


英伟达不久前宣布了有关 GeForce RTX 5090、GeForce RTX 5080、GeForce RTX 5070 Ti 和 GeForce RTX 5070 等 GPU 的一些新细节,这些细节与技术和功能相关。某些信息是全新的,某些信息是对已知内容的补充,本文带来了新的基准测试。
英伟达之前提供的基准性能测试对比的是 GeForce RTX 5000 系列的三个型号与它们的 4000 系列基本型号,现在又加入了 4000 系列 Super 型号的对比。之前的 4070 和 4070 Ti 的 Super 型号在性能方面有所提升,后者的显存规格也增强了。
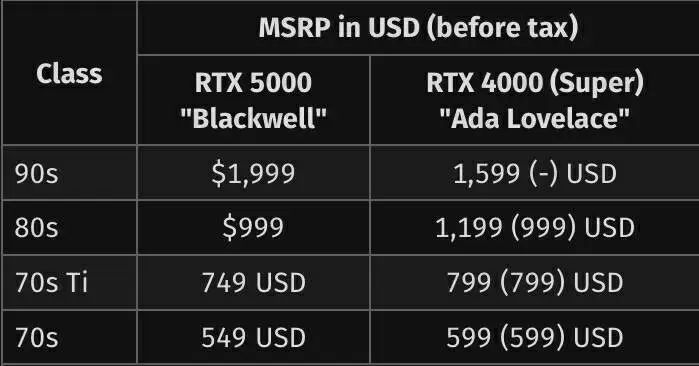
此外,官方的 RTX 5000 与 RTX 4000 的价格对比现在也加入了与 Super 型号的对比,英伟达已经通过这些版本大幅降低了之前备受批评的 RTX 4080 的定价。虽然 RTX 5080 的起价将比 RTX 4080 便宜很多,但与 RTX 4080 Super 相比就不一样了。
对于游戏玩家来说,Blackwell 一代最重要的两个新特性一个是 DLSS 4,它具有新的神经网络能力,包括 Transformer 模型和 DLSS 多帧生成(MFG),可提高图像质量和性能;另一个是 Reflex 2,旨在通过一种新方法控制延迟。除了 DLSS 4 多帧生成(现在它通过 AI 来生成三个中间帧,上一代是一个)之外,所有新的 DLSS 4 和 Reflex 2 特性和增强功能都将立即或在可预见的未来被旧款 GeForce RTX 显卡支持。
