
最近,我尝试对 Qwen2-VL-2B 进行微调。这是一款强大的多模态大语言模型,既能处理文本,又能理解图像。
简单来说,它就像一个既能“看”又能“读”的智能助手。我希望利用它的能力,从图像中提取关键信息,也就是完成 OCR(光学字符识别)任务。
在这篇文章中,我会带大家一步步了解我的完整过程:如何构建并标注一个适合的图像数据集、将其格式化以适配模型、进行模型训练、实施量化优化,以及最终的模型评估。
但今天我们先聚焦在关键的一环——如何准备一个高质量的自定义数据集,为 Qwen2-VL 模型微调做好准备。
为什么我会选择 Qwen2-VL 来完成这项任务,而不是其他专用的 OCR 模型?其实,市场上有很多优秀的 OCR 工具,但 Qwen2-VL 的综合表现让我最终决定将它用于我的项目。
首先,它是一款多模态大语言模型,除了文本处理外,还在图像和视频理解方面表现出色,这让它在处理复杂场景时更加灵活。其次,Qwen2-VL 的 2B 参数大小在性能与硬件需求之间达到了一个平衡点,同时还提供 7B 和 72B 的版本可选,可以满足不同规模的任务需求。此外,它对 Nvidia GPU 的兼容性非常友好,尤其是我计划在生产环境中使用的硬件配置,稍后会详细介绍。
另一个让我印象深刻的地方是它在多模态任务上的基准表现,远超许多同类模型。这些成绩不仅表明它的能力足够强大,也让我对它在 OCR 应用中的潜力充满信心。由于很多文章已经深入解析了 Qwen2-VL 的工作原理,我就不在这里赘述细节了,而是聚焦于我选择它的实际原因和应用体验。
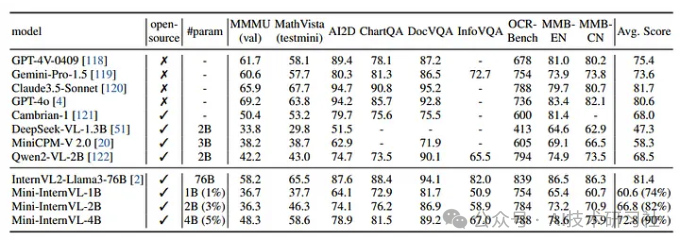
我还在该数据集上对 PaddleOCR-v4 进行了微调,并将其结果与 Qwen2-VL 的微调模型进行了比较。最终,我得出的结论是,基于 LLM 的方法在我的用例中提供了更高的准确性。
此外,我还将 Qwen2-VL-2B 模型的结果与 Azure Document Intelligence OCR 进行了对比。我必须承认,两者的结果几乎相当,甚至在某些方面 Qwen2-VL-2B 更胜一筹。不过,我计划稍后微调 stepfun-ai/GOT-OCR2_0,并将其结果与 Qwen2-VL 进行详细比较。这部分内容将在未来的更新中呈现。
关于如何创建专门用于使用自定义数据进行 LLM 训练的数据集,相关的资源非常有限。在花费大量时间研究和整理这一过程后,我决定在本博客中提供一份全面且深入的指南。
我目前主要在 Linux 环境下完成模型的微调、量化和推理工作,因为目前尚未提供稳定的 Windows 支持。不过,如果我能够成功在 Windows 上完成搭建,我会及时更新这篇博客以分享相关经验。
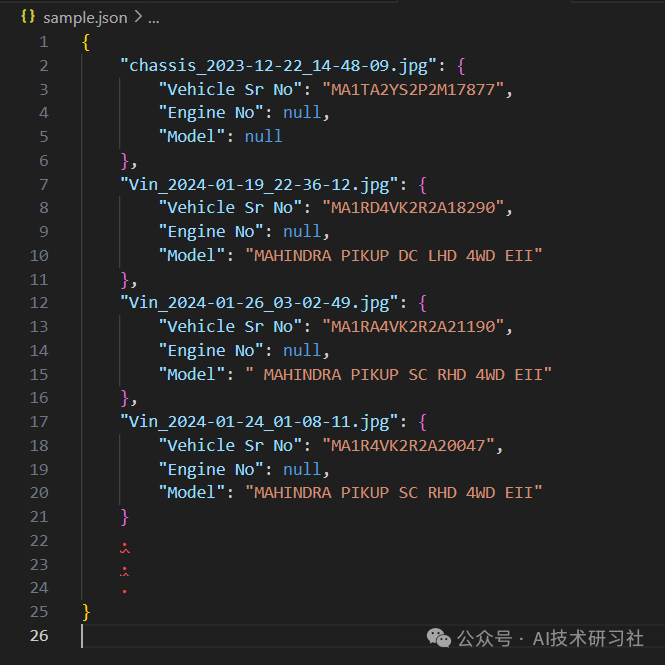
我首先收集了大约 3,000 张图像,并为这些图像进行了标注。我的主要目标是从 VIN 铭牌图像中提取 车型、车辆序列号和发动机编号,以及从底盘图像中提取 底盘编号。
以下是示例图像及其对应的 OCR 标签格式:
Vinplate 图片:

