关于价格和ELO的图表的更新。如果你查看我公开的LLM定价图表,最近的更新是亚马逊的Nova,我们在播客中简要提到过,它实际上是进入市场并提供了类似亚马逊基础款的LLM,其中包括Nova Pro、Nova Lite和Nova Micro,它们是他们的智能水平的高效前沿,ELO在1200到1300之间。如果你想超过1300的ELO,就得为o1、4O和Gemini 1.5 Pro这样的模型支付更高的费用。不过,2Flash不在这里,它的价格可能会高一些。Flash思维模型也不在这里,包括所有其他的QWQs、R1s以及其他类似的思维模型。所以我得更新这个图表,始终保持更新确实很困难。我想让你了解的是,在2024年内,对于相同的ELO,2024年初你支付的费用大概是每百万个token40到50美元,而现在,通过亚马逊Nova,价格大约为每个token0.075美元,约为7.5美分。这意味着至少是几次数量级的提高,实际上差不多是三次数量级的进步。
智能成本每年下降一个数量级,比如10倍。这已经比摩尔定律快了,但今年下降三倍,是很多人没有意识到的加速变化。显然,很多人都在猜测明年会怎么样,H200将成为商品化产品,Blackwell也将推出。预测非常困难,还有很多因素不仅仅与GPU相关。所以这是关于价格ELO图表的主题概述。
2024 AI 大事记
SWYX:然后进入了年度概览。回顾了今年的AI新闻发布,并挑选出了一些最喜欢的内容。我让我们的新研究助理Will帮忙做了一些研究,但你也可以去AI News查看当天的所有主要新闻。我们还做了一个AI回顾的环节,我会简短地带你回到我们之前的录音。
AI回顾:一月到三月
SWYX:一月,我们迎来了“完美城市”项目的第一轮。值得注意的是,Jeff Bezos支持了这个项目。Jeff不会投资很多公司,但他一旦投资,就是投资在重要的项目上,比如他曾投资了谷歌,现在又支持了新一代谷歌。Perplexity现在价值90亿美元,他们今年进行过四轮融资。Will还提到,Sam曾谈到GPT-5很快就会推出。那时候他应该是在达沃斯的某个峰会中说的。结果,GPT-5并没有出现,事实是我们得到了o1和o3。回顾去年Dev Day,那时人们对GPT失去了些许信心,而现在这种情绪没有完全恢复。我听到一些人说,虽然还有很多东西在开发中,但你不应该放弃,它们现在其实被低估了。大家在解决这个问题,并且它是一个应该存在的东西,我们只需要继续对它进行迭代就行。老实说,任何市场都很难判断,尤其是考虑到你已经发布的其他内容。
ChatGPT也在二月发布了记忆功能,这个我们之前讨论过一些。我们还看到了Gemini的多样性争议,我们在这个播客里通常不太谈这些话题,因为我们尽量保持技术性,但我们也开始看到上下文窗口大小的增长。今年,Gemini的上下文窗口达到了100万token,甚至还有200万token的说法。我们曾和Gradients进行过一场播客讨论,讲述如何进行100万token的微调。这不仅仅是你对你的token文本如何声明,你还需要有效地使用它。越来越多的人开始不仅仅关注Ruler(我们之前提到的那种大海捞针的情况),还关注Muser等工具,以及如何在长上下文中进行推理,而不仅仅是能够从长上下文中检索信息。这就是我特别想提到的,另外,Magic.dev也因其1亿token的模型掀起了不少波澜,尽管它在去年就有了预告,但至今仍未发布,我们不知道具体情况,但我们会尝试邀请他们参加播客。
三月,Claude 3发布了,对Anthropic来说,这无疑是一个巨大突破。这标志着市场份额的变化,正如我们在播客中早些时候所提到的,大部分生产流量集中在OpenAI上,而现在Anthropic拥有了一个不错的前沿模型系列供人们转向。显然,Sonnet是它的主力模型,就像4.0是OpenAI的主力模型一样。Devon也在三月发布了,这是一个非常大的发布,可能是近十年来技术领域最成功的公关活动之一。不过,之后有很多关于发布视频中具体内容的争议,所以他们花了九个月才正式发布,现在你可以以每月500美元的价格购买并且对于它的使用形成了一些你自己的看法。有些人很满意,但也有一些人不那么满意。毕竟,要兑现他们所做的承诺非常不容易。对于Devon,我想提醒的一点是,很多想法可以被复制,这也是所谓的“GPT包装器”面临的威胁——你通过一个功能实现了市场适应性,但很快就会有一百个人跟着做。所以,你必须通过品牌、产品和工程等方面的优势来竞争,而Devon在这些方面是非常有优势的,我们拭目以待。