本文中展示的新信息指的是 DLSS 4 和 Reflex 2 以外的特性。详情如下。
借助 Blackwell,英伟达希望将更多 AI 特性带入不支持 DLSS 的游戏。 因此,所有 GeForce RTX 5000 显卡都支持“神经着色器”,它们是普通着色器代码中的 AI 程序,以前没有。如果没有特殊的附加 API,以前是不可能在游戏中使用神经网络的。
神经着色器现在应该会改变这种情况。着色器程序的 AI 代码是在 Tensor 核心上计算的,实际渲染仍由普通的 FP32 ALU 执行。
新的神经着色器也将进入 DirectX,因此可能被所有显卡制造商使用。微软称该特性为“协作向量”,应该很快就会出现在 Windows 中。
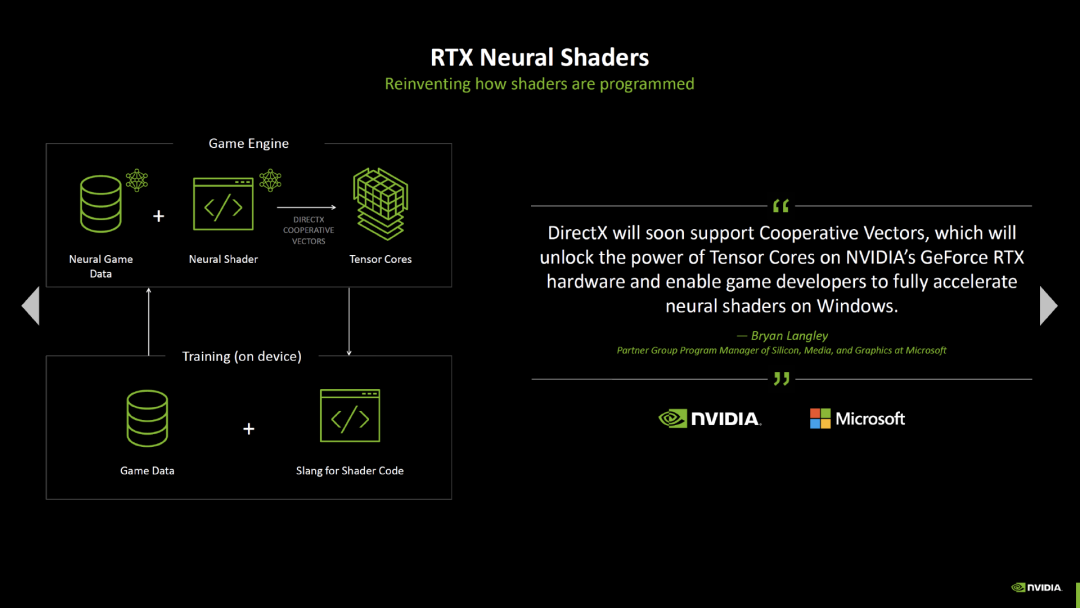
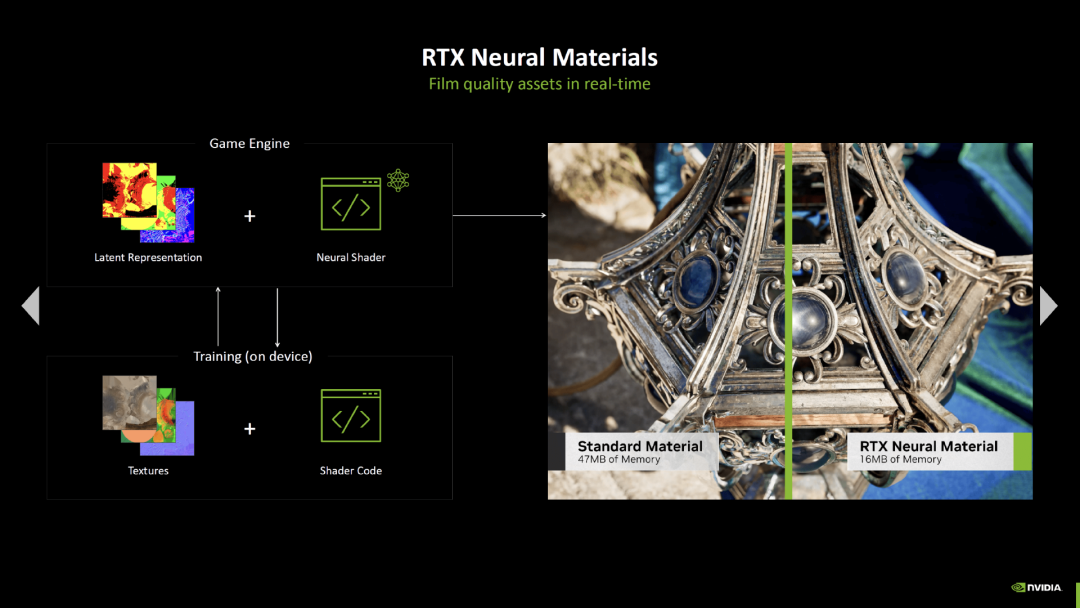
英伟达还首次介绍了神经着色器的能力。这被称为“RTX 神经材质”,旨在通过开发人员预训练的材质实现电影级的物体表面画质,同时降低内存消耗。“RTX 神经辐射缓存”旨在使用实时自学习神经网络,通过路径跟踪提供间接照明,每个像素反弹一次光线。
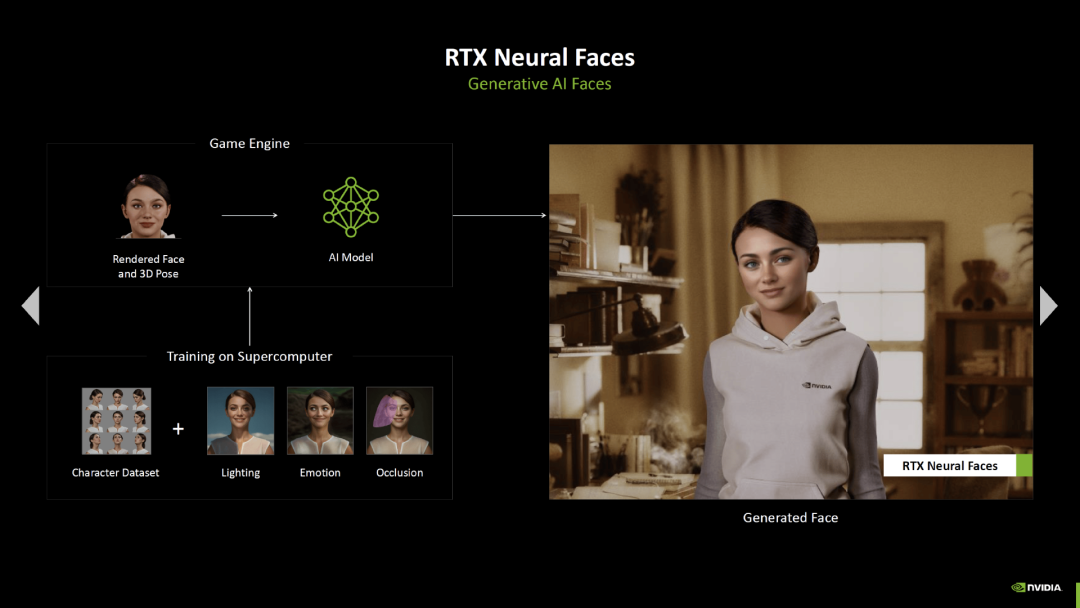
所有类型的元素表示也可以通过神经着色器得到改进。英伟达将皮肤表示称为“RTX 皮肤”,将面部表示称为“RTX 神经面部”。面部照明和表现的情绪都要在超级计算机上预训练,然后使用显卡上的神经网络为游戏场景实现和渲染。