“vinplate.jpg”: {"Vehicle Sr No": "MA1TA2YS2R2A13882","Engine No": "YSR4A38798","Model": "SCORPIO CLASSIC S5 MT 7S"}

{ "messages": [ { "content": "<image>Can you find and provide the Vehicle Sr No, Engine No, and Model from the image?", "role": "user" }, { "content": "{\n \"Vehicle Sr No\": \"MA1TA2YS2R2A13882\",\n \"Engine No\": YSR4A38798,\n \"Model\": SCORPIO CLASSIC S5 MT 7S\n}", "role": "assistant" } ], "images": [ "path/to/imagefolder/vinplate.jpg" ]}
{ "messages": [ { "content": "<image><image>Can you find and provide the Vehicle Sr No, Engine No, and Model from the image?", "role": "user" }, { "content": "{\n \"Vehicle Sr No\": \"MA1TA2YS2R2A13882\",\n \"Engine No\": YSR4A38798,\n \"Model\": SCORPIO CLASSIC S5 MT 7S\n}, {\n \"Vehicle Sr No\": \"MA1TA2YS2R2A13883\",\n \"Engine No\": YSR4A38799,\n \"Model\": SCORPIO CLASSIC S5 MT 7S\n}", "role": "assistant" } ], "images": [ "path/to/imagefolder/vinplate1.jpg", "path/to/imagefolder/vinplate2.jpg", ]}
and so on. 等等。
import jsonimport randomdef generate_user_query():variations = ["Extract out the Vehicle Sr No, Engine No, and Model from the given image.","Can you provide the Vehicle Sr No, Engine No, and Model for this image?","What is the Vehicle Sr No, Engine No, and Model in the given image?","Please extract the Vehicle Sr No, Engine No, and Model from this image.","Find the Vehicle Sr No, Engine No, and Model in this image.","Retrieve the Vehicle Sr No, Engine No, and Model from the image provided.","What are the Vehicle Sr No, Engine No, and Model present in this image?","Identify the Vehicle Sr No, Engine No, and Model from this image.","Could you extract the Vehicle Sr No, Engine No, and Model from the attached image?","Provide the Vehicle Sr No, Engine No, and Model from the image.","Please determine the Vehicle Sr No, Engine No, and Model for this image.","Extract the information for Vehicle Sr No, Engine No, and Model from the given image.","What is the Vehicle Sr No, Engine No, and Model information extracted from this image?","Can you pull the Vehicle Sr No, Engine No, and Model from the image?","Retrieve the Vehicle Sr No, Engine No, and Model details from this image.","Get the Vehicle Sr No, Engine No, and Model from the provided image.","Please extract and provide the Vehicle Sr No, Engine No, and Model for this image.","What Vehicle Sr No, Engine No, and Model can be identified in the image?","I need the Vehicle Sr No, Engine No, and Model from this image.","Can you find and provide the Vehicle Sr No, Engine No, and Model from the image?"]return random.choice(variations)def convert_to_format(input_data, image_folder_path):formatted_data = []for image_name, details in input_data.items():user_query = generate_user_query()formatted_entry = {"messages": [{"content": '<image>'+user_query,"role": "user"},{"content": json.dumps(details, indent=4),"role": "assistant"}],"images": [f"{image_folder_path}/{image_name}"]}formatted_data.append(formatted_entry)return formatted_datadef load_input_json(input_json_path):with open(input_json_path, 'r') as json_file:input_data = json.load(json_file)return input_datadef main(input_json_path, image_folder_path, output_json_path):input_data = load_input_json(input_json_path)formatted_output = convert_to_format(input_data, image_folder_path)with open(output_json_path, 'w') as json_file:json.dump(formatted_output, json_file, indent=4)print(f"Formatted output saved to {output_json_path}")input_json_path = 'combined-ocr-json.json'image_folder_path = 'path/to/imagefolder' # Folder where images are storedoutput_json_path = 'final-llm-input.json' # Path for the output JSON filemain(input_json_path, image_folder_path, output_json_path)
这是将用于微调 Qwen2-VL 模型的主要 JSON 文件。

(文:AI技术研习社)