
香港科技大学

带图推理碾压同类开源模型!港中文微软等开源OpenThinkIMG框架,教AI学会使用视觉工具

港中文和微软联合团队推出OpenThinkIMG开源框架,旨在提升AI视觉工具使用和推理能力。该框架包含模块化视觉工具部署、高效的智能体训练框架及高质量数据生成技术,支持自主学习的V-ToolRL算法显著提升了AI在图表推理任务上的表现。
全新预训练数据筛选方案,让数据效率提升10倍!配置仅需fastText评分器|港科大vivo出品
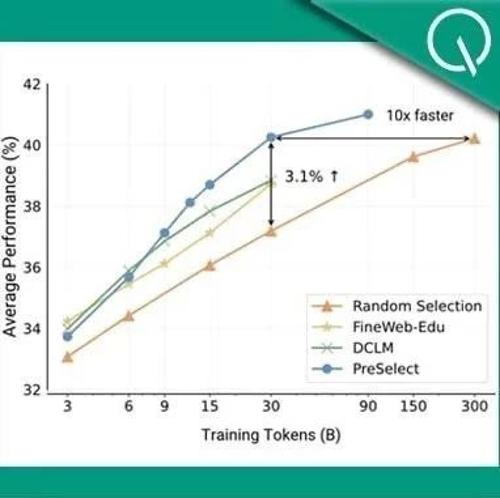
香港科技大学和vivo AI Lab提出PreSelect方法,通过预测强度计算公式量化评估数据对特定能力的贡献。该方法利用基于fastText的评分器减少10倍计算需求,具有客观性、泛化性和轻量级优势,相比现有SOTA方法提升显著。
AI音频最新发展:Anything万物生成音频
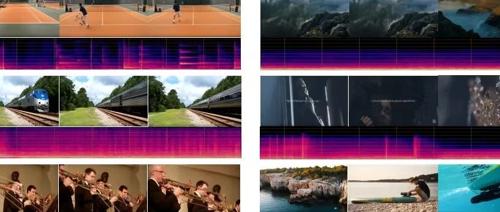
香港科技大学开发的 AudioX 机器学习模型能够根据用户的个性化输入生成独一无二的音频和音乐作品,包括文本、视频、图像等多模态数据,具有强大的跨模态学习能力,并能处理复杂的音频生成任务如音乐补全、修复等。
让机器人在人群中穿梭自如,港科广&港科大突破社交导航盲区 ICRA 2025

近期,香港科技大学研究团队提出了一种新算法Falcon,通过将轨迹预测算法融入社交导航任务中,实现了长期动态避障并提升导航性能。该算法已在ICRA 2025接收,并构建了两个新的数据集Social-HM3D和Social-MP3D作为社交导航的新基准。
单张照片实现三维重建,单视角室外复杂场景首次攻克| 西湖大学&港科大&Everlyn AI

西湖大学、香港科技大学等团队提出Niagara框架,首次有效解决单视角复杂室外场景三维重建问题。该方法结合深度与法线信息,采用几何仿射场和3D自注意力机制,显著提升细节捕捉精度及几何一致性。在RealEstate10K数据集上验证效果,优于当前最先进的Flash3D方法。
无需百卡集群!港科等开源LightGen: 极低成本文生图方案媲美SOTA模型

LightGen 是由香港科技大学 Harry Yang 教授团队联合 Everlyn AI 和 UCF 提出的一种新型高效图像生成模型,旨在解决主流生成模型依赖大量数据和计算资源的问题。论文提出通过知识蒸馏和直接偏好优化策略,在有限的数据和计算资源下实现了高质量图像的生成,并在多个实验中展示了与 SOTA 模型相当甚至超过的性能表现。
自动调整推理链长度,SCoT来了!为激发推理能力研究还提出了一个新架构

SCoT团队提出了一种新的推理范式SCoT,它能动态调整推理链长度来适应不同复杂度的问题。AtomThink框架则是一个全过程训练和评估的系统,旨在提升多模态大模型在复杂推理任务上的表现。
这个Atom of Thoughts 的原子思维让GPT-4O-Mini 秒杀O3和DeepSeek-R1!
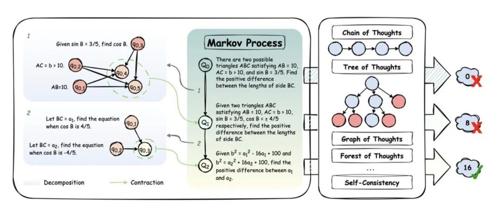
香港科技大学研究人员提出「原子思维」(AOT)改进了GPT-4o-mini在HotpotQA上的性能至80.6%,超越了现有方法。该技术通过将复杂问题分解为独立的子问题,实现更高效和准确的推理。
语音合成也遵循Scaling Law,太乙真人“原声放送”讲解论文 港科大等开源

Llasa团队分享了他们基于Transformer的语音合成模型的研究成果,该模型展示了通过扩展计算资源来提高语音合成效果的能力。研究揭示了训练时间和推理时间扩展对性能的影响,并开源了代码和权重以供其他研究人员参考。