下一个是“RTX 头发”,头发表示可以用更美观、更节省资源的方式实现。与传统的光线追踪渲染方法相比,RTX 头发只需要三分之一的数据需求,这可以节省显存,同时提高性能。


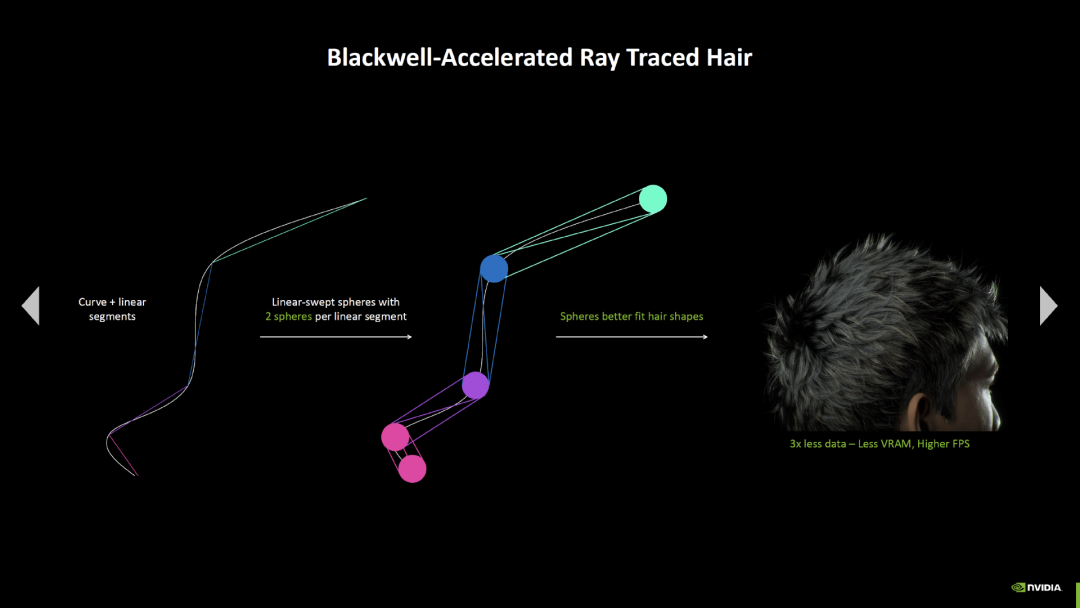
左右滑动查看更多
英伟达没有透露关于新一代 GPU 架构的新信息,这可能是因为与 Ada Lovelace 相比,新架构没有太大变化。
也就是说,Blackwell 的总体结构似乎与 Ada Lovelace 没什么差别,改进主要是规模方面的扩展,有了更多计算单元。随着流式多处理器的发展,英伟达在过去几代架构中已经改变了一些东西。
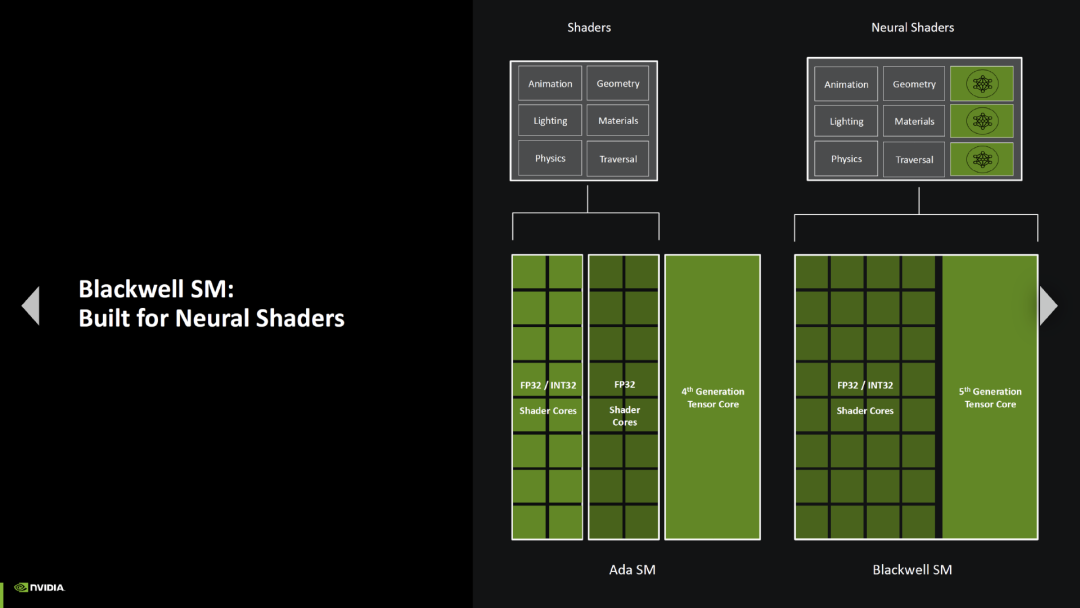

例如,Turing 架构的流式多处理器(SM)可以每时钟执行 64 次浮点和 64 次整数计算,而 Ampere 和 Ada Lovelace 则分别是 128 次浮点或 64 次浮点和 64 次整数计算。在 Blackwell 上,英伟达将 Turing 和 Ampere 的架构结合在一起,新的 SM 可以执行 128 次浮点或 128 次整数计算,于是整数方面也得到了相应的改进。同样,新 SM 也可以同时执行混合的浮点和整数运算,尽管目前尚不清楚是否只有固定的 64/64 比率,或者是否可以动态配置。
这正是英伟达想要做的事情,因为它更适合神经着色器程序的要求。
