


DeepSeek R1 彻底出圈了,R1的冲击波经过几天的酝酿,今天似乎达到了一个高点,小编时间线被刷爆了,总结起来有两点给大家分享一下,非常有意思:首先R1经受住了多个权威基准测试,其次R1带来了大量八卦和破防,当然还有福利,因为R1 Sam Altman 宣布o3 mini 免费可用(有查询次数限制)
直接上图,大家看看
权威基准测试
三张图无可争辩的说明 DeepSeek R1的强大:
DeepSeek R1在大模型竞技场 Chatbot Arena,以及其他两个无法提前被黑客入侵的独立基准(Artificial-Analysis, HLE)经受住考验
1.大模型竞技场排名
DeepSeek-R1 大模型竞技场排行出炉,挺进前三!性能直逼顶尖。LM Arena (原 lmsys.org) 称 DeepSeek-R1 的表现令人瞩目,并称赞其为社区带来了一份“令人难以置信的里程碑和礼物”
DeepSeek-R1 的亮点包括: 综合排名第三:DeepSeek-R1 目前在 LM Arena 综合榜单上排名第三,与顶尖推理模型 o1 并列,展现了强大的通用能力技术领域表现卓越:
在 “Hard Prompts” (高难度提示词)、 “Coding” (代码能力) 和 “Math” (数学能力) 等技术性极强的领域,DeepSeek-R1 更是拔得头筹,位列第一风格控制并列第一:
在 “Style Control” (风格控制) 方面,DeepSeek-R1 也展现了惊人的实力,与 o1 并列第一,意味着模型在理解和遵循用户指令,并按照特定风格生成内容方面表现出色推文还指出,
在 “Hard Prompt with Style Control” (高难度提示词与风格控制结合)的测试中,DeepSeek-R1 更是与 o1 并列第一,进一步证明了其在复杂任务和精细化控制方面的强大能力
