1 月 24 日,年底这波国内大模型的发布季,加入一名新选手——百川智能。
-
国内首个全场景深度思考模型Baichuan-M1-preview
-
行业首个开源医疗增强大模型Baichuan-M1-14B
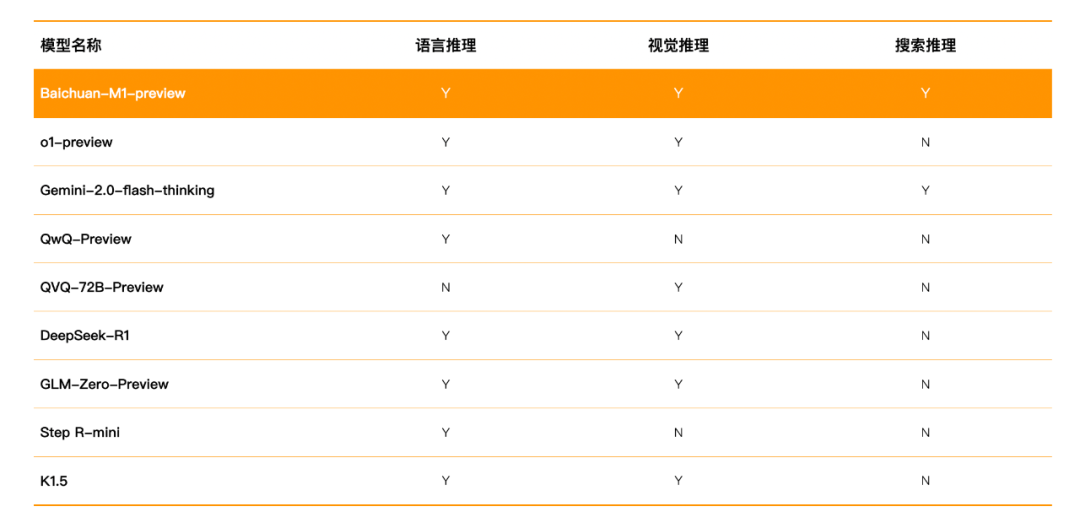
Baichuan-M1-preview是国内目前唯一同时具备语言、视觉和搜索三大领域推理能力的模型。在数学、代码等多个权威评测中,Baichuan-M1-preview的表现均超越了o1-preview。
此外,它还解锁了“医疗循证模式”,实现了从证据检索到深度推理的完整端到端服务,能够快速、精准地回答医疗临床、科研问题。
并且Baichuan-M1-preview发布即可用。现已正式上线到了百小应中。
在深度思考模式下百小应不仅能准确解答数学、代码、逻辑推理等问题。
即使面对复杂医疗问题,也可以像资深医疗专家一样,通过深度思考构建严谨的医学推理过程,为用户提供全面的疾病分析和个性化健康建议。