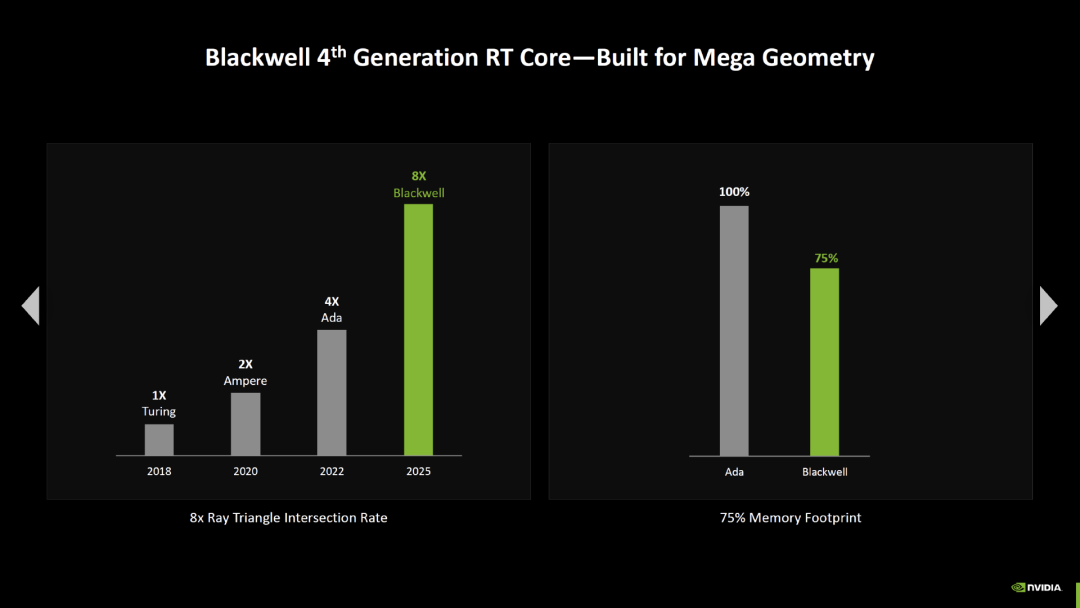
Blackwell 配备了第四代光线追踪单元,与 Ada Lovelace 相比,交叉率翻了一番。这意味着新单元能够以之前两倍的速度检查光束是否击中了多边形。自 Turing 以来,英伟达的每一代新 RT 核心都将交叉率翻一番。
Ada Lovelace 引入的着色器执行重排序(SER)功能现在在 Blackwell 上的速度翻番了。除了经典的着色器程序外,Blackwell 还应该能够对神经着色器进行排序并在张量核心上做计算准备。SER 必须得到游戏的明确支持,并且主要提高的是完整光线追踪游戏的性能。

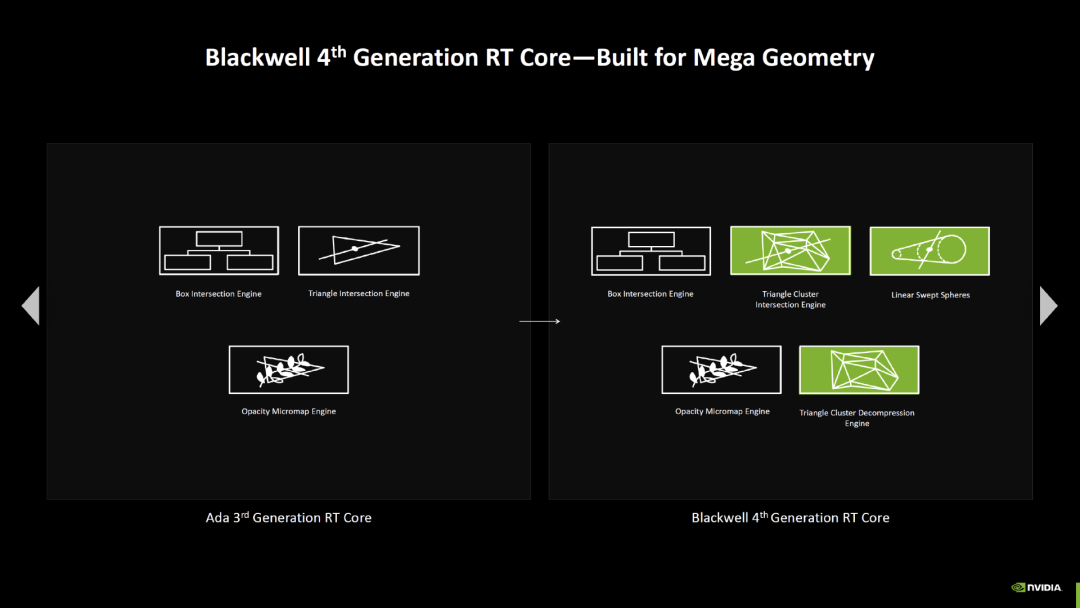
左右滑动查看更多
此外,Blackwell 上的光线追踪所需的显存应该比 Ada Lovelace 少 25%。
Tensor 核心在 Blackwell 中升级到了第五代,虽然它们在相同精度下的数据吞吐量不如 Ada Lovelace,但可以处理新的数据格式。RTX 4000 只能处理到 FP8,RTX 5000 现在也支持了 FP4。因此,如果矩阵计算以 FP4 精度运行,Blackwell 可以执行的操作数是 Ada Lovelace 的两倍。
Blackwell 还配备了一个新的“AI 管理处理器”,旨在改善渲染 ALU、RT 单元和 Tensor 核心同时工作时的协作操作。例如,由于 AI 管理处理器可以对单元进行优先级排序,帧生成的帧节奏应该比之前没有这个管理处理器时更好了。
