
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
字节与清华合作,抢在OpenAI之前悄悄上线电脑操作智能体UI-TARS,超越GPT-4o和Claude 3.5等一众模型,而且免费商用(Apache 2.0)。
UI-TARS是由阿里的Qwen-VL模型魔改得到,识别过程基于视觉模型和推理实现,能够一步一步自动完成跨应用的复杂操作,并兼容各种系统。
比如在Mac里打开浏览器获取天气信息:
或者在Windows系统里打开推特并发帖:
甚至还能操控手机和web界面,在安卓系统中打开音乐播放器并搜索歌曲。

在GitHub上,UI-TARS的星标数量已经达到了900+。

网友评价说,UI-TARS的表现比OpenAI泄露的Operator表现还要好(此评论发出时,Operator还未发布)。
而且Operator要开200美元一个月的Pro会员,换算成人民币就是1450,但UI-TARS是免费的。

还有人表示其意义重大,因为这样的工作模式意味着即使是上古应用,也有望通过AI来进行操纵。

Agent自主搜机票,还会改PPT
在官方的演示视频当中,展示了UI-TARS的三个DEMO。
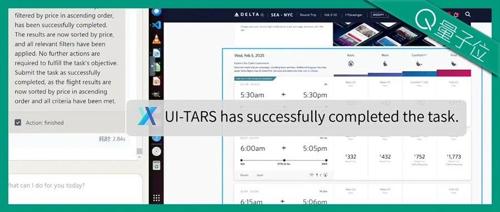
首先是按照要求,帮用户搜索SEA(西雅图)到NYC(纽约)的机票。
UI-TARS在航空公司的网站上填写了起始地点,并设置了指定的日期范围,最后按照价格高低对搜索结果进行排序。
整个流程都是UI-TARS一步步分析网页画面和用户要求,全自主地完成的。
第二个任务是修改PPT,具体要求是将第二页的背景颜色改成和第一页一样。
同样是通过不断地观察、分析和推理,UI-TARS自主完成了一系列动作。
第三个任务则是给VS Code安装一个插件。
此外在抱抱脸上,还有一个热心网友制作的简易版本可以在线试玩,没有实操功能但可以上传图片并输入指令后,让系统分析点击位置。
比如把GitHub上的项目fork到自己的仓库:

而且一些网站的专属图标也能认识,比如可以给B站上的视频投币:

甚至是打开微信朋友圈:

同时手机截图也可以识别,比如在小红书上发一篇新帖子,它也知道应该点击下面的加号:

感知能力方面,在VisualWebBench、WebSRC和ScreenQA-short这三个评测感知能力的基准上,UI-TARS的不同规模版本都取得了领先的成绩。
特别是UI-TARS-72B,在VisualWebBench和ScreenQA-short上成绩超过了GPT-4o和Claude 3.5 Sonnet。
UI-TARS-7B则在WebSRC上以93.6的成绩位居榜首。

而在定位能力上,UI-TARS在ScreenSpot Pro、ScreenSpot和ScreenSpot v2这三个评测元素定位能力的基准上,同样表现出色。
UI-TARS-72B在ScreenSpot Pro上以38.1的成绩大幅领先前SOTA模型UGround-V1-7B;
在ScreenSpot上,UI-TARS-7B以89.5的成绩排名第一;在ScreenSpot v2上,UI-TARS-7B和UI-TARS-72B分别以91.6和90.3的成绩超过了baseline。

最后是执行能力,具体又可以分成静态(离线)和动态(在线)两种环境。
在三个Multimodal Mind2Web、Android Control和GUI Odyssey静态Benchmark上,UI-TARS在各项关键指标上都取得了SOTA成绩。
UI-TARS-7B虽然参数量较少,但也超过了Aguvis-72B和Claude等较强的baseline。

对于动态环境,作者选取了OSWorld和AndroidWorld这两个基准进行评测。
在OSWorld上,在15步预算下,UI-TARS-7B-DPO和UI-TARS-72B-DPO均大幅超过Claude。
并且UI-TARS-72B-DPO在15步预算下,就已经接近Claude在50步预算下的成绩。
在50步的预算下,UI-TARS-72B-DPO在更是以24.6的成绩刷新了SOTA。
在AndroidWorld上,UI-TARS-72B-SFT也以46.6的成绩超过了此前表现最佳的框架和模型。

