

0x0. 前言
yifuwang 在 https://github.com/yifuwang/symm-mem-recipes 中实现了一个 triton_all_gather_matmul.py ,也就是可以把AllGather和MatMul kernel fuse起来变成一个kernel,在有NVLink 连接的 H100 对LLama3 各个规模的矩阵乘进行测试都取得了可观的加速。下面是对这个fuse算子的描述
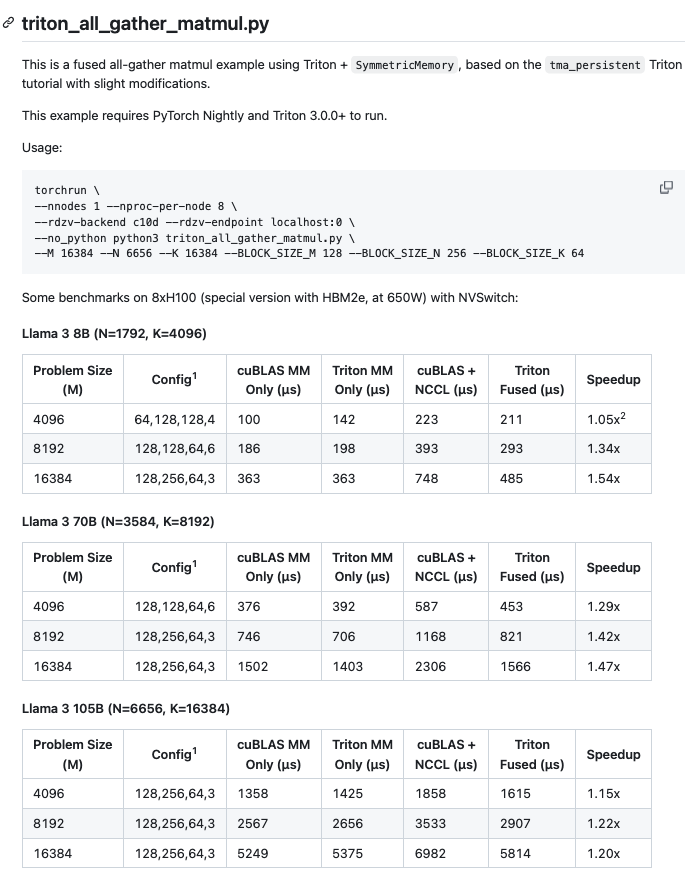
为什么这里要读一下这个工作?
因为我发现,这个工程实现恰好体现出了Triton在2024年的一些最新进展,它也可以把 Meta PyTorch 团队在 Triton 和 TorchTitan 上的一些探索串联起来,2024年发布的一些PyTorch Blog和这个是高度相关的,所以这里尝试梳理一下这里涉及到的知识以及这个 triton_all_gather_matmul Kernel 的新特性。
0x1. 相关工作
SymmetricMemory (TorchTitan Async AllGather + MatMul)
首先我们可以看到https://github.com/yifuwang/symm-mem-recipes 中的 triton_all_gather_matmul.py 实现依赖了 PyTorch Nightly 的 SymmetricMemory ,而这个数据结构正是 PyTorch 为了实现 Overlap Matmul 和 AllGather 抽象出来的。之前在 [分布式训练与TorchTitan] PyTorch中的Async Tensor Parallelism介绍 中有一段对这个数据结构的介绍。具体如下:
在分解通信时,使用NCCL的send/recv操作可能很有诱惑力,因为它们易于使用。然而,NCCL的send/recv操作具有一些特性,使其不太适合异步张量并行:
-
重叠计算和通信之间的竞争 – 虽然人们普遍认为计算和通信是可以独立使用的两种资源,但实际上它们的独立性是有细微差别的,确实会发生竞争。在节点内设置(TP最常见的情况)中,NCCL的send/recv kernel 会利用SM通过NVLink传输数据,这减少了可用于重叠矩阵乘法 kernel 的SM数量,从而降低了速度。有趣的是,观察到的速度下降可能超过通信 kernel 消耗的资源百分比。由于cuBLAS试图选择以完整waves执行的 kernel ,通信 kernel 占用的SM可能会打破平衡,导致矩阵乘法 kernel 需要执行额外的wave。
-
双向同步 – NCCL的send/recv kernel 执行双向同步,这意味着发送方和接收方都会被阻塞直到操作完成。这种方法对于算子内并行中的数据传输并不总是最优的。根据具体情况,可能更适合对多个数据传输执行单次同步,或者在向远程节点推送数据和从远程节点拉取数据之间进行选择。
幸运的是,我们可以通过利用CUDA的P2P机制来避免前面提到的缺点。该机制允许设备通过将其映射到虚拟内存地址空间来访问对等设备上分配的内存。这种机制使得内存操作(加载/存储/原子等)可以通过NVLink执行(目前,PyTorch中的async-TP实现需要所有设备对之间都有NVLink连接(例如通过NVSwitch)才能实现加速。这是我们计划在未来解决的限制)。此外,当通过cudaMemcpyAsync在对等设备之间传输连续数据时,该操作由拷贝引擎(拷贝引擎是GPU上的专用硬件单元,用于管理不同内存位置之间的数据移动,独立于GPU的计算核心(SM)运行)处理,不需要任何SM,从而避免了前面讨论的竞争问题(通过拷贝引擎的数据传输仍然共享相同的内存带宽。然而,这不太可能造成显著的竞争,因为(1)传输速率受限于NVLink带宽,低到足以避免内存带宽竞争,(2)重叠的矩阵乘法是计算密集型的)。
为了在未来利用这种机制实现async-TP和类似用例,我们开发了一个名为SymmetricMemory的实验性抽象(https://github.com/pytorch/pytorch/blob/main/torch/csrc/distributed/c10d/SymmetricMemory.hpp)。从概念上讲,它表示一个在设备组之间对称分配的缓冲区,通过虚拟内存/多播地址为每个GPU提供对其对等设备上所有相应缓冲区的访问。使用async-TP不需要直接与SymmetricMemory交互,但用户可以利用它来创建类似于async-TP的自定义细粒度、节点内/算子内优化。
SymmetricMemory 的实现在 https://github.com/pytorch/pytorch/blob/d62e900d8ce895a4bb5c152b2d7b3d084f97efed/torch/distributed/_symmetric_memory/__init__.py。