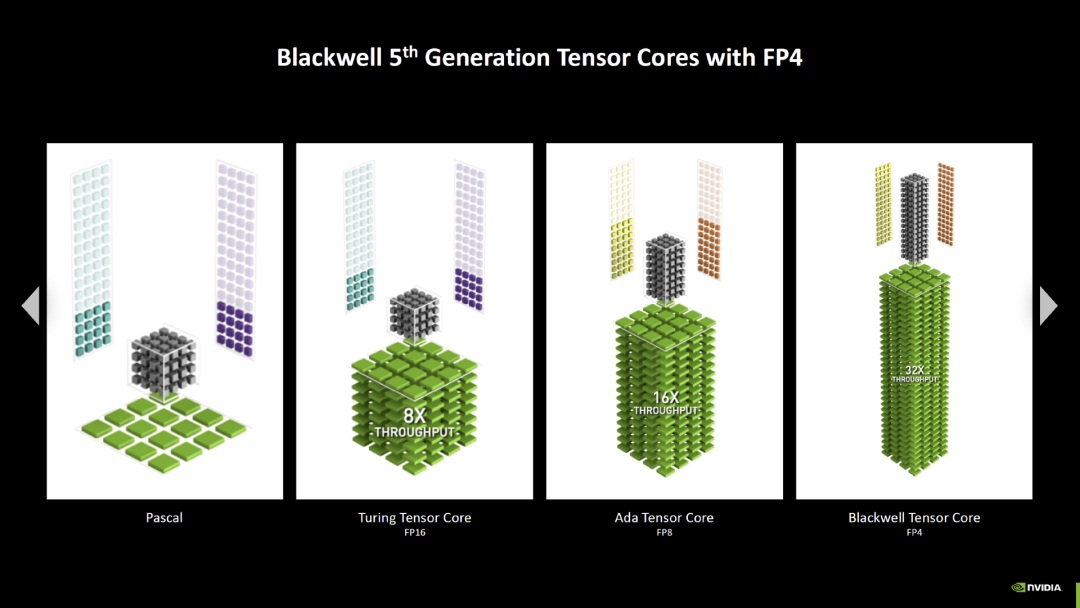
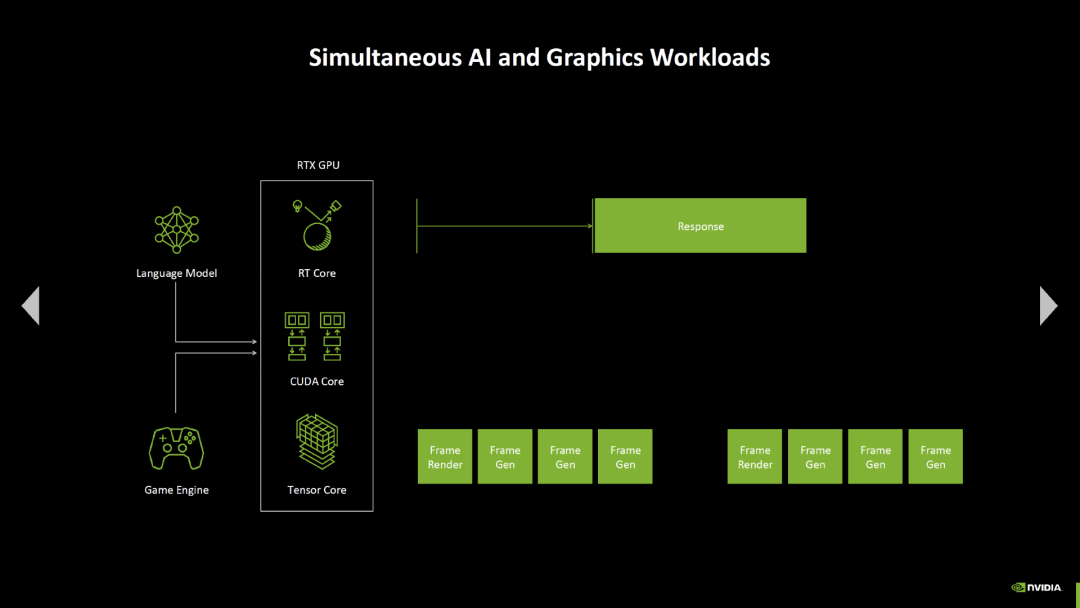
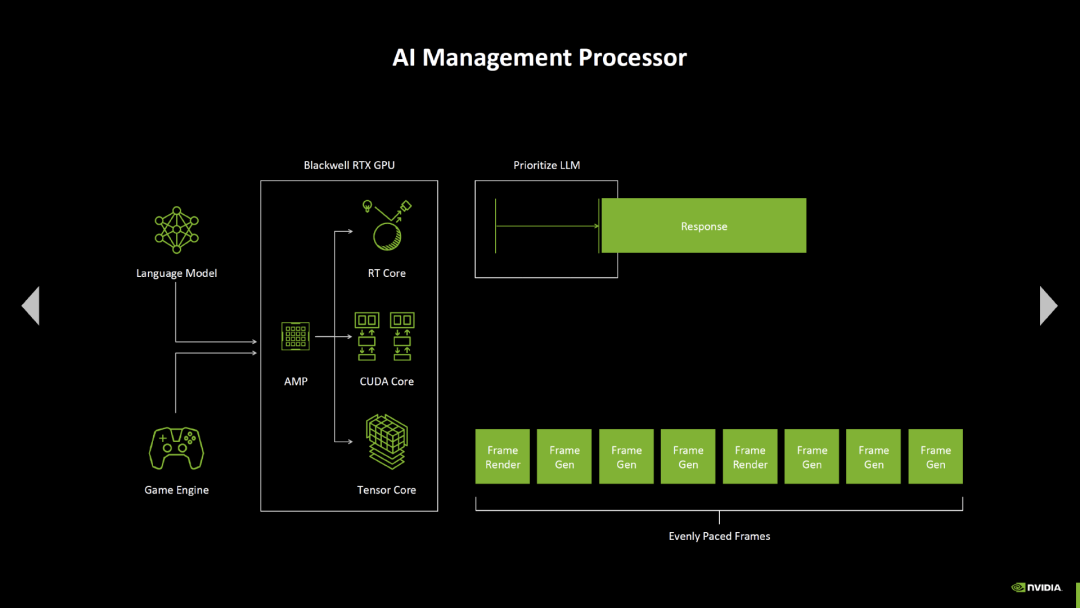
左右滑动查看更多
所有 GeForce RTX 5000 显卡都配备了新的显示引擎,支持数据速率为 UHBR20 的 DisplayPort 2.1,传输带宽 80 Gbps。对于 HDMI,它依旧支持 2.1 标准。
Blackwell 的显示引擎还支持所谓的“翻转测光”,这在 DLSS 多帧生成中很重要。使用翻转测光时,不再是 CPU 决定图像输出的节奏,而是显卡的显示引擎来决定,这意味着使用 DLSS MFG 应该可以实现良好的帧节奏。
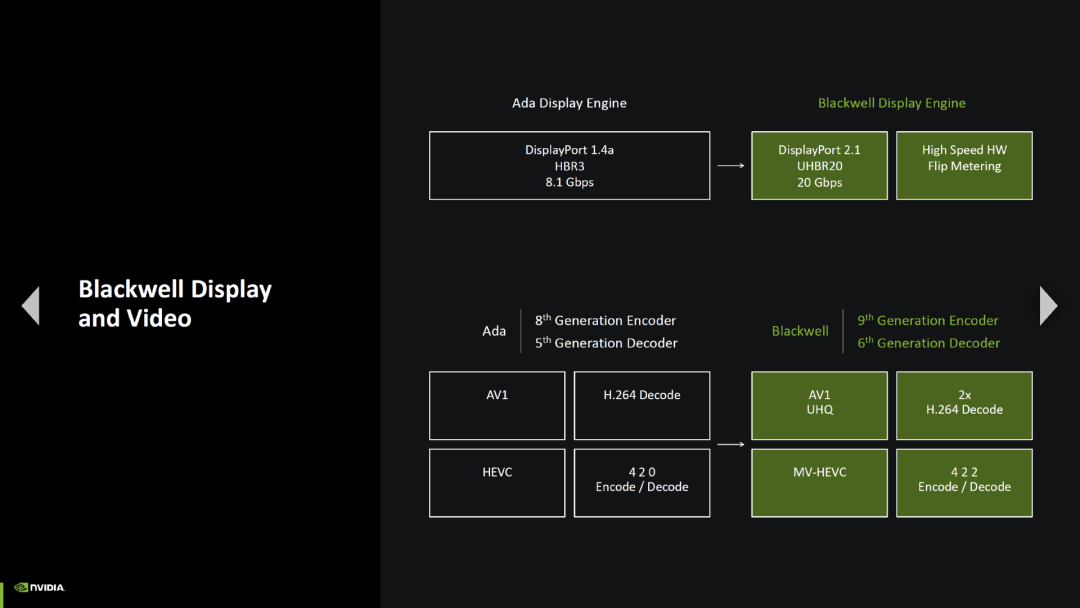
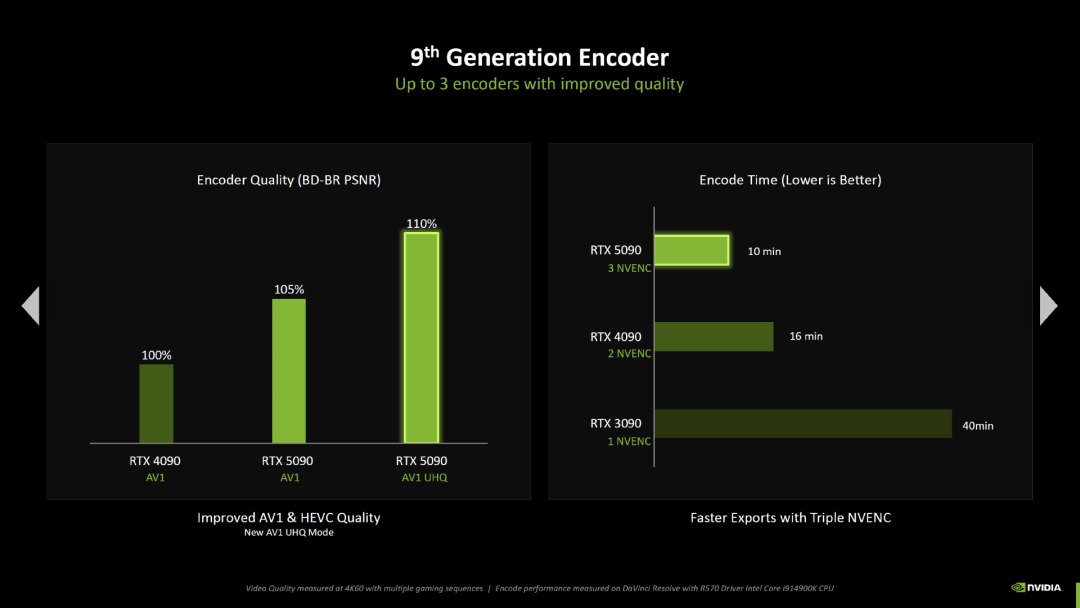
Blackwell 配备了第九代编码器和第六代解码器单元,可以加速 AV1 编解码器的新的超高质量预设,MV-HEVC(多视角高效视频编码)也是如此,后者用于 VR 头显上的 3D 内容播放。RTX 5000 的新增功能是加速色彩采样为 4:2:2 的视频,而 Ada Lovelace 只能处理 4:2:0。
