

点击上方“蓝色字体”关注我,每天推送“实用有趣的项目”!
最近,TTS 模型领域也真的是要过年了!陆续有各种新型的效果逼真的 TTS 模型发布!
就比如上周爆火的 TTS 排行榜No.1:Kokoro TTS。
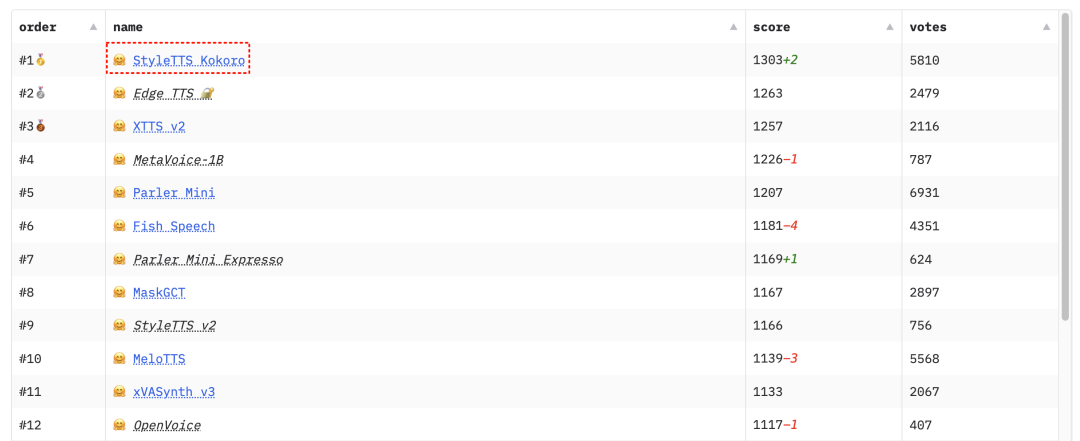
而今天再为大家分享一款新型的TTS 模型:Llasa TTS,该模型在近两天非常的热门。
不仅支持中英文的文本转语音功能,还支持语音克隆,只需15S的声音素材即可完美复刻,还能克隆目标语音的情感特色。
项目简介
Llasa TTS 是香港科技大学开发的一款基于 LLaMA 微调的 文本到语音(TTS)模型,支持中英双语生成。