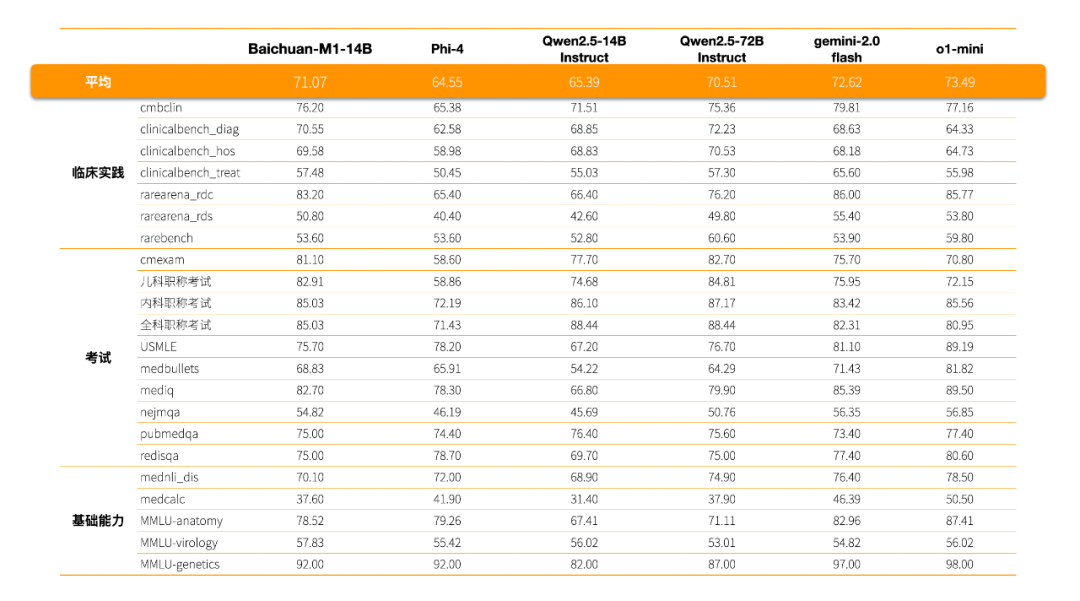
而Baichuan-M1-14B则是Baichuan-M1-preview的小尺寸版本,同时也是行业首个开源的医疗增强大模型,它的医疗能力超越了更大参数量的Qwen2.5-72B,与o1-mini相差无几。
Github:https:https//github.com/baichuan-inc/Baichuan-M1-14B
Huggingface(base):https://huggingface.co/baichuan-inc/Baichuan-M1-14B-Base
Huggingface(Instruct):https://huggingface.co/baichuan-inc/Baichuan-M1-14B-Instruct