英伟达不仅希望提高编码和解码器的质量,还希望通过增加单元数量来进一步提高性能。GeForce RTX 4000 显卡首次配备了 2 个 NVENC 单元用于编码,而部分 RTX 5000 GPU 配备了 3 个 NVENC 单元。借助新的 GPU 架构(BD-BR PSNR),图像质量提高了 10%,而且借助额外的第三个 NVENC 单元,GeForce RTX 5090 可以在 10 分钟内编码一段视频,而 GeForce RTX 4090 则需要 16 分钟。此外,部分 RTX 5000 显卡首次配备 2 个解码器单元,而 GeForce RTX 4000 一代都只有一个解码器。

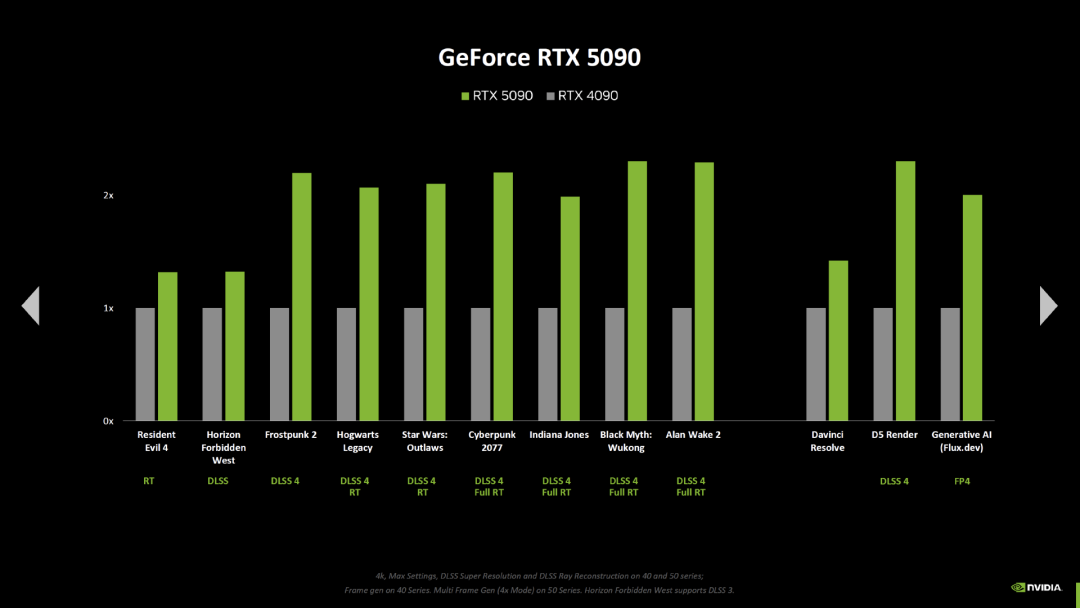
英伟达还展示了新的游戏基准测试,对比了 GeForce RTX 5090 与 GeForce RTX 4090。在大多数测试中,英伟达依旧用的是 RTX 5000 上的 DLSS 4 与多帧生成(三个中间帧)设置,对比 RTX 4000 上的 DLSS 4 与帧生成(一个中间帧)设置,这些游戏包括了《生化危机 4》(光线追踪,但没有 DLSS)和《地平线:西部禁域》(没有光线追踪,DLSS 超级分辨率,没有 DLSS (M)FG),但有两个新结果有相同的设置。
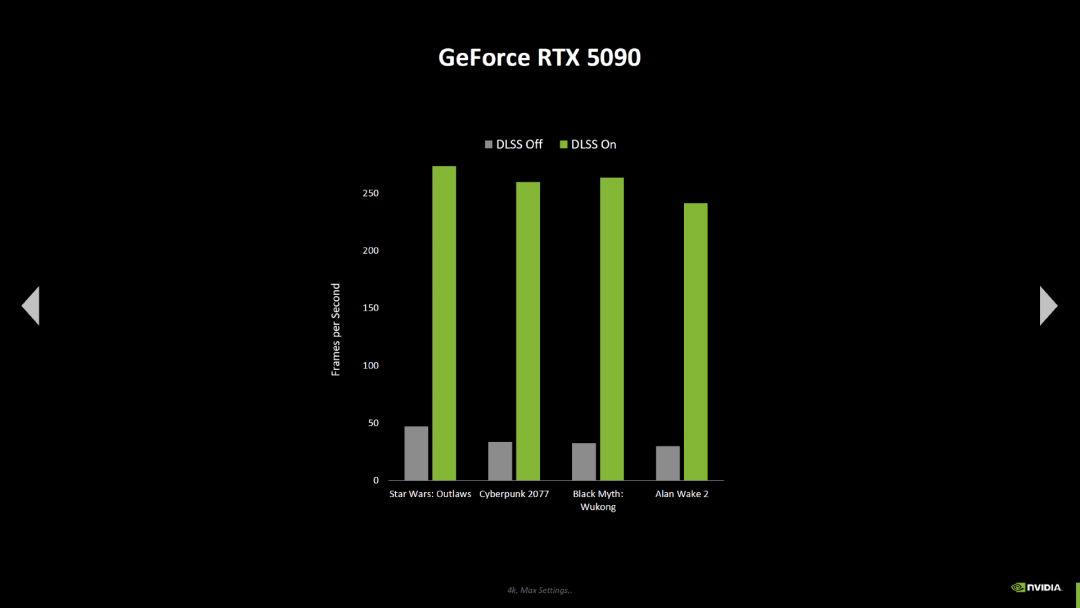
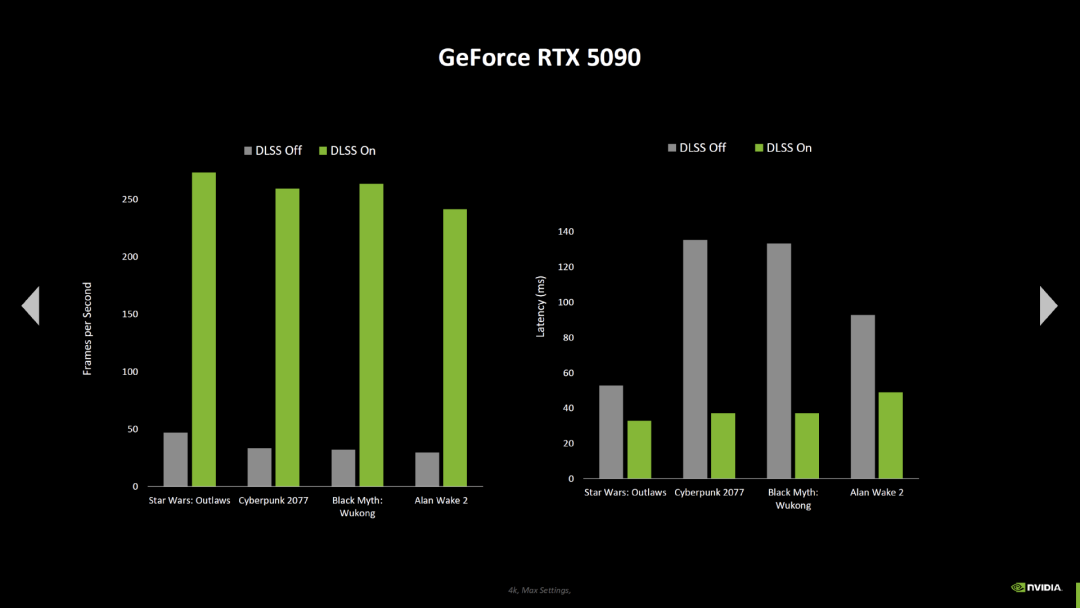
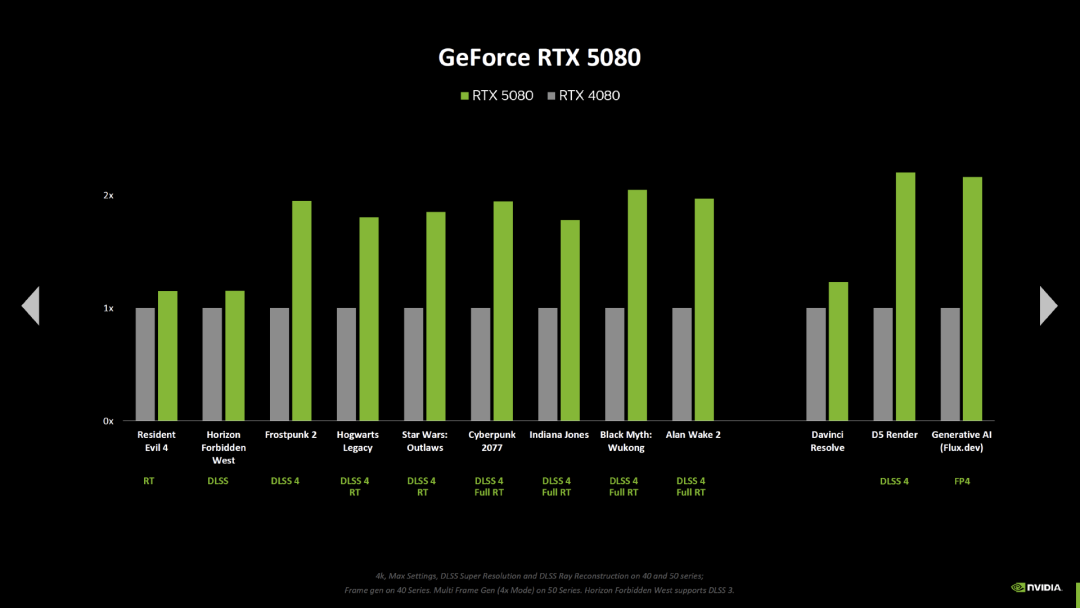

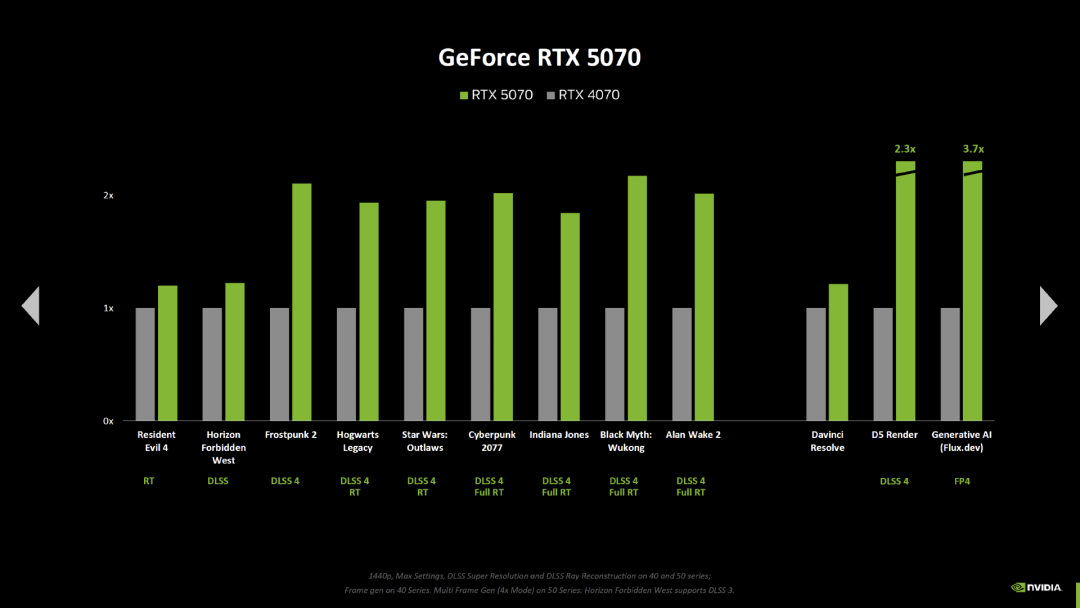