50B数据集魔改Qwen-2-VL
UI-TARS是字节在阿里的开源多模态模型Qwen-2-VL基础之上,使用了50B规模tokens继续训练而成。

训练过程采用了与SOTA模型一致的三阶段训练流程:
-
首先是连续预训练阶段,在感知、定位和动作数据上进行训练,从而获得交互基础能力;
-
然后是退火阶段,在筛选的高质量数据子集上进行训练,针对真实场景进行决策优化;
-
最后是DPO阶段,利用反思数据对进行训练,引导模型矫正错误行为、强化最优动作。
为了克服人工标注数据规模受限的瓶颈,UI-TARS还采用了在线学习的方式,在数百台虚拟机上自动生成新的交互轨迹数据。
然后通过启发式规则、语言模型评分和人工审核等多级过滤,提纯出高质量数据用于模型微调。

此外,UI-TARS还引入了反思调优机制,通过对错误进行人工标注和修正,让模型学会从错误中恢复。
接收到初始任务指令后,UI-TARS会不断地从设备接收视觉信息,并执行相应的动作来完成任务。
在每一个时间步,UI-TARS以任务指令、之前的交互历史以及当前观察作为输入,输出一套动作并执行。
动作执行后,设备界面会发生变化,UI-TARS感知新的界面状态,得到下一步的视觉信息,然后持续迭代直至任务完成(或需要人工介入)。
推理过程中,UI-TARS采用了思维链(CoT)、系统2思考等方式,在每个动作前引入“思考”环节,充当感知和动作之间的桥梁。
通过对大规模GUI教程数据的挖掘,论文总结出任务分解、长期一致性、里程碑识别、试错和反思等推理模式。

数据层面,研究团队也构建了大规模的GUI截图数据集。
数据集包含来自网站、应用程序和操作系统的截图,以及使用专门解析工具提取出的元素类型、边界框和文本内容等元数据。
在此基础上,UI-TARS的训练目标包括五个核心感知任务:
-
元素描述:为每个GUI组件生成详细的结构化描述,包括元素类型、视觉外观、位置信息和功能四个方面;
-
密集字幕:描述整个界面的布局、元素间的空间关系、层次结构和交互等,以实现全面理解;
-
状态转换字幕:捕捉界面在交互前后的细微视觉变化;
-
问答:增强模型在抽象和推理层面理解界面的能力;
-
视觉标记:通过为元素添加形状、颜色和大小不同的标记,训练模型将元素与特定的空间、功能上下文关联。
为提高UI-TARS执行点击、拖动等操作时对界面元素的定位精度,作者还构建了一个大规模的配对数据集,将元素描述与其边界框坐标相关联。
具体而言,团队使用专门的解析工具提取GUI截图中的元素元数据(类型、深度、边界框、文本等),并将每个元素的边界框角点坐标归一化处理。
训练时,将截图与元素描述配对,要求模型输出描述对应元素的归一化坐标。
为了让UI-TARS能够跨平台执行任务,团队还设计了一个统一动作空间,将移动设备、桌面应用和网页上语义等价的动作(如点击、键入、滚动、拖动等)映射到一个通用操作集合。
同时也引入了平台特定的可选动作,来处理每个平台的独特需求。

团队简介
UI-TARS项目,由字节Seed团队与清华联手打造。
五名共同一作当中,有三人都拥有在清华NLP实验室的学习或工作经历。
比如包括原面壁智能核心成员、清华博士、开源大模型工具学习引擎BMTools核心作者秦禹嘉,之前的导师就是清华NLP实验室的刘知远。
署名第二位的叶奕宁,是刘知远团队在读硕士生;署名第五的梁世豪,之前在刘知远团队担任过研究助理,现在在香港大学读研究生,并在字节Seed团队实习。

Seed团队成立于2023年1月,是字节跳动在AI业务上的重要调整之一,专注于大模型的研发,由朱文佳领导。
此前朱文佳先后担任今日头条APP负责人(向今日头条CEO陈林汇报,后改为直接向张一鸣汇报)和TikTok产品与工程负责人(向周受资汇报)。
2024年,朱文佳获得提拔,整体负责字节AI业务,直接向字节跳动CEO梁汝波汇报。
这两天,字节豆包团队又开启了AGI计划,代号“Seed Edge”,目标是探索AGI的新方法。
论文地址:
https://arxiv.org/abs/2501.12326
GitHub:
https://github.com/bytedance/UI-TARS
—
(文:量子位)