虽然目前的排名是基于早期的结果,更多投票正在收集中以确保排名的稳定性,但 DeepSeek-R1 已经展现出在各个领域都非常强劲的潜力
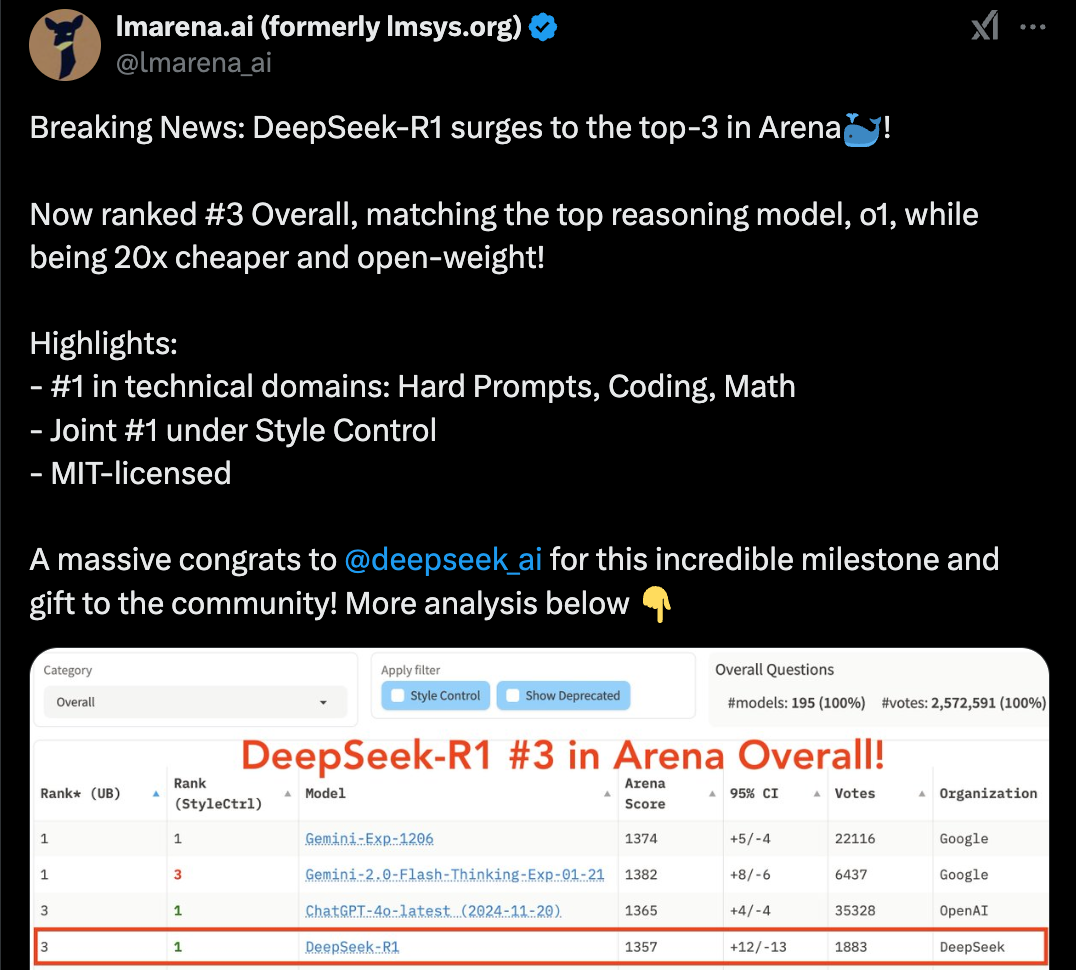
2.人类最后的考试 测试
这个测试是昨天刚刚发布的,难度非常高,是Scale AI 和CAIS 公布的一项突破性的新基准,这是人类知识前沿的多模式基准,旨在成为同类中最后一个学科覆盖面广的封闭式学术基准。该数据集由跨越一百多个学科的 3,000 道挑战性试题组成。公开发布这些问题,同时保留了一个不公开的测试集,用于评估模型的过拟合情况
R1 排名第一
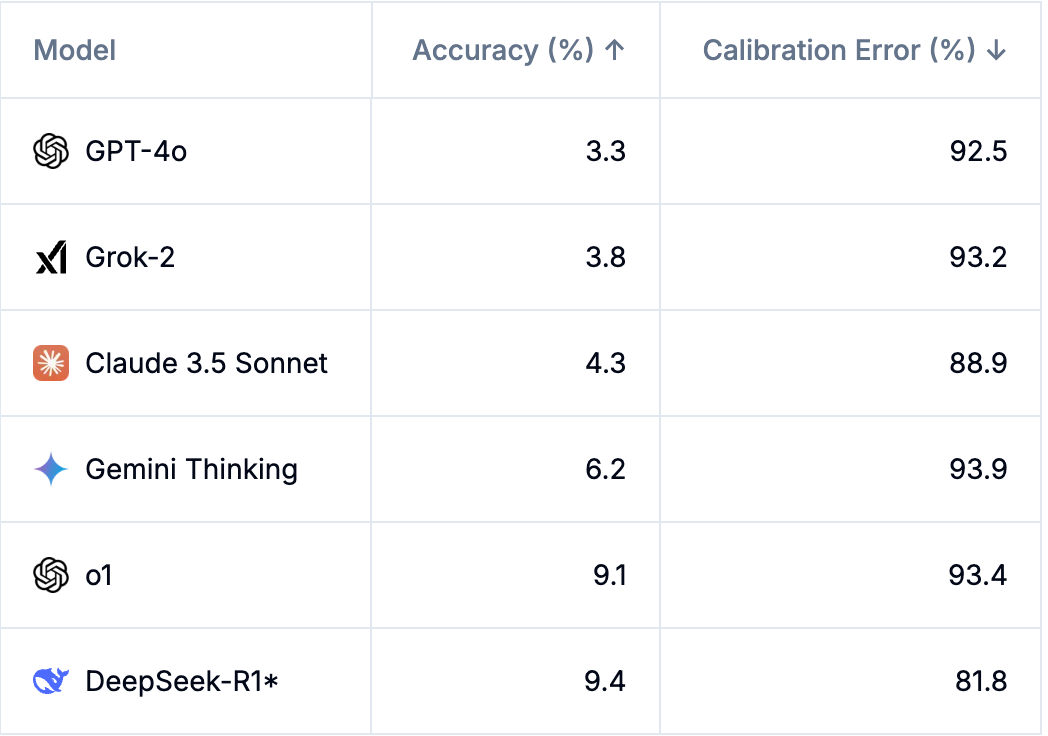
Artificial-Analysis
Artificial-Analysis 对人工智能模型和应用程序接口提供商进行独立分析, 了解人工智能的现状,为您的使用案例选择最佳模型和提供商
R1排名第二(比O1便宜25倍)