左右滑动查看更多
《生化危机 4》和《地平线:西部禁域》的两个基准测试可以推断出以下改进:
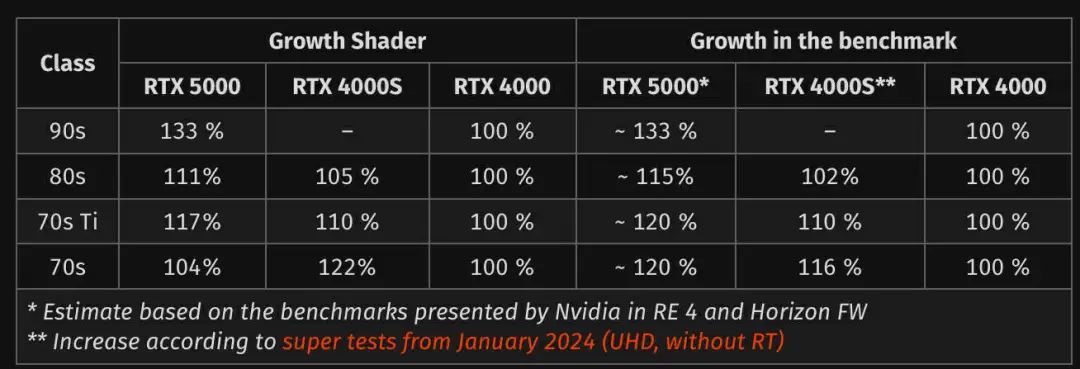
RTX 5070 的性能显然比其他几款型号的表现更好,它的实际性能增幅比着色器规模增幅更大。显存带宽应该没变,但 TDP 却显著增加。不过目前还不能说新一代架构的性能整体上有了大幅提升。
英伟达目前只将新一代 GPU 与 GeForce RTX-40 系列的原始版本做了对比。在此基础上,看起来 5080 的提升是最小的。但如果对比的是上一代的 Super 型号,情况就会发生变化:因为 4070 Super 和 4070 Ti Super 带来了显著更高的性能,而 4080 Super 相比 4080 基本原地踏步。这样对比的话,5080 相比上代 Super 版本的性能增幅最明显,而 5070 对比 4070 Super 几乎没什么改进。不管怎样,所有新一代 GPU 对比上代 Super 版本时,性能增幅都缩小了。
GeForce RTX 5090 和 GeForce RTX 5080 上新的 Founders Edition 散热器还有一些新细节。英伟达将此称为“双流”设计,因为两个风扇都可以将空气吹过散热器,不会让空气被 PCB 阻碍。上一代的 RTX-4000 高端型号中,只有后一个风扇可以做到这一点,因为 PCB 挡住了前面的风扇。所以风扇不会将空气吹过散热片,而是会通过后挡板吹出去,这样就会被 PCB 阻挡了。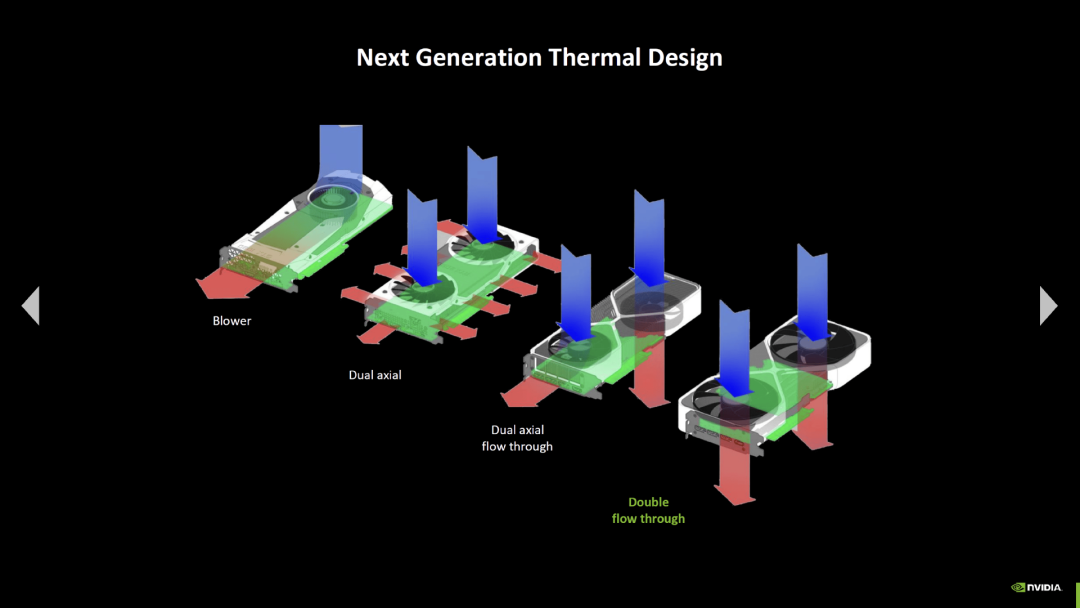
