

近日,北京大学在图神经网络(GNN)视觉建模方向提出全新方法 VGP(Vision Graph Prompting),通过语义低秩分解(Semantic Low-Rank Decomposition)有效增强图结构图像模型的参数高效迁移能力,赋能 Vision GNN(ViG)在多种下游任务中实现媲美全量微调的性能。
该研究已被人工智能顶会 ICML 2025 正式接收,相关论文与代码已全部开源。论文第一作者为北京大学博士生艾子翔,通讯作者为北京大学王选计算机研究所研究员、助理教授周嘉欢。

论文标题:
Vision Graph Prompting via Semantic Low-Rank Decomposition
论文链接:
https://arxiv.org/abs/2505.04121
代码链接:
https://github.com/zhoujiahuan1991/ICML2025-VGP
接收会议:
ICML 2025(CCF A 类)
作者单位:
北京大学王选计算机研究所

背景:图结构视觉建模的潜力与挑战
近年来,Vision GNN(ViG)模型通过将图像建模为图结构,在图神经网络中有效捕捉图像中非规则的语义分布,突破了传统 CNN 和 Transformer 模型中固定网格和序列结构的限制,成为视觉建模新范式。
然而,ViG的大规模模型在迁移到具体下游任务时,依赖传统的全量微调方式,造成巨大的计算与存储负担,难以适用于边缘设备或多任务部署场景。同时,现有视觉提示(Visual Prompting)方法大多针对Transformer设计,无法有效建模图结构中的语义拓扑关系,限制了其在图像图模型中的应用效果。


方法简介:语义低秩提示,唤醒ViG语义潜能
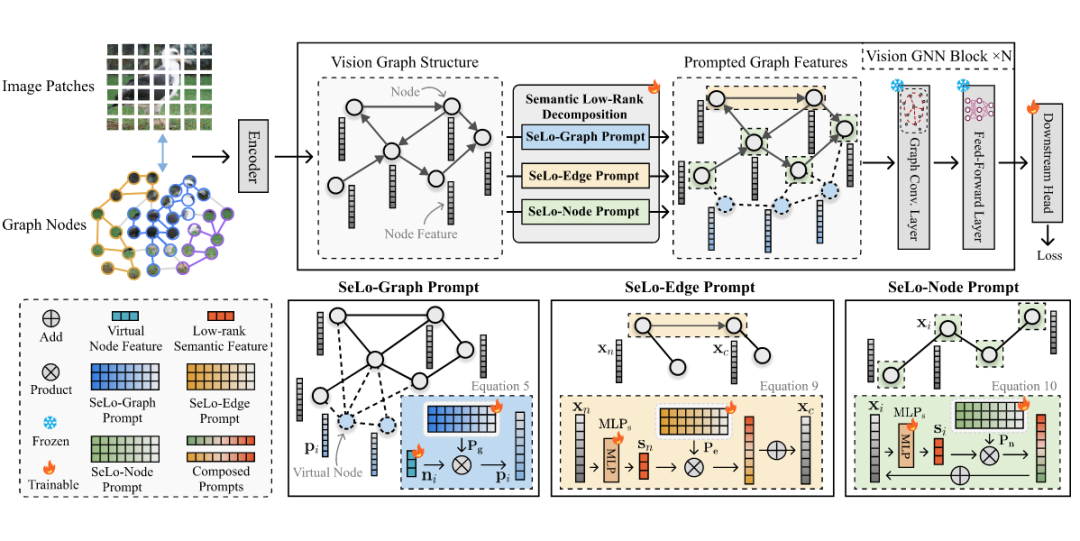
为解决上述难题,研究团队提出 Vision Graph Prompting(VGP),一种专为 ViG 设计的语义感知提示机制。该设计思想源于对图视觉模型中语义信息分布的关键发现:
在视觉图结构中,尽管语义相关的节点具有不同的局部外观细节,它们在主成分分析(PCA)中却表现出高度一致的低秩结构,这表明图结构中主要的语义信息集中于隐式特征空间的低秩成分。

基于这一观察,VGP 通过语义低秩分解,将图中的重要语义模式以低秩形式建模,并通过三种提示组件注入到图结构中:
-
SeLo-Graph Prompt(语义低秩图提示):添加可训练的虚拟节点,并与原始图动态连接,引导模型捕捉全局语义依赖。
-
SeLo-Edge Prompt(语义低秩边提示):在边级别进行低秩语义增强,突出重要连接,滤除无关局部噪声。
-
SeLo-Node Prompt(语义低秩点提示):对节点特征进行低秩建模,强化细粒度语义表达,保留局部关键细节。