AI回顾:四月到六月
SWYX:四月,我们与Yurio和Suno进行了交谈。我们特别与Suno交谈过,但UDL我也获得了Beta访问权限,涉及到AI音乐生成。我们在播客中体验了这个功能,我非常喜欢。我们播客中的一些朋友喜欢在他们的车里播放我们的Suno主题曲,我自己也很喜欢使用o1来创作歌词,用Suno和Yudioh来制作歌曲。但很多人跳过了这些部分,我不知道具体的跳过百分比,但你们中的10%跳过了这些内容,这就是我们剪掉主题曲的原因。Lama 3也发布了。大家总是想看到一个好的前沿开源模型,而Lama 3显然做到了这一点,推出了8B和70B,400B稍后发布。
接着,5月,GPT 4.0发布了,我们讨论过它,这是一个关于模型效率的东西,但它也是4.0所有能力的一个很好的展示。就在这个时候,OmniModel的消息开始显现。之前的4和4.0 Turbo都是文本模式,虽然它们有视觉功能,但并不支持语音。然后,大家都爱上了SkyVoice,但在发布之前它就被取消了。这是他们自己造成的。事件的原因是Sam Altman发了一条三字母推文,造成了一些法律诉讼的问题,事实上他们只是用了一个听起来像Scarlett Johansson的女声演员。虽然有点遗憾,但事实就是如此。
在6月,苹果在WWDC上宣布了Apple Intelligence。大部分人如果你更新了iPhone,现在都能使用它。它还行,它并不是那个让苹果股价上涨20%的游戏改变者。因为大家想升级iPhone来获得Apple Intelligence。但它应该是目前规模最大的一次transformers的推出,仅次于谷歌为搜索推出的BERT。它在你的手机本地中运行,并且支持热切换的Loras模型,我们也有相关论文。老实说,苹果做得很棒,做到了他们能做到的最好,虽然他们不是世界上最透明的公司,也没人指望他们是,但他们提供了比我们通常从苹果技术中获得的更多,这对研究界来说也非常好。
我们继续讨论NVIDIA,我在台湾的Comtex展会上看到他们签署的内容,可能是时代的标志,或者是表明事情已接近巅峰,但显然事情并未达到巅峰,因为他们继续前进。然后Ilya出现了,筹集了十亿美元。Dan Gross似乎现在已成为公司的全职CEO,这很有意思。我原以为他会成为终身投资人,但他现在在运营。Ilya的想法是,你只推出一个产品,直接对准超智能,这看起来是一个很好的聚焦使命,但这与特斯拉和OpenAI的策略相对立,因为他们推出了中间产品来实现这一愿景。
Alessio Fanelli:现在的问题在于OpenAI现在需要更多的钱,因为他们需要支持这些产品,可能他们的赌注是:用10亿美元可以达到目标,我们不想经历中间步骤,直接让人明白这是我们的目标。
SWYX:可是,数据从哪里来呢? 这正是问题所在。这也可以作为OpenAI的安全团队离开的一部分,合理地说,Yann LeCun也离开了,基本上整个超对齐团队也离开了。接着有了Artifacts,这是类似于Chajupiti Canvas的东西,更多是面向代码的。在OpenAI之外,Canvas出现了。有趣的是,负责Artifacts和Canvas的人Karina,在此之后正式离开了Anthropic,加入了OpenAI,这是一次罕见的反向举动。
Gemini实际上先于他们发布了GA版本,这也很有趣。大家应该始终开启这个功能,只要你对隐私设置感到舒适,我敢打赌,到明年此时,我会在我的设备上一直运行这个功能。这种始终开启的助手,可以与你互动并且看见你所看见的东西,虽然并不是所有地方都做得很好,但是至少对于屏幕上的软件体验来说,它已经做得基本到位了。