关于 SymmetricMemory 的细节就需要自己去阅读代码了。我这里简单总结一下:
-
symmetric_memory是PyTorch中的一个分布式内存管理机制,主要用于多GPU间高效共享内存。
def empty(
*size: Any,
dtype: Optional[_dtype] = None,
device: Optional[_device] = None,
) -> torch.Tensor:
"""创建一个可以在多进程间共享的对称内存张量"""
return _SymmetricMemory.empty_strided_p2p(
size=size,
stride=torch._prims_common.make_contiguous_strides_for(size),
dtype=dtype,
device=torch.device(device),
)
-
主要特点是所有GPU上分配相同大小的内存空间,支持GPU之间直接访问内存(P2P),无需CPU参与,还提供barrier等细粒度同步原语。
def rendezvous(tensor: torch.Tensor, group: Union[str, "ProcessGroup"]) -> _SymmetricMemory:
"""建立多进程间的对称内存张量"""
enable_symm_mem_for_group(group_name)
return _SymmetricMemory.rendezvous(tensor, group_name)
-
一般使用流程
-
分配内存
a_shard = symm_mem.empty(m // world_size, k, dtype=torch.bfloat16, device=device)
-
数据访问:
# 获取远程buffer
src_buf = symm_mem_hdl.get_buffer(
src_rank, # 源GPU rank
chunks[0].shape, # buffer形状
inp.dtype, # 数据类型
chunks[0].numel() * split_id # 偏移量
)
-
同步机制
# 写入同步值
symm_mem_hdl.stream_write_value32(
progress,
offset=src_rank * splits_per_rank + split_id,
val=1,
)
# barrier同步, 等待所有rank完成
symm_mem_hdl.barrier()
TMA 和 WarpSpecialization Matmul
Triton 目前支持了 Hopper 架构上的 WarpSpecialization + TMA GEMM ,实际上在 2024 年期间 PyTorch 也一直在做这方面的实践,例如:
-
【翻译】深入探讨 Hopper TMA 单元在 FP8 GEMM 运算中的应用 -
PyTorch 博客 CUTLASS Ping-Pong GEMM Kernel 简介 -
PyTorch博客 《使用 Triton 加速 2D 动态块量化 Float8 GEMM 简介》
PyTorch 支持 WarpSpecialization 的魔改 Triton:
https://github.com/facebookexperimental/triton/tree/ws
不久前相关工作也进了 Triton 的主分支。
Persistent Matmul
除了上述很新的特性之外,Triton在Hopper架构上也支持了 persistent GEMM 来尽量让 GPU 一直运行 Kernel,这个对应的应该是 Epilogue fusion ,Triton 也做了一个官方教程 https://github.com/triton-lang/triton/blob/main/python/tutorials/09-persistent-matmul.py
基于 SymmetricMemory 和 Triton 的 Persistent Matmul 和 TMA 抽象,yifuwang 在 https://github.com/yifuwang/symm-mem-recipes 中实现了 triton_all_gather_matmul.py 。
0x2. triton_all_gather_matmul.py 要点
pipeline
这个程序的 Matmul 从Triton教程中的Persistent Matmul修改而来 https://github.com/triton-lang/triton/blob/main/python/tutorials/09-persistent-matmul.py#L154-L226 ,然后加入了基于SymmetricMemory实现的 allgather。我这里简单说一下我的发现:
首先,代码里面有一个backend_stream用来做allgather,代码片段为,我精简了很多assert语句:
def all_gather_matmul_tma_persistent(a_shard, b, a_out, c_out, configs, mm_only: bool = False):
# 计算通信块大小
SPLITS_PER_RANK = 1
COMM_BLOCK_SIZE_M = M // world_size // SPLITS_PER_RANK
# 设置进度数组用于同步
progress = torch.zeros(world_size, dtype=torch.uint32, device="cuda")
# 后台流中执行all_gather
backend_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(backend_stream):
all_gather_with_progress(a_out, a_shard, progress, SPLITS_PER_RANK)
接着,程序把矩阵A按rank数量分块,每个rank负责一块(一共有world_size个rank),然后使用上面的progress数组跟踪每个分块的完成状态。然后在matmul_kernel_tma_persistent Triton实现中有如下代码:
# 确定数据来源(本地或远程)
comm_block_id = pid_m // NUM_PID_M_PER_COMM_BLOCK
if comm_block_id // NUM_COMM_BLOCKS_PER_RANK == RANK:
# 从本地分片读取
offs_am_src = (pid_m * BLOCK_SIZE_M) % COMM_BLOCK_SIZE_M
a_ptr = a_shard_desc_ptr
else:
# 等待并从远程分片读取(如果数据没有到达,会等待)
wait_signal((progress_ptr + comm_block_id).to(tl.uint64), flat_tid)
offs_am_src = pid_m * BLOCK_SIZE_M
a_ptr = a_desc_ptr
而这里的等待并从远程分片读取是一个非常Tricky的写法:
@triton.jit
def wait_signal(addr, flat_tid):
if flat_tid == 0:
tl.inline_asm_elementwise(
"""
{
.reg .pred %p<1>;
wait_block:
ld.global.relaxed.gpu.u32 $0, [$1];
setp.eq.u32 %p0, $0, 1;
@!%p0 bra wait_block;
}
""",
"=r, l",
[addr],
dtype=tl.int32,
is_pure=False,
pack=1,
)
tl.inline_asm_elementwise(
"bar.sync 0;", "=r", [], dtype=tl.int32, is_pure=False, pack=1
)
大致可以判断它只需要在一个线程块的Thread 0执行等待操作,只要当前线程块的数据到达就可以立即启动计算。可以预见,只要backend stream里面的数据拷贝比计算更快,all_gather和matmul就可以overlap起来,由于这里使用了TMA有独立硬件支持,所以可以加速内存拷贝。
wait_signal这个函数实现了一个自旋等待机制,等待特定内存地址的值变为1,只有第一个线程(flat_tid=0)执行等待操作, 避免了过多的内存访问,然后通过barrier同步整个线程块。内嵌的PTX:
.reg .pred %p<1>; # 声明谓词寄存器用于条件判断
wait_block: # 循环标签
# 从全局内存读取值,使用relaxed内存序
ld.global.relaxed.gpu.u32 $0, [$1];
# 比较值是否等于1
setp.eq.u32 %p0, $0, 1;
# 如果不等于1,继续循环
@!%p0 bra wait_block;
index 映射
在main loop里面,坐标映射有点绕,我这里尝试举个例子来看一下。
# 主循环,处理所有tile
for _ in range(0, k_tiles * tiles_per_SM):
# 更新K维度的tile索引
ki = tl.where(ki == k_tiles - 1, 0, ki + 1)
if ki == 0:
# 更新tile ID和相关索引
tile_id += NUM_SMS
group_id = tile_id // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + (tile_id % group_size_m)
pid_n = (tile_id % num_pid_in_group) // group_size_m