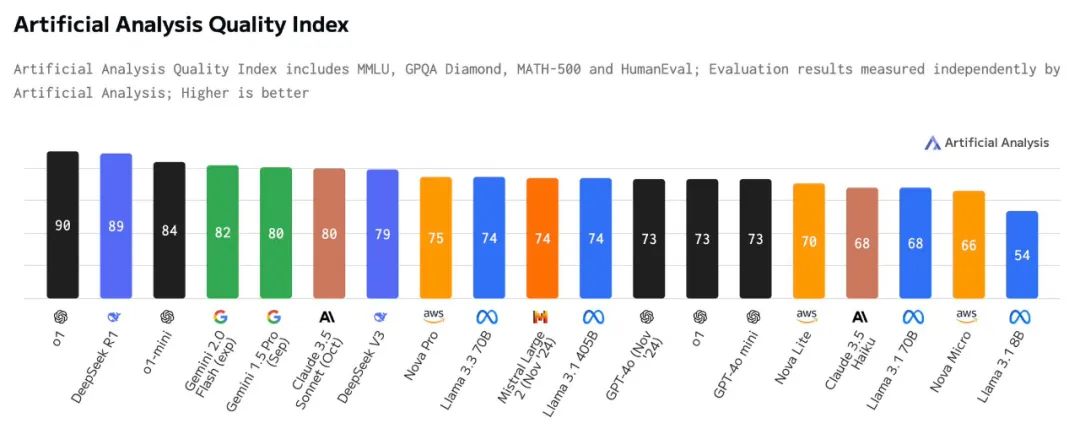
其他测试
webdev 测试R1 排名第二

赞誉,破防,恐慌以及八卦
杨立坤赞扬deepseek,杨立坤转发并且夸奖了 R1项目,表示开源会加速 AI 进步
对于那些看到 DeepSeek 性能并认为:“中国正在超越美国在人工智能领域”的人们,你们理解错了。正确的理解应该是:“开源模型正在超越专有模型。”
DeepSeek 从开源研究和开源技术中受益(例如 Meta 的 PyTorch 和 Llama)他们提出了新的想法,并在其他人的工作基础上进行了构建,由于他们的工作是公开发布和开源的,大家都可以从中受益,这就是开源研究和开源的力量
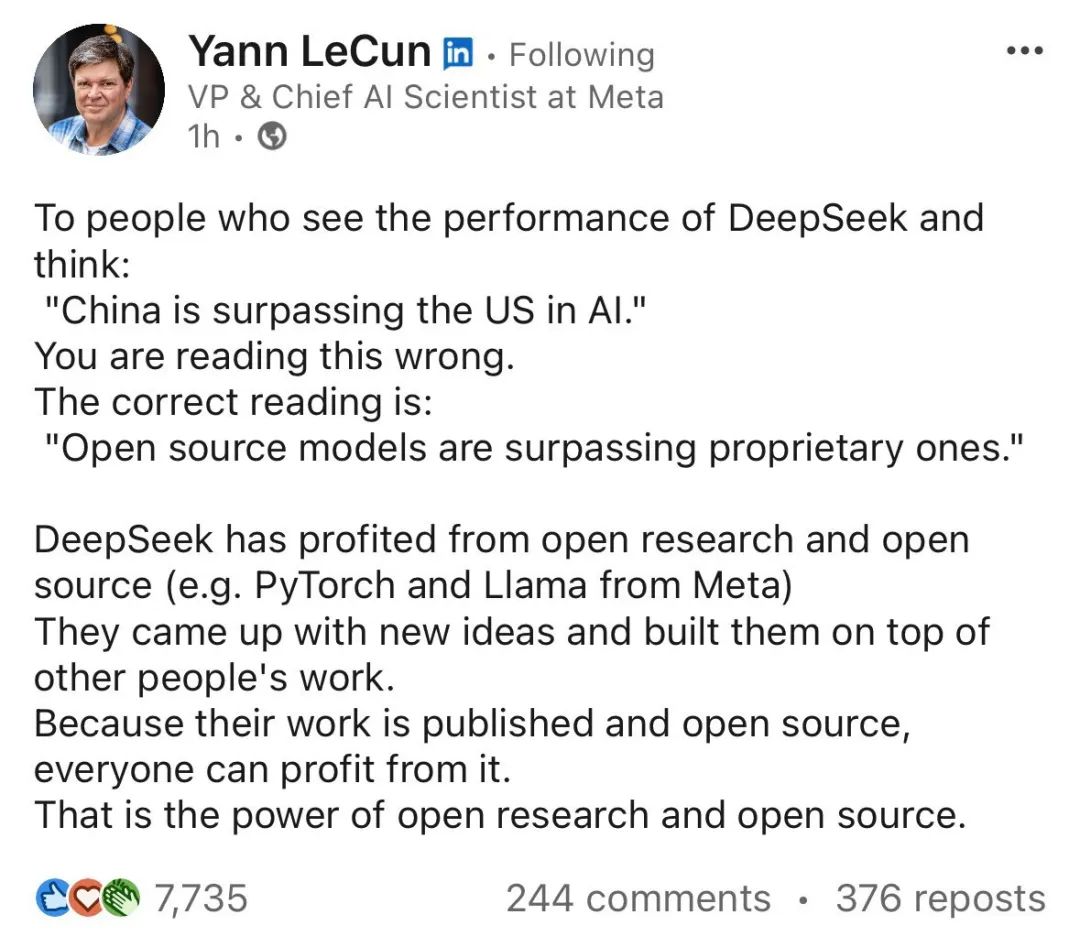
Scale AI CEO Alexandr Wang 直接破防,说 DeepSeek 有50000 台H100,但是由于美国的限制导致他们不能说自己有