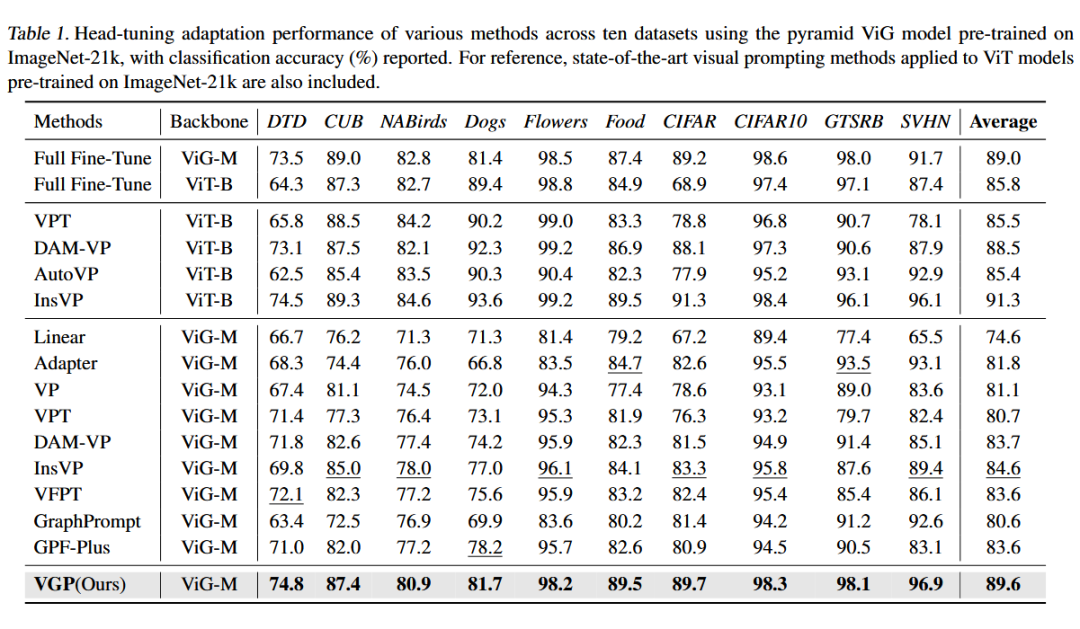
实验结果:高效迁移,精度媲美全量微调
在多个视觉下游任务数据集上,VGP 展现出超越现有视觉提示方法的性能,尤其在以下方面表现突出:
-
精度媲美全量微调,甚至在部分任务上超越;
-
参数量大幅减少,仅需极小比例的可训练参数;
-
有效利用 ViG 的语义拓扑结构,实现结构感知迁移。
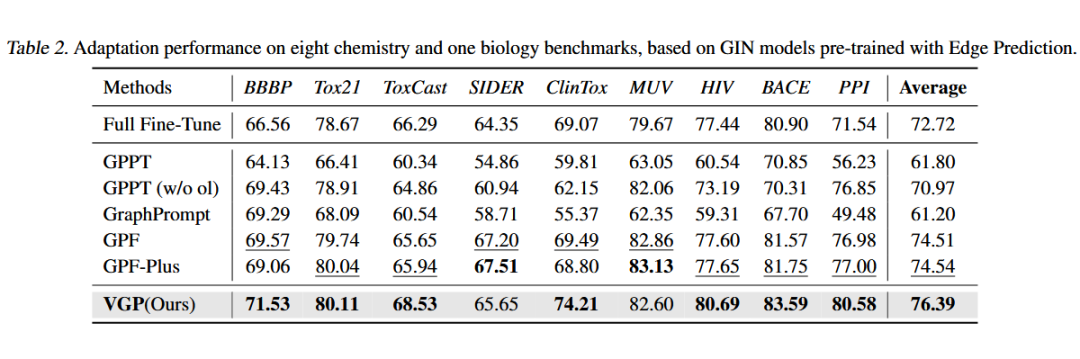
此外,本研究方法在传统的化学分子和生物信息图数据任务上,同样能够超越全参微调,显示出扩展到 AI4Science 领域的潜力。

应用价值:拓展图神经视觉模型的边界
VGP 为 Vision GNN 模型的下游适配提供了全新范式,具备广泛应用潜力:
-
高精度视觉理解:医疗图像分析、卫星遥感解读等需要全局语义建模场景;
-
边缘设备部署:自动驾驶、智能手机等对模型体积敏感场景;
-
多任务快速切换:在大模型基础上高效适配不同视觉任务。

未来展望
研究团队表示,将进一步扩展 VGP 至更复杂的图结构建模场景,如时空图建模、跨模态图-语言联合建模等,持续探索语义低秩分解在大模型高效迁移中的潜力。
(文:PaperWeekly)