

近年来,大型语言模型(LLMs)的发展速度令人惊叹,例如最新的 LLaMa 370B 模型不断刷新技术记录。然而,这些模型庞大的体量也给实际应用带来了难题:如何在内存有限的设备上运行这些模型?特别是像 GPU 这样的硬件设备,内存资源通常十分有限。

大型语言模型占用大量内存的根本原因是它们的复杂结构。模型内部通常由多层堆叠而成的网络组成,传统运行方式需要将整个模型一次性加载到设备内存中。然而,对于超大模型来说,这种方式几乎不可行。这种限制让普通设备无法使用先进的模型,导致这些技术更多依赖昂贵的专用硬件或云端解决方案。
为了解决这个问题,一种名为“分层推理”的技术应运而生。这项技术让 LLaMa 370B 能够在仅 4GB 内存的 GPU 上成功运行,从而打破了硬件的内存限制,为大型语言模型的实际应用开辟了新的可能。

分层推理:模型运行的新思路
分层推理的核心思想是将整个模型拆分成更小的组件,并逐层执行,而不是一次性加载整个模型。具体来说,在计算某一层时,只加载当前需要的部分,计算完成后再释放内存,为下一层腾出空间。
以 LLaMa 3 70B 为例,该模型的每一层大小大约为 1.6GB。分层推理允许模型逐层执行,避免一次性占用巨大内存。这种方法不仅降低了硬件需求,还能确保模型在资源有限的设备上正常运行。
这种技术特别适合大型语言模型,因为它们本质上是由多层 Transformer 结构组成的网络。通过分离各层的执行,分层推理实现了计算负载的分散和内存使用的优化。

AirLLM:让分层推理触手可及
尽管分层推理的概念简单,但实现起来并不容易,需要复杂的内存管理和高效的调度。为了解决这些技术难题,AirLLM 这一开源工具应运而生。它为开发者提供了简便的框架,帮助在内存受限的硬件上部署大型语言模型。
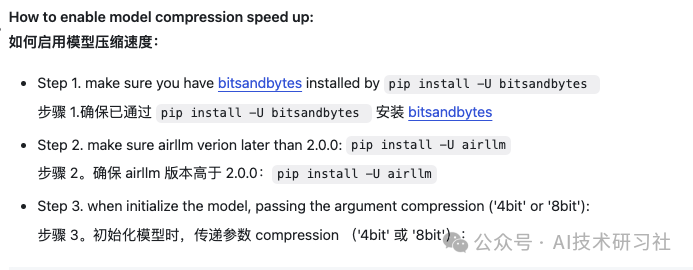
model = AutoModel.from_pretrained("garage-bAInd/Platypus2-70B-instruct",compression='4bit' # specify '8bit' for 8-bit block-wise quantization)
AirLLM 的主要特点
-
易于集成:AirLLM 与主流的深度学习框架(如 PyTorch、TensorFlow)无缝兼容。开发者无需重新学习复杂的运行机制,便可直接上手。
-
高效内存管理:AirLLM 能自动管理内存分配和释放,确保 GPU 在每一步计算时都有足够的资源。
-
优化性能:通过缓存和并行化技术,AirLLM 提升了分层推理的效率。例如,对于模型中重复使用的部分,它会缓存中间结果,避免重复计算。
分层推理如何实现
以下是 AirLLM 的典型工作流程:
-
加载模型:首先,将 LLaMa 370B 的权重文件加载到主存储中。AirLLM 会自动完成格式转换和预处理。
-
分层执行:模型加载后,AirLLM 按照模型架构逐层执行。在计算每一层时,只有当前层的数据会被加载到 GPU 内存中。
-
内存释放:计算完成后,AirLLM 会立即释放当前层的内存,为下一层执行准备空间。
-
输出传递:每一层的计算结果会传递给下一层,直到整个模型完成推理。
通过这种方法,即使是 LLaMa 370B 这样的超大模型,也能在仅有 4GB 内存的 GPU 上运行。
应用场景与优势
分层推理的出现让大型语言模型可以在资源受限的设备上运行,打开了更多应用场景:
- 边缘设备应用:智能手机、平板电脑等设备可以直接运行大型模型,实现离线操作,保护用户隐私。
- 实时 NLP 服务:例如文本生成、翻译、摘要和问答等任务,能够以低延迟完成。
- 本地 AI 助手:让对话式 AI 助手直接集成到本地设备中,提供更快、更流畅的用户体验。
持续优化与未来发展
虽然分层推理极大地降低了内存需求,但计算效率仍有提升空间。未来可以结合量化、剪枝等技术进一步优化模型的参数结构。此外,专用硬件的研发也能进一步提升分层推理的速度和能效。
另一个潜在方向是分布式计算和联邦学习,通过多设备协同来运行超大模型,支持个性化和定制化应用。
总结
分层推理和 AirLLM 的结合,成功在 4GB GPU 上运行了 LLaMa 370B 模型,展现了其巨大的潜力。这项技术不仅降低了大型语言模型的使用门槛,还为智能语言技术的普及提供了新可能。随着技术的进一步发展,我们有理由相信,未来的大型语言模型将更加贴近我们的日常生活,为更多用户带来价值和便利。
快速入门
首先,安装 airllm pip 包。
pip install airllm然后,初始化 AirLLMLlama2,传入正在使用的模型的 huggingface repo ID 或本地路径,就可以像普通的 transformer 模型一样进行推理了。
from airllm import AutoModelMAX_LENGTH = 128# could use hugging face model repo id:model = AutoModel.from_pretrained("garage-bAInd/Platypus2-70B-instruct")# or use model's local path...#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")input_text = ['What is the capital of United States?',#'I like',]input_tokens = model.tokenizer(input_text,return_tensors="pt",return_attention_mask=False,truncation=True,max_length=MAX_LENGTH,padding=False)generation_output = model.generate(input_tokens['input_ids'].cuda(),max_new_tokens=20,use_cache=True,return_dict_in_generate=True)output = model.tokenizer.decode(generation_output.sequences[0])print(output)
注意:在推理过程中,将首先对原始模型进行分解并逐层保存。请确保 huggingface 缓存目录中有足够的磁盘空间。


参考:
1.https://arxiv.org/pdf/2212.09720
2.https://github.com/lyogavin/airllm
(文:AI技术研习社)
分层推理简直完美!4GB GPU轻松应对大模型,这技术让AI离我们的生活更近一步。差距真的很大啊,差距越来越大!
分层推理让LLMs在4GB内存下也能运行,真·神器!
分层推理了解一下!让大模型也能在4G内存上运行,这科技简直逆天了