NPU版本支持BF16推理:https://modelers.cn/models/MindIE/Baichuan-M1-14B-Base
01
Baichuan-M1-preview:
多项能力超越o1-preview,
解锁医疗循证模式
作为国内首个能力全面的全场景深度思考模型,Baichuan-M1-preview具备强大的语言推理、视觉推理及搜索推理能力。
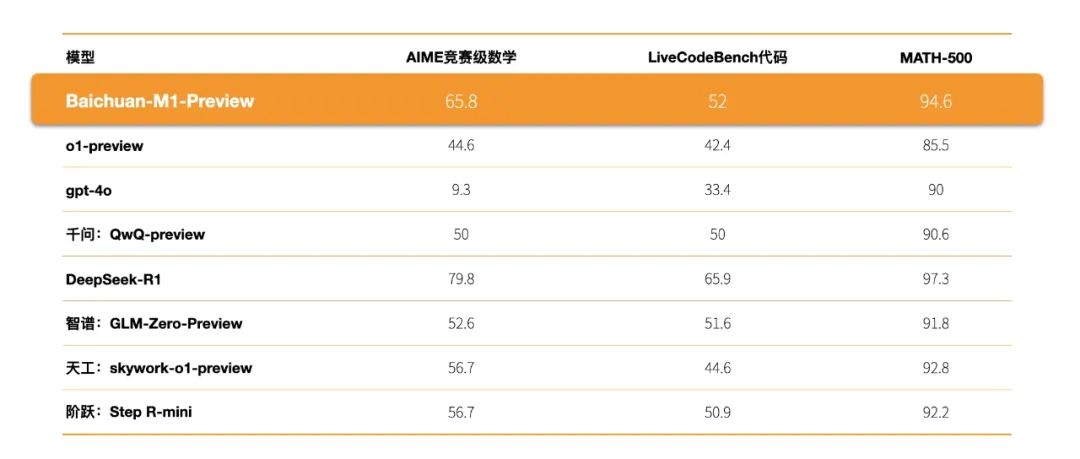
语言推理方面,其在AIME 和 Math 等数学基准测试,以及 LiveCodeBench 代码任务上的成绩均超越了o1-preview等模型。
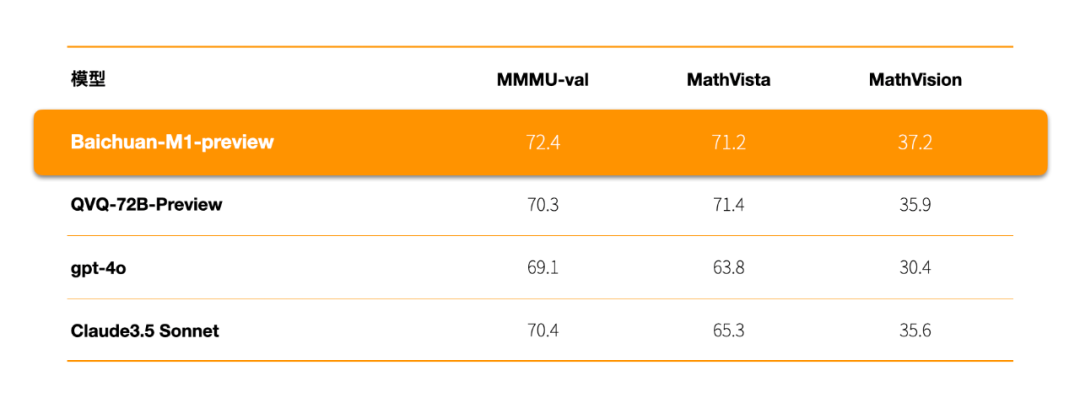
视觉推理能力方面,在MMMU-val、MathVista等权威评测中的成绩,超越了GPT-4o、Claude3.5 Sonnet、QVQ-72B-Preview等模型。