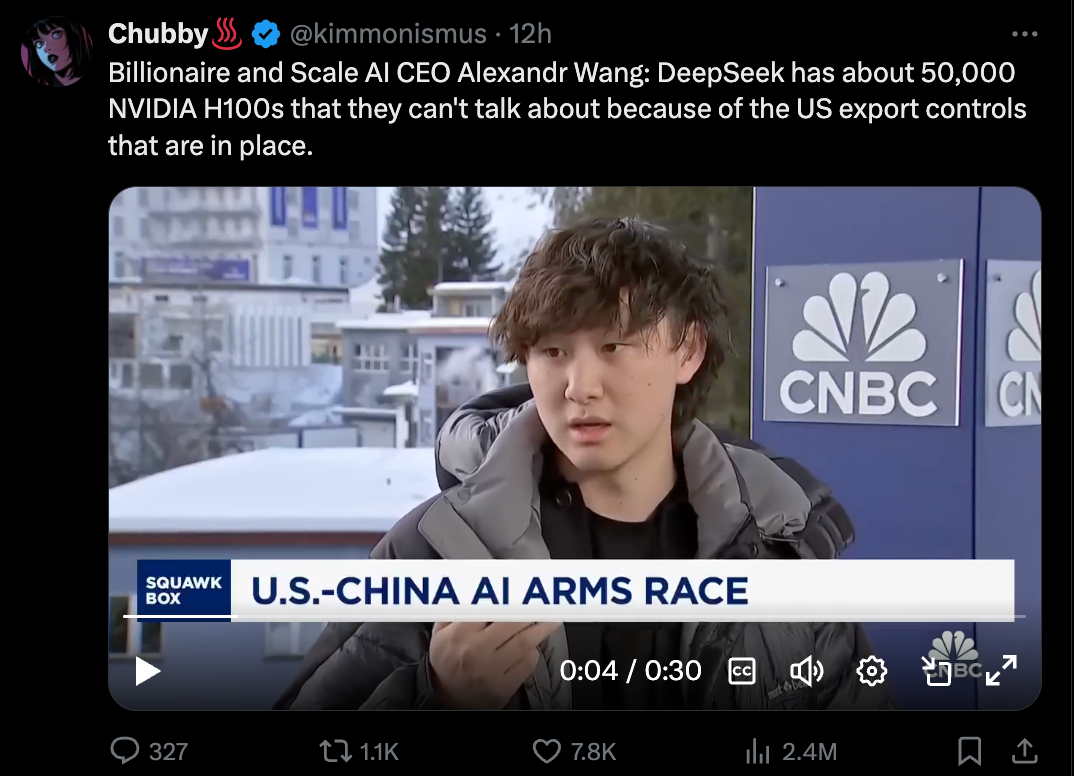
Meta的生成AI团队陷入恐慌!从DeepSeek V3横空出世开始,Llama 4的基准测试已被甩在后头,最糟糕的是,竟然有一家“未知的中国公司”投入550万美元的训练预算。这让Meta的工程师们开始疯狂拆解DeepSeek,试图复制它的一切。更让人担忧的是,Meta管理层面临着如何证明生成AI部门巨额开销的问题——毕竟,部门里的每一位“领导者”的薪酬都比训练DeepSeek V3的成本还要高,而且这样的“领导者”有很多。DeepSeek R1的推出更是让情况变得更为严峻。虽然无法透露机密信息,但不久后公众会知晓。原本应该是一个专注于工程的小团队,但由于一群人想借此提升影响力、膨胀招聘规模,最终大家都成了输家
经济学人专栏八卦

还有网友的众多反馈
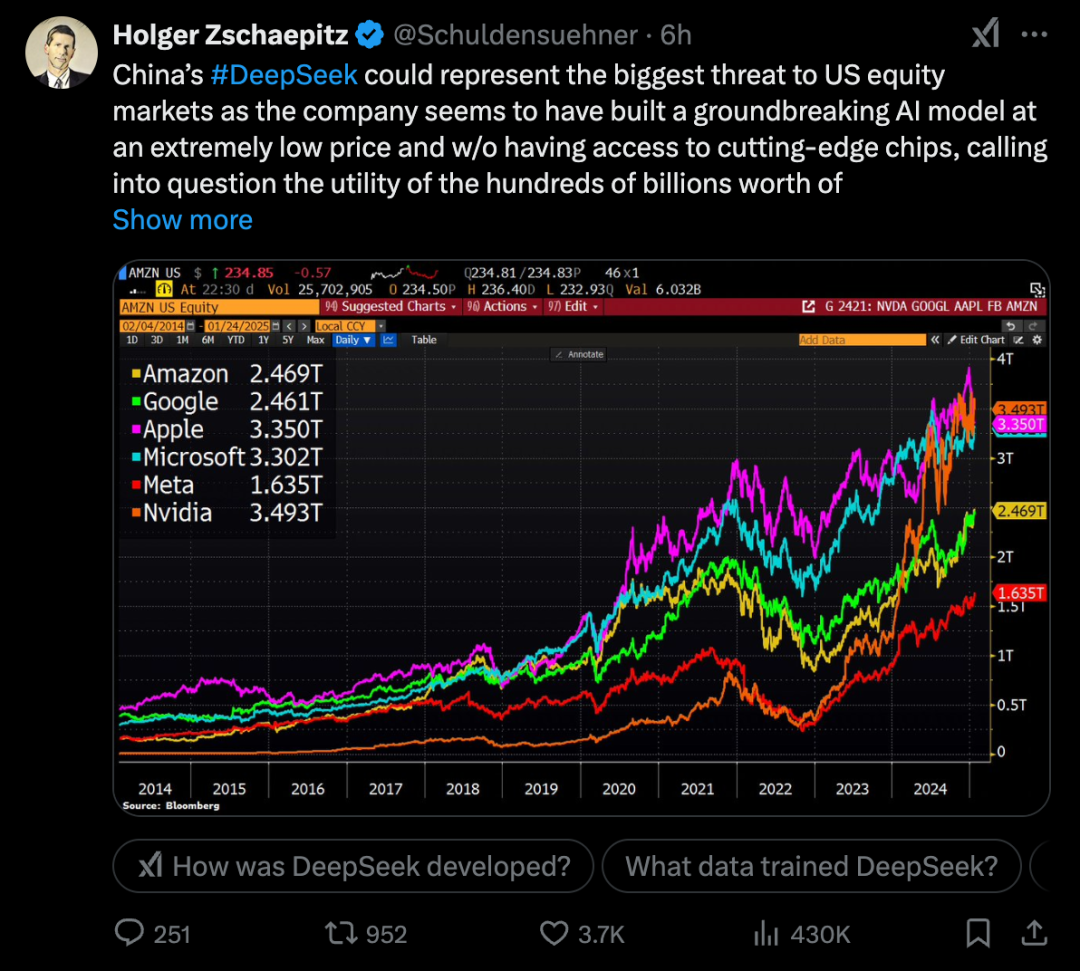
⭐
(文:AI寒武纪)