AI回顾:7月至9月
Alessio Fanelli:到了7月,推出了Lama 3.1,我们也为此专门录制了一期播客。这真的很棒。还有《结构化上传》,我们也做了完整的播客。
接着9月,我们迎来了o1,也就是Strawberry,又叫Qstar。我们还戴着草莓主题眼镜,开了个特别欢乐的派对。
SWYX:这一点被严重低估了。 Strawberry的第一个内部演示,大概是在2023年11月。也就是说,从11月到9月之间,经历了整个测试和优化流程。这样的产品发布速度非常快。不知道人们是否给了OpenAI足够的认可——这东西先是整合到了ChatGPT,很快也在API中上线了。我记不清确切的时间顺序了,但基本上同一天推出的可能性很大。
这是一个最前沿的模型,几乎是以极快的速度面向全球发布的。大家一下子就用上了,然后又很快嫌弃它,说它不如Sonnet或其他东西。但客观来说,这已经非常不错了。而且现在我们还有了o1 Pro和o1 Full。
在今年发布的所有重要产品中,这应该是最重磅的吧。
Alessio Fanelli:它还开启了关于推理时间和计算能力等一系列新话题。
SWYX:很有意思的是,这本来可以由其他人更早实现——这几乎是个公开的秘密,他们自从招募Gnome后就开始研究了。但最终只有OpenAI做出来了。另一个发现是,Ilya其实在2021年就曾开发过一个早期版本,叫GPT-0,理念完全一样,但失败了。不知道具体原因是什么。
Alessio Fanelli:时机合适,还有语音模式。现在大多数人都已经尝试过了,因为已经全面上线了。
SWYX:我记得你妻子也挺喜欢用的吧?
Alessio Fanelli:是啊,她一直在用它聊天。
AI回顾:十月至十二月
Alessio Fanelli:十月的Canvas,又要进行一次重要更新。
SWYX:你用过多少?
Alessio Fanelli:我没怎么用过。
SWYX:我用得很多。
Alessio Fanelli:你主要用它做什么?
SWYX:草拟东西。人们无法看到这一切会朝哪里发展。就像是OpenAI真的是在所有领域都在和Google竞争。Canvas就是Google Docs。它是一个完整的文档编辑环境,旁边有一个自动助手功能,可以说比Google Docs更好,至少在某些编辑场景下是这样的。因为它的AI集成比Google Docs强得多。就像是Google Docs旁边加了Gemini。OpenAI正在向Google以及Google Docs发起挑战。同时它也在搜索领域发起挑战。它们推出了那个小小的Chrome扩展,作为默认搜索。它们一点一滴地以一种非常聪明的方式开始真正挑战Google,这对工作流程是有益的,大家应该按照它的设计开始使用,因为这也是未来的一个预览。也许它们不会成功,但至少它们在尝试。而且Google已经很长时间没有竞争对手了,任何尝试的人都会引起我的关注。
Alessio Fanelli:电脑使用方面也有新变化。
SWYX:电脑使用是Hacker News今年最受欢迎的演示之一。但与此相比,我发现大家并没有那么频繁地使用它。这就是你能感受到成熟能力和新兴能力之间的区别。也许这就是为什么视觉技术正在崛起的原因。因为我推出了电脑使用功能,但你今天并没有使用它。但你会使用所有其他成熟类别的功能。这主要是因为它不够精准,或者太慢,或者太贵。这些将是主要的批评点。
Alessio Fanelli:这很有道理。人们对于让它在电脑上完全自由运行也会有些不安。但很多人还是会这样做。十一月,R1,那就像是开源的版本。
SWYX:没人知道它会出现。大家都知道我们在Fireworks总部做了预览,其他一些实验室也做了,但R1和QWQ(来自Quent团队的Quill)都和阿里巴巴有关系,应该是这个领域的领先竞争者。我们拭目以待。