众所周知,成立以来我们一直专注于AI医疗领域。模型的医疗能力也一直是我们的强项,本次的Baichuan-M1-preview也不例外,除了推理能力全面之外,相比其他模型,它还有一大亮点——“医疗循证模式”。
那么什么是“医疗循证模式”呢?简单来说就是,在医学问题推理上借鉴了“循证医学”的理念,在面对复杂医学问题时,Baichuan-M1-preview会将专业可靠的医疗知识作为推理依据,帮助用户做出最佳的医疗决策。
虽然听起来很简单,但是要想实现这一模式必须得先有海量可靠的“专业医学知识”,让模型有“据”可循。
对此,我们自建了涵盖亿级条目的循证医学知识库,囊括了国内外海量医学论文、权威指南、专家共识、疾病与症状解析、药品说明等专业医疗内容,并以天为单位进行动态更新,及时收录医疗领域的新突破、新进展。
但有了循证医学知识库还不够,医学知识磅礴复杂,其中有很多医学知识、医学理论等信息并不一致,甚至有些是冲突的,尤其在互联网上,权威医疗信息和医疗谣言真假难辨,想要问答结果准确,必须要解决“证据”可靠性的问题。
这就不得不提到,医疗循证模式的另一个能力“证据分级”。它能运用医学知识和证据评估标准,对证据进行多层分级,并对不同权威等级的证据进行专业分析与整合,识别各类权威信息的来源和可信度,避免因信息混杂导致的误判,从而形成全面、连贯的医学结论。
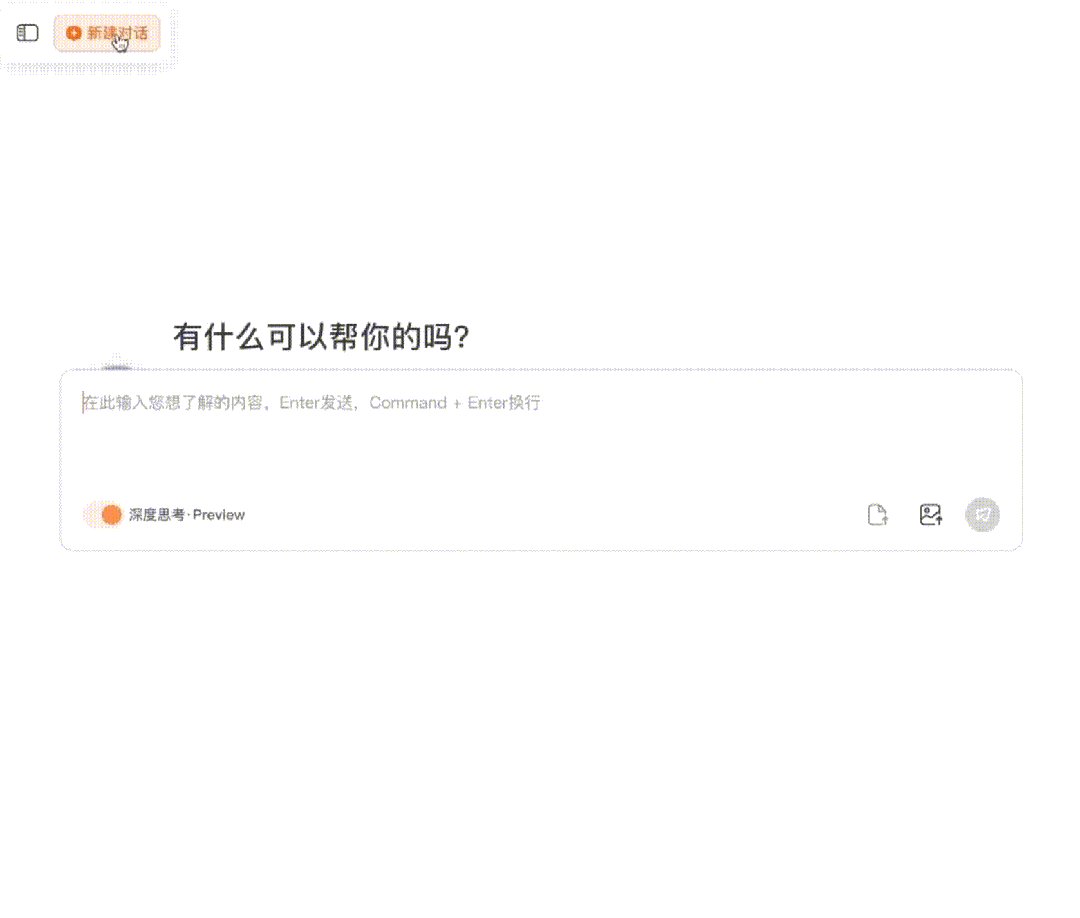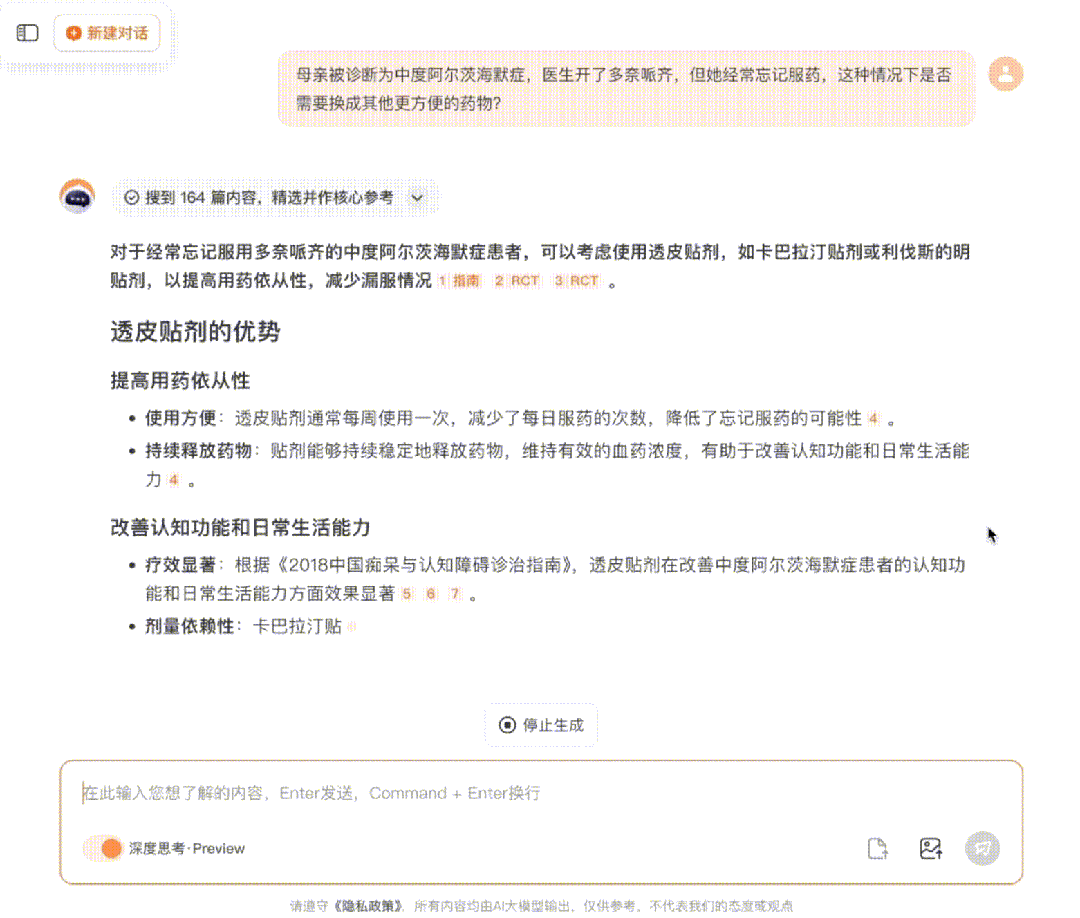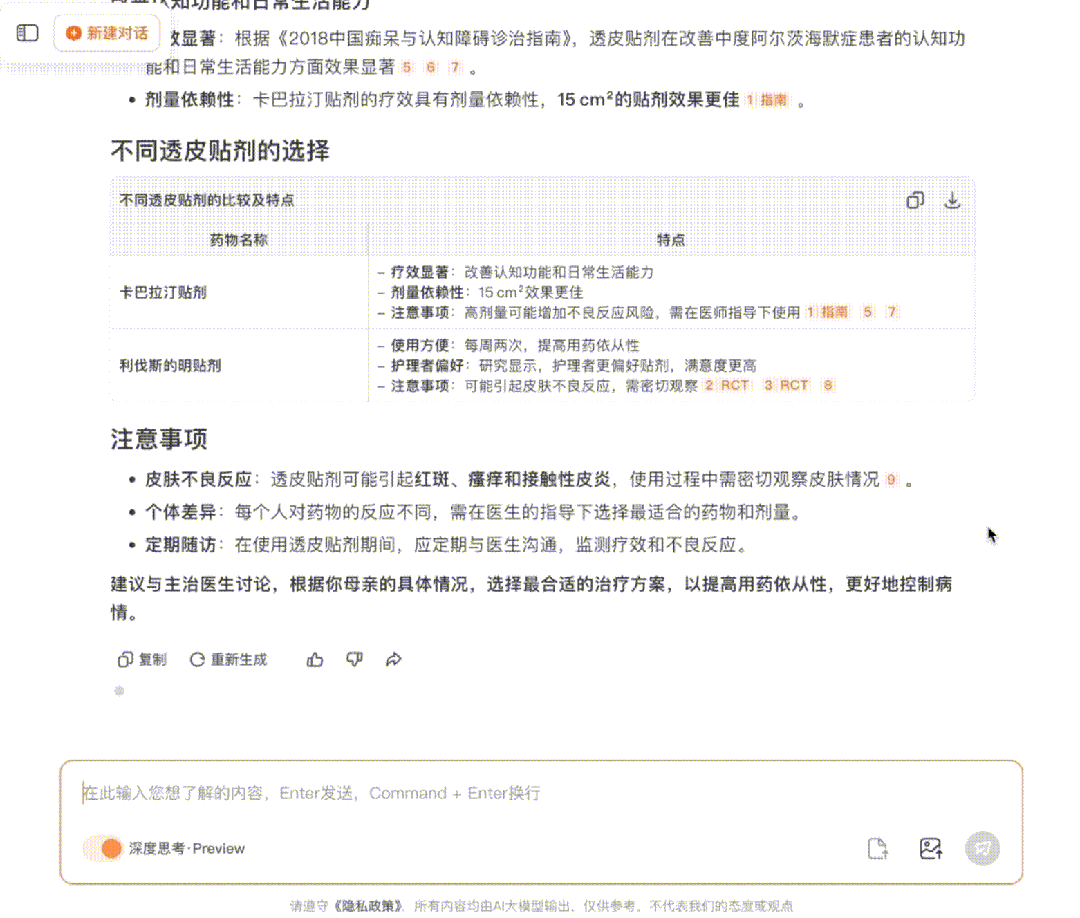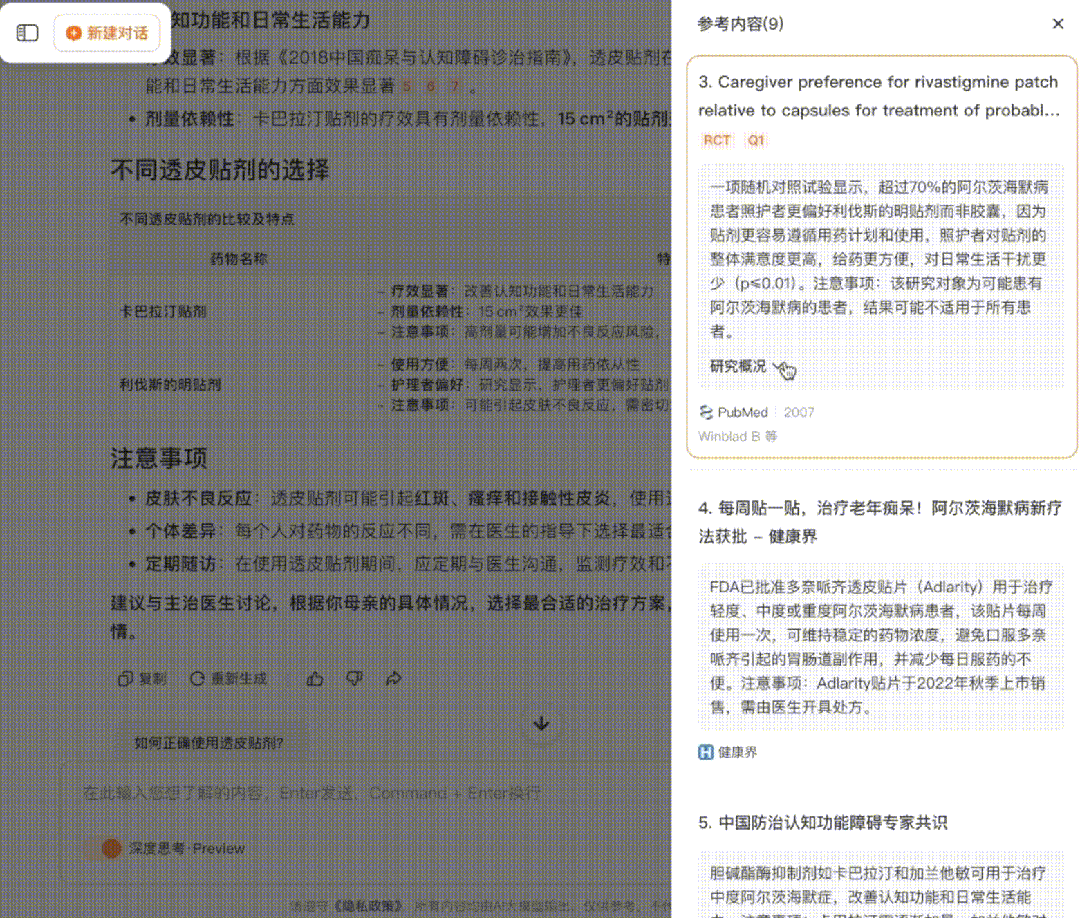
解决了以上两个问题之后,遇到复杂的医疗问题时,Baichuan-M1-preview便能够自主调用搜索能力,在循证医学知识库中和互联网上实时获取权威医学证据、临床指南和研究进展,然后通过丰富医学证据进行可靠、准确的医学推理,最终为用户提供可信赖的医疗答案。
