
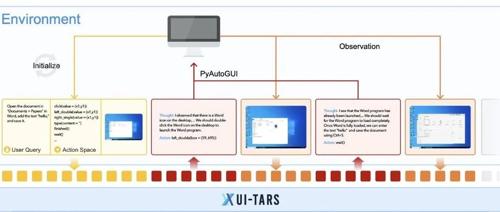
字节的可以直接操作图形界面的原生 GUI 智能体模型UI-TARS,类似于 Claude 的 Computer Use,可以只靠截取的界面图片就能理解并操作软件。
就像我们人类直接看手机或电脑屏幕一样,利用眼睛去“认”,再动手指去“点”。UI-TARS学会了从图片中辨别按钮、输入框、下拉菜单等各种元素,也能知道“这个图标大概率是搜索按钮”“这个区域是文本框”等信息。
UI-TARS具备四个关键能力,来模拟人类使用电脑或手机的过程:
-
感知(Perception):从截图中识别出界面有哪些元素、它们的文字、图标、位置等。 -
行动(Action):能够发出点击、滚动、输入文字、拖拽等具体操作指令。 -
推理(Reasoning):类似于人类的“思考”过程,尤其是比较复杂或多步骤的任务,需要先策划好要怎么做,再一步步执行。如果中途出错,还要思考如何纠正或绕过困难。 -
记忆(Memory):对过去的操作和获得的信息进行“记忆”,好让下一步决策更准确。
过去很多尝试,往往是把各种工具模块拼在一起——比如:先用某个模型识别界面元素,再把文字描述交给另一个大语言模型推理,然后再用一个脚本执行操作。这些拼装好的框架对特定场景有效,但迁移性差。UI-TARS 的思路是直接使用一个“大模型”进行端到端学习,把对界面截图的理解、对任务目标的分析以及生成下一步点击指令的过程整合在一起,大大提升了灵活性与稳健性。
UI-TARS 不仅有直接的“直觉式”反应(称为System-1思维),还纳入了更深度的“System-2思维”,或者说“慢思考”。它会在做出点击等动作前,先进行多步推理,比如:
“先打开浏览器 -> 输入网址 -> 搜索再点击下载链接 -> 安装软件 -> 打开软件”
如果中途失败或走错,它会像人一样反思错误、再尝试新的方案,避免一直卡在同一个问题上。
至于效果,论文上说在某些测试上超过了 Claude 和 GPT-4o,但估计还是得看实际使用场景,所以还是建议有兴趣的自己试试看。



参考文献:
[1] 开源项目地址: https://github.com/bytedance/UI-TARS
[2] Huagging face:https://huggingface.co/bytedance-research/UI-TARS-7B-SFT
(文:NLP工程化)
UI-TARS这操作属实6!直接端到端学习,比之前拼接框架强多了!记得试试看,说不定能拉满!