# 计算通信相关的块大小和数量
NUM_COMM_BLOCKS = M // COMM_BLOCK_SIZE_M
NUM_COMM_BLOCKS_PER_RANK = NUM_COMM_BLOCKS // WORLD_SIZE
NUM_PID_M_PER_COMM_BLOCK = COMM_BLOCK_SIZE_M // BLOCK_SIZE_M
# 上面的pid_m是没有做分片的时候的pid_m,这里要考虑到分片的情况
pid_m = (pid_m + NUM_PID_M_PER_COMM_BLOCK * RANK) % num_pid_m
# 确定数据来源(本地或远程)
comm_block_id = pid_m // NUM_PID_M_PER_COMM_BLOCK
if comm_block_id // NUM_COMM_BLOCKS_PER_RANK == RANK:
# 从本地分片读取
offs_am_src = (pid_m * BLOCK_SIZE_M) % COMM_BLOCK_SIZE_M
a_ptr = a_shard_desc_ptr
else:
# 等待并从远程分片读取
wait_signal((progress_ptr + comm_block_id).to(tl.uint64), flat_tid)
offs_am_src = pid_m * BLOCK_SIZE_M
a_ptr = a_desc_ptr
假设我们有以下配置:
-
M = 1024 (矩阵A的总行数) -
WORLD_SIZE = 4 (4个GPU) -
COMM_BLOCK_SIZE_M = 256 (通信块大小) -
BLOCK_SIZE_M = 64 (计算块大小)
那就有:
# 计算各种块数量
NUM_COMM_BLOCKS = M // COMM_BLOCK_SIZE_M = 1024 // 256 = 4 # 总通信块数
NUM_COMM_BLOCKS_PER_RANK = NUM_COMM_BLOCKS // WORLD_SIZE = 4 // 4 = 1 # 每个rank负责的通信块数
NUM_PID_M_PER_COMM_BLOCK = COMM_BLOCK_SIZE_M // BLOCK_SIZE_M = 256 // 64 = 4 # 每个通信块包含的计算块数
然后假设当前的全局 pid_m=2 且 RANK=1 :
# pid_m = (pid_m + NUM_PID_M_PER_COMM_BLOCK * RANK) % num_pid_m
pid_m = (2 + 4 * 1) % 16 = 6
comm_block_id = pid_m // NUM_PID_M_PER_COMM_BLOCK = 6 // 4 = 1
if comm_block_id // NUM_COMM_BLOCKS_PER_RANK == RANK: # 1 // 4 == 0 (true)
对于全局 pid_m=2 和 RANK=1 来说,由于pid_0到pid_4都是切分到了第一张卡,所以这里自然需要执行代码中等待并从远程分片读取的分支:
# 确定数据来源(本地或远程)
comm_block_id = pid_m // NUM_PID_M_PER_COMM_BLOCK
if comm_block_id // NUM_COMM_BLOCKS_PER_RANK == RANK:
# 从本地分片读取
offs_am_src = (pid_m * BLOCK_SIZE_M) % COMM_BLOCK_SIZE_M
a_ptr = a_shard_desc_ptr
else:
# 等待并从远程分片读取
wait_signal((progress_ptr + comm_block_id).to(tl.uint64), flat_tid)
offs_am_src = pid_m * BLOCK_SIZE_M
a_ptr = a_desc_ptr
0x3. 总结
简单看了一下 Fused AllGather和MatMul 的 Overlap Triton 工程实现, 通过 Triton 提供的 TMA Persistent Matmul 以及 PyTorch 的 SymmetricMemory 抽象实现了一个可以直接把 AllGather 和 MatMul Overlap 起来的 kernel。这个工程中也有实现基于 SymmetricMemory 更加高效的 Triton 算子,感兴趣可以查看。不过和 PyTorch 提供的 fused_all_gather_matmul(https://github.com/pytorch/pytorch/blob/f08b9bc7e4e7398c23507722abb9520205fe8a2d/test/distributed/test_symmetric_memory.py#L402) 算子一样需要在有 NVLink 的 Hopper 架构GPU上才可以使用。
(文:GiantPandaCV)