无论是医生面对复杂病案,还是患者寻求权威建议,它都能通过“摆事实、讲道理”的循证方式提供言之有物、有理有据的解答。
不仅能在临床场景中帮助医生提升诊疗效率,在医学科研场景中大幅缩短科研探索时间,还能帮助普通用户更好地理解自身健康状况,帮助患者科学管理生活方式,提升治疗效果。
02
Baichuan-M1-14B:
行业首个开源医疗增强通用大模型 ,
医疗能力超越Qwen2.5-72B
一花独放不是春,百花齐放春满园。AI医疗是一项事关大众健康,利国利民,涉及技术领域众多,需要全社会共同努力的伟大事业。
为了推动AI技术在医疗领域的创新发展,增强AI医疗技术的透明度和可信性,提高医疗服务的可及性,繁荣AI医疗生态,我们开源了Baichuan-M1的小尺寸版本模型Baichuan-M1-14B。
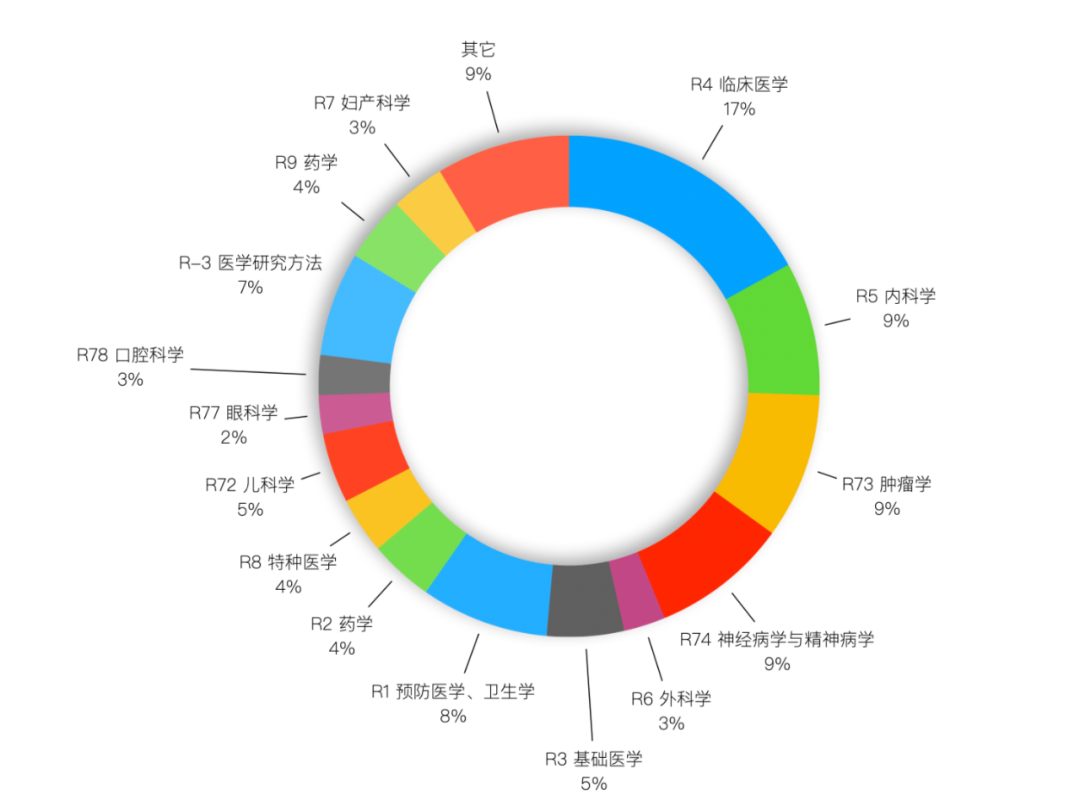