英伟达表示,双流式设计应该会比之前的设计实现更好的散热性能,但 英伟达只将新的双槽设计与 RTX 4000 一代的双槽设计做了对比,而没有与 GeForce RTX 4080 和 GeForce RTX 4090 更大更好的 3 槽设计做对比。
在 2 槽位的对比中,双流式散热器的性能比前代产品好得多,即使是 600 瓦的功率下也应该能比 400 瓦负载的旧散热器更安静,同时几乎不会比旧散热器在 300 瓦负载时的噪音更大——这可是非常明显的差别。在 400 瓦的负载下,新的散热器可以比旧款在 200 瓦负载时的噪音稍低一些。
据传言,RTX 5090 的测试禁令将于 1 月 24 日解除,RTX 5080 的测试禁令将于 1 月 29 日(入门级 UPV 卡)或 1 月 30 日(更昂贵的型号)解除。两个系列的上市日期都是 1 月 30 日。
GeForce RTX 5000 与 RTX 4000 的厂商建议零售价对比:
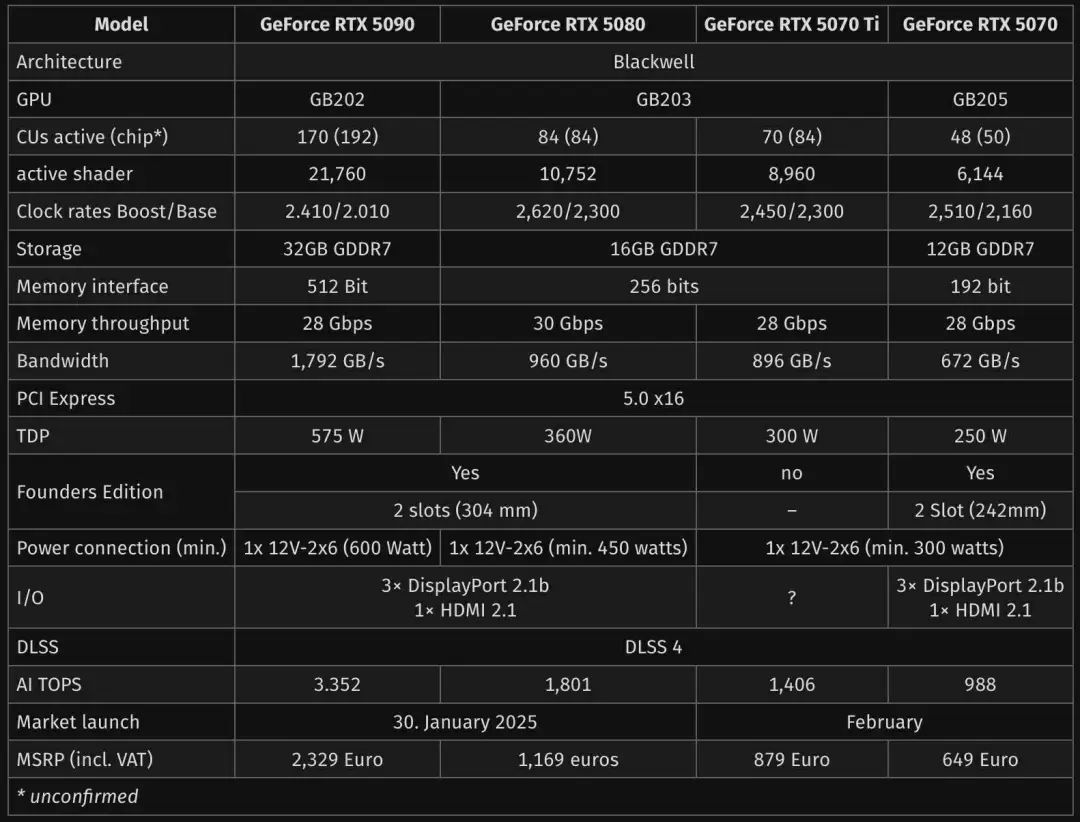
RTX 5000 核心信息表:
原文链接:
https://www.computerbase.de/artikel/grafikkarten/geforce-rtx-5090-5080-5070-ti-5070-details.91036/
声明:本文为 InfoQ 翻译,未经许可禁止转载。
(文:AI前线)
黑盒子里藏着光追的秘密, DLSS 的终极考验来了!