模型训练使用了 250,000 小时的中英双语语音数据,与传统的 TTS 模型相比,Llasa 在语音自然性、情感表达以及风格匹配上都有显著提升。
不仅能从纯文本生成语音,还支持通过语音样例提示生成具有类似风格和情感的语音,表现力极其出色。
无论是为语音助手生成自然对话,还是用于配音和个性化语音场景,Llasa 都是一个非常出色的选择。
功能亮点
1、纯文本到语音
输入一段文字,即可生成自然流畅的语音,适合多场景应用,比如智能客服、有声读物、播客配音等。
2、语音风格克隆
通过提供 15 秒的语音样本,Llasa 能生成与提示语音风格一致的目标语音:
-
• 模仿语调、语速和语音特征。
-
• 实现情感语音(如快乐、悲伤、愤怒、耳语)生成。
3、双语支持
同时支持中文和英文,适用于多语言场景,尤其是需要中英混合生成的场合。
4、多模型支持
提供 1B 和 3B 参数规模模型,未来还将推出 8B 模型:
-
• 1B 模型:更快、更轻量化,适合资源受限设备。
-
• 3B 模型:更高质量,更细腻的语音表达。
5、开放权重
所有模型均提供开放权重,开发者可直接使用或二次微调,支持 Transformers 和 vLLM 框架。
使用方式
1、在线体验
HuggingFace 有现成的 Llasa-3B 的在线TTS项目,可快速体验 Llasa 的语音生成效果。
2、模型下载
可以在 HuggingFace 下载模型权重:
-
• Llasa-1B 模型:https://huggingface.co/HKUSTAudio/Llasa-1B
-
• Llasa-3B 模型:https://huggingface.co/HKUSTAudio/Llasa-3B
3、模型代码调用示例
下载模型权重并通过 transformers 或 vLLM 加载:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import soundfile as sf
llasa_3b ='HKUST-Audio/Llasa-3B'
tokenizer = AutoTokenizer.from_pretrained(llasa_3b)
model = AutoModelForCausalLM.from_pretrained(llasa_3b)
model.eval()
model.to('cuda')
from xcodec2.modeling_xcodec2 import XCodec2Model
model_path = "HKUST-Audio/xcodec2"
Codec_model = XCodec2Model.from_pretrained(model_path)
Codec_model.eval().cuda()
input_text = 'Dealing with family secrets is never easy. Yet, sometimes, omission is a form of protection, intending to safeguard some from the harsh truths. One day, I hope you understand the reasons behind my actions. Until then, Anna, please, bear with me.'
# input_text = '突然,身边一阵笑声。我看着他们,意气风发地挺直了胸膛,甩了甩那稍显肉感的双臂,轻笑道:"我身上的肉,是为了掩饰我爆棚的魅力,否则,岂不吓坏了你们呢?"'
def ids_to_speech_tokens(speech_ids):
speech_tokens_str = []
for speech_id in speech_ids:
speech_tokens_str.append(f"<|s_{speech_id}|>")
return speech_tokens_str
def extract_speech_ids(speech_tokens_str):
speech_ids = []
for token_str in speech_tokens_str:
if token_str.startswith('<|s_') and token_str.endswith('|>'):
num_str = token_str[4:-2]
num = int(num_str)
speech_ids.append(num)
else:
print(f"Unexpected token: {token_str}")
return speech_ids
#TTS start!
with torch.no_grad():
formatted_text = f"<|TEXT_UNDERSTANDING_START|>{input_text}<|TEXT_UNDERSTANDING_END|>"
# Tokenize the text
chat = [
{"role": "user", "content": "Convert the text to speech:" + formatted_text},
{"role": "assistant", "content": "<|SPEECH_GENERATION_START|>"}
]
input_ids = tokenizer.apply_chat_template(
chat,
tokenize=True,
return_tensors='pt',
continue_final_message=True
)
input_ids = input_ids.to('cuda')
speech_end_id = tokenizer.convert_tokens_to_ids('<|SPEECH_GENERATION_END|>')
# Generate the speech autoregressively
outputs = model.generate(
input_ids,
max_length=2048, # We trained our model with a max length of 2048
eos_token_id= speech_end_id ,
do_sample=True,
top_p=1, # Adjusts the diversity of generated content
temperature=0.8, # Controls randomness in output
)
# Extract the speech tokens
generated_ids = outputs[0][input_ids.shape[1]:-1]
speech_tokens = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
# Convert token <|s_23456|> to int 23456
speech_tokens = extract_speech_ids(speech_tokens)
speech_tokens = torch.tensor(speech_tokens).cuda().unsqueeze(0).unsqueeze(0)
# Decode the speech tokens to speech waveform
gen_wav = Codec_model.decode_code(speech_tokens)
sf.write("gen.wav", gen_wav[0, 0, :].cpu().numpy(), 16000)写在最后
Llasa 的推出为文本到语音的生成提供了一种更自然、更灵活的解决方案。
其支持多语言、多情感生成,以及示例语音风格克隆等功能,以及未来 8B 模型的发布及更多功能的扩展,Llasa 有潜力成为多语言、多场景语音生成的行业新标杆。
如果你正在寻找一款开源且高质量的 TTS 工具,Llasa 是一个不错的选择。不妨下载模型权重或在线体验,一起探索!
体验地址:https://huggingface.co/spaces/srinivasbilla/llasa-3b-tts

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)
Llasa TTS简直不要太强!比肩行业顶尖,15秒就能克隆完美语音,速度和质量都爆表,肯定是next big thing in TTS领域!