作为行业首个医疗增强开源模型,Baichuan-M1-14B的表现非常优异,不仅在cmexam、clinicalbench_hos、clinicalbench_hos、erke等权威医学知识和临床能力评测的成绩超越了更大参数量的Qwen2.5-72B-Instruct,与o1-mini也相差无几。
为了提升Baichuan-M1-14B的医疗能力,我们多管齐下做了大量的优化、创新工作。
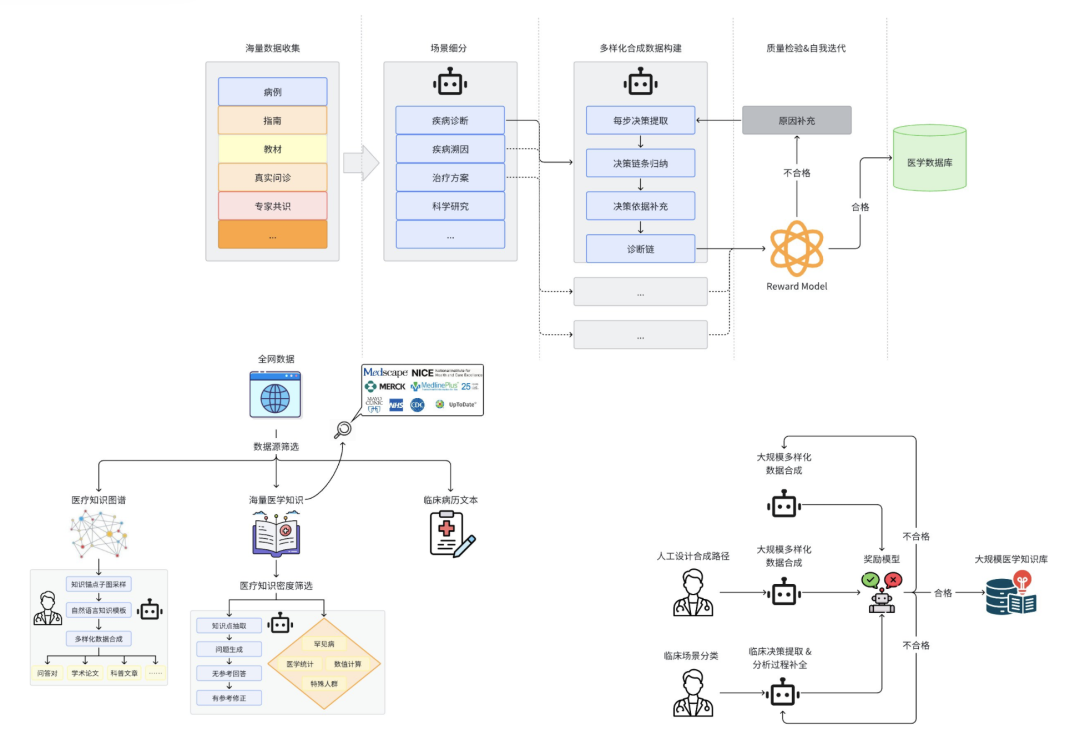
数据收集方面:面向细分医疗场景,收集了万亿级 token 的严肃医疗数据,涵盖了千万级的中/英文专业医疗论文、院内真实中/英文医疗病例,亿级的医疗问答、医疗问诊、临床数据等,还对全网数据进行了包括医疗科室、医疗内容以及医疗价值在内的分类评估,确保模型能学习到有价值且全面的医疗知识。