Alessio Fanelli:还有什么值得强调的吗?Stripe的代理工具包虽然是一个小项目,但就像人们说Agents不是真实的。当你看到像Stripe这样的公司开始构建支持它的东西时,这就意味着Agents虽然今天可能还不现实,但显然它们并没有必要去做,因为它们不是一家AI公司,但他们做了,这表明有需求,也显示出他们的信心。
SWYX:这是一个关于我正在探索的问题的更广泛的话题,我们是否需要为Agent创建专门的SDK?为什么不能用普通的SDK(面向人类的)来实现同样的功能?Stripe代理工具包恰好是Stripe SDK的一个封装,它只是一个很好的开发者体验层。但是,我仍然不太清楚。我记得在一个播客中说过,你主要需要的是一个分离角色的层,这样你就不会假设这些操作是由人类完成的。你可以更快地锁定事情,确认是否是代理在代表你行动,还是实际上是你自己做的。我曾经因为丢失了我的笔记本电脑而被窃取了11 Labs的密钥,然后我看到了一堆API调用,我就想,这是我自己做的吗?还是其他人做的?结果发现是一个密钥被提交到了GitHub并没有被清除掉。所以API使用来源的问题,你应该归因于Agent,并做好准备。除此之外,SDK的存在是开发技术和AI的失败,我们不应该为每个Agent都重新发明所有东西。
Alessio Fanelli:我同意某些方面。在其他方面,我们也并没有总是把事情做得非常明确。当人们设计API时,往往有很多默认设置。但如果你重新设计这些API,假设使用它们的人或Agents拥有无限的记忆和内容,可能会做出不同的设计,但我也不太确定。对我来说,像REST和GraphQL在Agents的世界里变得更加有趣,因为Agents可以发起许多不同的查询。而以前,我总觉得GraphQL其实并不是特别必要,因为你知道你需要什么,只需要为其构建REST端点。所以,他们已经有了搜索之战:搜索GPD、Perplexity、Dropbox、Dropbox Dash,我很好奇接下来还会有什么变化。我们曾请了Drew来做播客,然后我们加入了Pioneer Summit。事实是Dropbox有Google Drive集成,这就像是,如果你五年前告诉某人这一点,他们会觉得Dropbox其实并不在乎你的文件。但这样的说法根本不成立。所以,我很想看看接下来会怎样发展。
年终反思与预测
SWYX:现在我们来到了12月,我很好奇OpenAI最后一天的发布会是什么样的,每个人都在期待那一天会有重大事件发生。到目前为止,这确实是非常充实的一年,发展非常迅速,Will曾问我们是否做了预测,我们没有做,但我们确实谈到了Agents。
Alessio Fanelli:我不确定我们是否说过今年是Agents的一年,但我们说过明年一定是Agents的一年。关于自主性的结构是在2023年4月讨论的,显然这一点已经有了一段时间的信念。但是现在这些模型在过去的两个月,能力方面有了很大的提升。
SWYX:Ilya在Eurips大会上说出“Agentic”这个词,这是一个大事件。Satya,现在也经常提到这个词,Sam已经说了很长时间了。所以,当DeepMind宣布Gemini 2.0时,他们也宣布了Deep Research,还包括Project Mariner,这是他们的浏览器Agents,类似于他们的计算机使用方式,以及Jules,这是他们的代码Agents。这与OpenAI明年推出的代号“operator”的代理工具相得益彰。如果它真的能够替代一个初级员工,收费2000美元是很有可能的。
Alessio Fanelli:这就是我的全部内容,我写过一篇文章,已经固定在我的Twitter上,关于工作中的技能底线和技能上限。技能底线越来越高,2025年将是AI设定技能底线的第一年。总体来说,在过去这并不成立,但现在所有客户都支持用Agent工作,例如Devon。所以现在要成为一个客户支持人员,你需要比Agents还要优秀,因为经济学上根本不成立。同样的事情会发生在软件工程上,软件工程的技能底线非常低。很多从事软件工程的人其实并不那么优秀。所以我想看看,明年回顾时,其他哪些工作也会经历这种变化?
