
ICML 2025 抛弃全量微调!北大提出VGP范式,语义低秩分解解锁ViG高效迁移

北京大学提出VGP方法,通过语义低秩分解增强图结构图像模型的参数高效迁移能力,在多种下游任务中实现媲美全量微调的性能。
北京大学提出VGP方法,通过语义低秩分解增强图结构图像模型的参数高效迁移能力,在多种下游任务中实现媲美全量微调的性能。

本研究提出了一种基于3D隐式空间引导扩散模型的Playmate框架,用于音频驱动肖像动画生成。该方法通过解耦面部属性并引入情感控制模块实现了高质量、可控的情感表达和头部姿态调整。研究成果已在ICML2025收录,并展示了在FID、FVD及唇同步方面的优势。
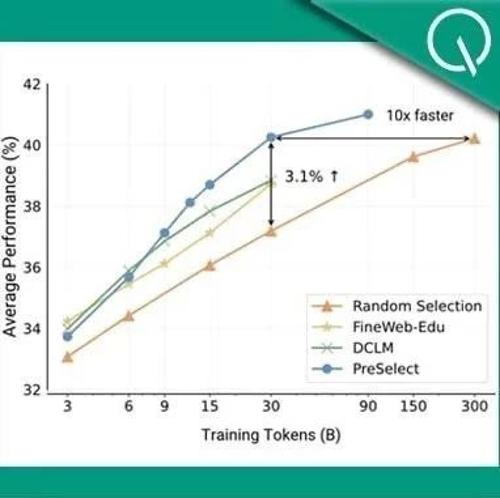
香港科技大学和vivo AI Lab提出PreSelect方法,通过预测强度计算公式量化评估数据对特定能力的贡献。该方法利用基于fastText的评分器减少10倍计算需求,具有客观性、泛化性和轻量级优势,相比现有SOTA方法提升显著。

清华大学叉院与星动纪元联合研发的VPP视频预测政策大模型,实现了从文本指令到机器人动作生成。该模型利用大量互联网视频数据训练,实现视频预测和实时执行,大幅提升机器人的操作策略泛化能力,并且已经全部开源。

近日,ICML 2025 新研究揭示大型语言模型中注意力机制的查询 (Q) 和键 (K) 表示存在极大值现象,而值 (V) 表示则没有这种模式。极大值对上下文理解至关重要,研究提出保护 Q 和 K 中的大值能有效维持模型的上下文理解能力。