合成数据方面:针对病例、医学教材、医学指南等不同类别的高质量医疗数据,生成了超100B token包含了医疗复杂决策推理链条、决策依据以及问答对形式的多样化数据,进一步强化了Baichuan-M1-14B的医学知识能力和医疗推理能力。
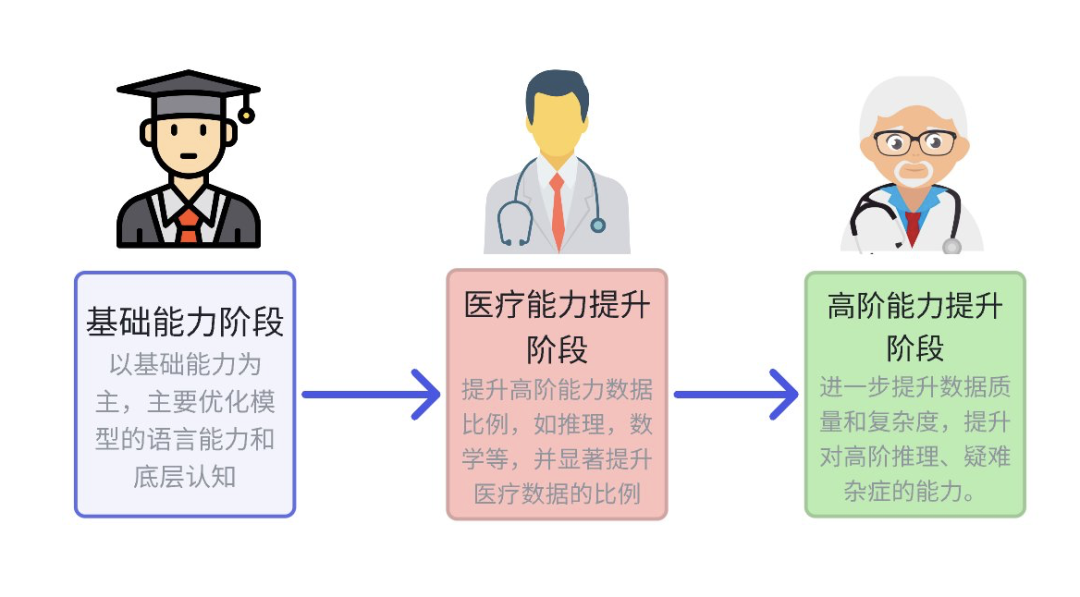
模型训练阶段:我们运用行业首创的多阶段领域提升方案,将整个训练分为通识提升、医疗基础知识提升、医疗进阶知识提升三阶段,依次提升基础语言、高阶及疑难病症应对等能力。此外还在 CoT 训练框架中创新的引入了ELO 强化学习法,优化思维链路径,避免传统奖励模型偏差,有效提升了模型的生成质量与逻辑推理能力。
Baichuan-M1-preview是我们在AI医疗领域的又一次重要突破,让我们在实现“造医生、改路径、促医学”愿景的道路上又迈出了坚实的一步。而Baichuan-M1-14B开源模型也将为中国AI医疗健康生态建设提供强大助力。
(文:Founder Park)