SWYX:每次参加NeurIPS,我都会和一些研究人员聊聊,然后我会突出他们团队的最佳预测,我们再进入年终总结,按顺序列出前五名的播客再结束,所以最好的预测是会有一个外国间谍在其中一个主要实验室被抓到。这已经是意识的一部分了。这就像当你看到一个在旧金山派对上很迷人的女人时,而那里男多女少,比例大约是100比1,那个女孩突然对你超级感兴趣,这可能不是因为你的长相。这些实验室里保存着大量的国家级机密,而安全性并没有那么高。情境意识的文章提高了对这一点的关注,尽管它不完全准确,但方向是正确的。我们应该开始更加关注这个问题。OpenAI今年聘请了首席信息安全官(CISO),在整个安全领域也是如此。我记得我刚才想说的关于Apple Foundation Model的事情,在我们休息之前,他们宣布了Apple Secure Claude云计算。我们也有兴趣投资于那些基本上为所有人提供安全云LLM推理的领域。我们现在所拥有的安全性还不够,这种涉及国家级利益的领域却拥有过于普通的安全性。
Alessio Fanelli:我同意。我正在浏览Substack。第一期是David的那一集:为什么谷歌没能做出GPT-3?它是2024年最受欢迎的节目之一。
SWYX:我需要为这个命名承担一定的责任,是那个hecken新闻的事情,这很有趣因为显然他想谈论Adept,但他却花了半集时间谈论他在OpenAI的经历。但这是一个非常有用的见解,我至今仍在使用。即使在早期的帖子中,我仍然引用他的话。当我们做播客节目时,我会寻找这样的内容。我会寻找那些我们将来还会引用的东西。当David谈到集中式弊端时,他提到了大脑计算市场,然后在Ilya的邮件中,他预见到,一次大规模的训练运行比一百次同等规模的小训练运行要宝贵得多。所以我们需要做大,我们需要更集中,而不是分散。
Alessio Fanelli:第二,笔记本LM是如何制作的。
SWYX:那很有趣。
Alessio Fanelli:这是及时性的一个绝佳例子。这是每个人都关心的问题而且有很棒的嘉宾。它在社交媒体上流传甚广。
SWYX:而且Risa显然是一位明星,她几乎出现在这个节目的每一集、每一个播客中,而Isamah作为那个在音频模型上工作的人,能够和他交谈,对我们来说是一个很大的收获。而且人们应该回听一下他们是如何训练这个模型的。你把那种程度的关注放在任何模型上,你都能让它达到SOTA(State of the Art,即当前最佳水平)。而且感觉他们几乎没有进行评估(evals),他们只是进行了一场充满氛围(vibes)的小组会议。
Alessio Fanelli:节目最终归结为prompting。所有这些总结人们关心但又分散的事物的剧集,总是表现得很好。这对我们很有帮助。
SWYX:这帮助我们节省了很多小的提示环节。如果我们采访个别论文的作者,比如一篇十页的论文,那就只是一个不同的提示了,不如做一个概述性的调查那样有用。问题在于接下来该怎么办。我很惊讶它竟然那么受欢迎。我们是不是应该做其他方面的终极指南?然后做一个提示201?这是我们从这次成功尝试中学到的经验。
Alessio Fanelli:如果有人为我们做了这个工作,那就是Sander的优点。
SWYX:Sander确实非常非常优秀。所以他在这方面做了很多工作。我很期待明年能请他来谈谈更多关于提示的内容。下一个是那个“不适合工作场所”的话题还是“结构化输出“?
Alessio Fanelli:不是,下一个是”脑信托”。
SWYX:真的?
Alessio Fanelli:嗯。
SWYX:好吧。那我们列表有些不同。不过,没关系。
Alessio Fanelli:我看的是子列表上的数据。
SWYX:我明白了。所以那是包括了喜欢的数量,但是,我是按照下载量来看的。
Alessio Fanelli:这有点像是近期偏见,因为观众一直在增加,然后最近的节目获得了更多的观看。毫无疑问,那期“不适合工作的”节目非常受欢迎,很多人告诉我他们真的很喜欢,因为这是一个别人不常讨论的话题。“结构化输出”那期人们也很喜欢。那是同一类型的节目,是我经常提到的内容,也是新一年里最有趣的领域之一。
SWYX:模拟环境。WebSim,Wolsim,真的吗?
Alessio Fanelli:不是那种用例。而是你是怎么将它用于模型训练、Agents学习这些的。
SWYX:我必须提到我们最新的7小时长的关于模拟环境的节目,因为它可以说是WebSim和MobileSim的规模化、非常严肃的AGI实验室版本。如果你非常认真地看待这个问题,你就能得到Genie 2,这正是你需要的,接下来才能构建Sora以及其他的一切。所以模拟AI仍然处于夏天,依然在前进。我实际上有在反思这个问题,你觉得AI冬天已经到来了吗?或者说,根本就没有到来过?因为我们做过关于AI的寒冬的节目,我也在尝试寻找一些迹象,那种情况现在已经过去了。
Alessio Fanelli:虽然氛围上有那么一丝冬天的感觉,但实际上并没有真正的“冬天”。当你回顾年度总结时,你会发现每个月都有进展。实际上并没有经历所谓的冬天。可能只有一段“热潮冬季”,但我不确定那是否算真正的“冬天”。
SWYX:“规模扩展已遇到瓶颈”这个话题是2024年讨论的一个重要驱动力。
Alessio Fanelli:是的。
SWYX:经过一些结论,在欧洲会议上,我们也在“AI寒冬”的那集里指出过这个问题,但它绝对不是一个冬天。我们知道冬天是什么感觉,但这绝对不是冬天。所以一切都在顺利进行。每次人们觉得AI好像没有太多进展时,就回想一下去年这个时候的情况。然后了解从基准测试到前沿模型,再到OpenAI与其他公司之间的市场份额变化。然后还要覆盖一下我们标记出的各种讨论领域,看看讨论是如何演变的,以及我们现在理所当然的东西和一年前我们没有的东西。
Alessio Fanelli:今年AI领域已经有133轮融资,每轮融资金额超过一亿。
SWYX:这包括Databricks吗?
Alessio Fanelli:那是历史上最大的一轮风险投资,金额达到100亿美元。
Alessio Fanelli:那么Mosaic现在已经以大约20多亿美元的价格被收购,因为它大部分是股票,所以价格上涨了。 理论上是这样。
SWYX:所以你是以40亿美元的估值买入的?
Alessio Fanelli:差不多是43亿美元。
SWYX:我记得当时有一个问题,大家在讨论这个估值是否真实。
Alessio Fanelli:这就是为什么大家都感到沮丧。
SWYX:Databricks的私募估值是两年前的,谁知道这个东西现在值多少钱。现在它值600亿美元,比你想的还要多。
Alessio Fanelli:这一年真是疯狂,但我对明年很兴奋。现在Agent这个事情需要发生了,这真的是解锁的关键。
SWYX:我同意。明年将是明年将是Agent在实际应用中大展拳脚的一年。
Alessio Fanelli:我不能百分之百确定它会发生,但它必须发生。否则,明年肯定会进入寒冬。感谢大家的收听。新的一年见。
原视频:2024 Year in Review: The Big Scaling Debate, the Four Wars of AI, Top Themes and the Rise of Agents
https://www.youtube.com/watch?v=26PVzD707a8
编译:Yihan Chen Shihan Xu
(文:Z Potentials)
开源小模型不一定全是大型实验室做的,小模型也能有伟大的未来!机器学习的竞争激烈是事实,但工程师的努力才推动了这一切。Gartner把AI工程师的概念炒得很热,不知道他们是否真的了解AI工程师的工作?