LightGen 主要作者来自香港科技大学和 Everlyn AI, 第一作者为香港科技大学准博士生吴显峰,主要研究方向为生成式人工智能和 AI4Science。通讯作者为香港科技大学助理教授 Harry Yang 和中佛罗里达副教授 Sernam Lim。
共同一作有香港科技大学访问学生白亚靖,香港科技大学博士生郑皓泽,Everlyn AI 实习生陈浩东,香港科技大学博士生刘业鑫。还有来自香港科技大学博士生王子豪,马煦然,香港科技大学访问学生束文杰以及 Everlyn AI 实习生吴显祖。
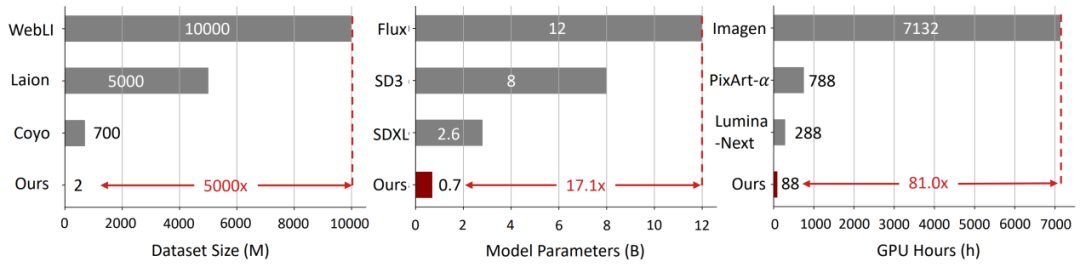
文本到图像(Text-to-Image, T2I)生成任务近年来取得了飞速进展,其中以扩散模型(如 Stable Diffusion、DiT 等)和自回归(AR)模型为代表的方法取得了显著成果。然而,这些主流的生成模型通常依赖于超大规模的数据集和巨大的参数量,导致计算成本高昂、落地困难,难以高效地应用于实际生产环境。
为了解决这一难题,香港科技大学 Harry Yang 教授团队联合 Everlyn AI 和 UCF,提出了一种名为 LightGen 的新型高效图像生成模型,致力于在有限的数据和计算资源下,快速实现高质量图像的生成,推动自回归模型在视觉生成领域更高效、更务实地发展与应用。
-
论文标题:LightGen: Efficient Image Generation through Knowledge Distillation and Direct Preference Optimization
-
论文链接:https://arxiv.org/abs/2503.08619
-
模型链接:https://huggingface.co/Beckham808/LightGen
-
项目链接:https://github.com/XianfengWu01/LightGen
LightGen 借助知识蒸馏(KD)和直接偏好优化(DPO)策略,有效压缩了大规模图像生成模型的训练流程,不仅显著降低了数据规模与计算资源需求,而且在高质量图像生成任务上展现了与 SOTA 模型相媲美的卓越性能。
LightGen 相较于现有的生成模型,尽管参数量更小、预训练数据规模更精简,却在 geneval 图像生成任务的基准评测中达到甚至超出了部分最先进(SOTA)模型的性能。
此外,LightGen 在效率与性能之间实现了良好的平衡,成功地将传统上需要数千 GPU days 的预训练过程缩短至仅 88 个 GPU days,即可完成高质量图像生成模型的训练。
LightGen 采用的训练流程主要包括以下关键步骤:
1. 数据 KD:利用当前 SOTA 的 T2I 模型,生成包含丰富语义的高质量合成图像数据集。这一数据集的图像具有较高的视觉多样性,同时包含由最先进的大型多模态语言模型(如 GPT-4o)生成的丰富多样的文本标注,从而确保训练数据在文本和图像两个维度上的多样性。
2.DPO 后处理:由于合成数据在高频细节和空间位置捕获上的不足,作者引入了直接偏好优化技术作为后处理手段,通过微调模型参数优化生成图像与参考图像之间的差异,有效提升图像细节和空间关系的准确性,增强了生成图像的质量与鲁棒性。
通过以上方法,LightGen 显著降低了图像生成模型的训练成本与计算需求,展现了在资源受限环境下获取高效、高质量图像生成模型的潜力。
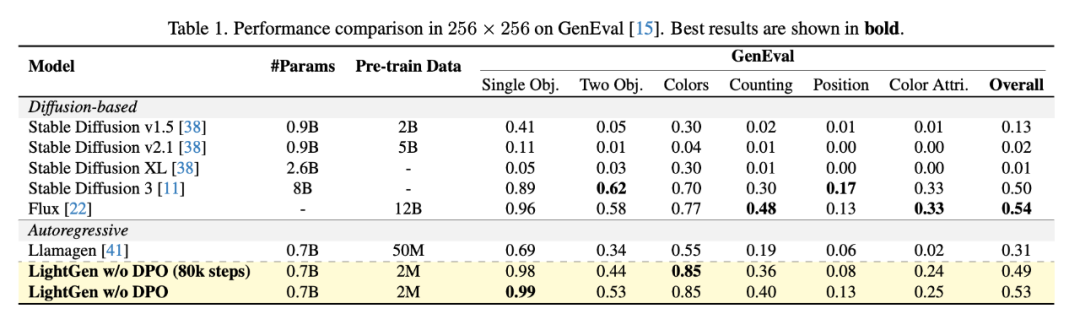
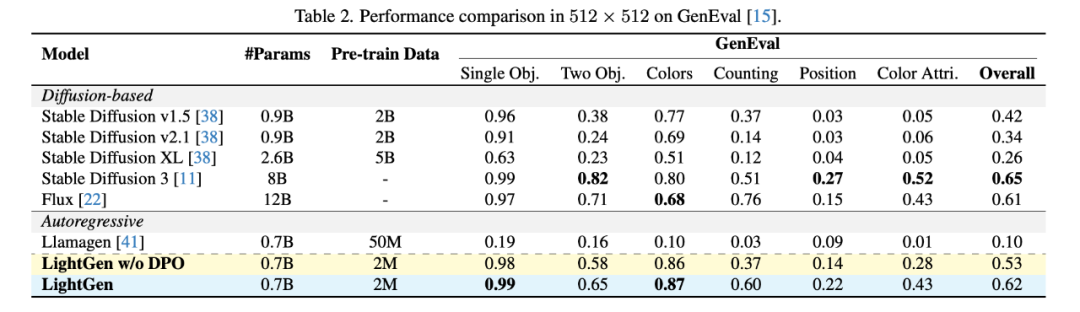
作者通过实验对比了 LightGen 与现有的多种 SOTA 的 T2I 生成模型,使用 GenEval 作为 benchmark 来验证我们的模型和其他开源模型的性能。
结果表明,我们的模型在模型参数和训练数量都小于其他模型的的前提下,在 256×256 和 512×512 分辨率下的图像生成任务中的表现均接近或超过现有的 SOTA 模型。
LightGen 在单物体、双物体以及颜色合成任务上明显优于扩散模型和自回归模型,在不使用 DPO 方法的情况下,分别达到 0.49(80k 步训练)和 0.53 的整体性能分数。在更高的 512×512 分辨率上,LightGen 达到了可比肩当前 SOTA 模型的成绩,整体性能分数达到 0.62,几乎超过所有现有方法。特别地,加入 DPO 方法后,模型在位置准确性和高频细节方面的表现始终稳定提升,这体现了 DPO 在解决合成数据缺陷上的有效性。
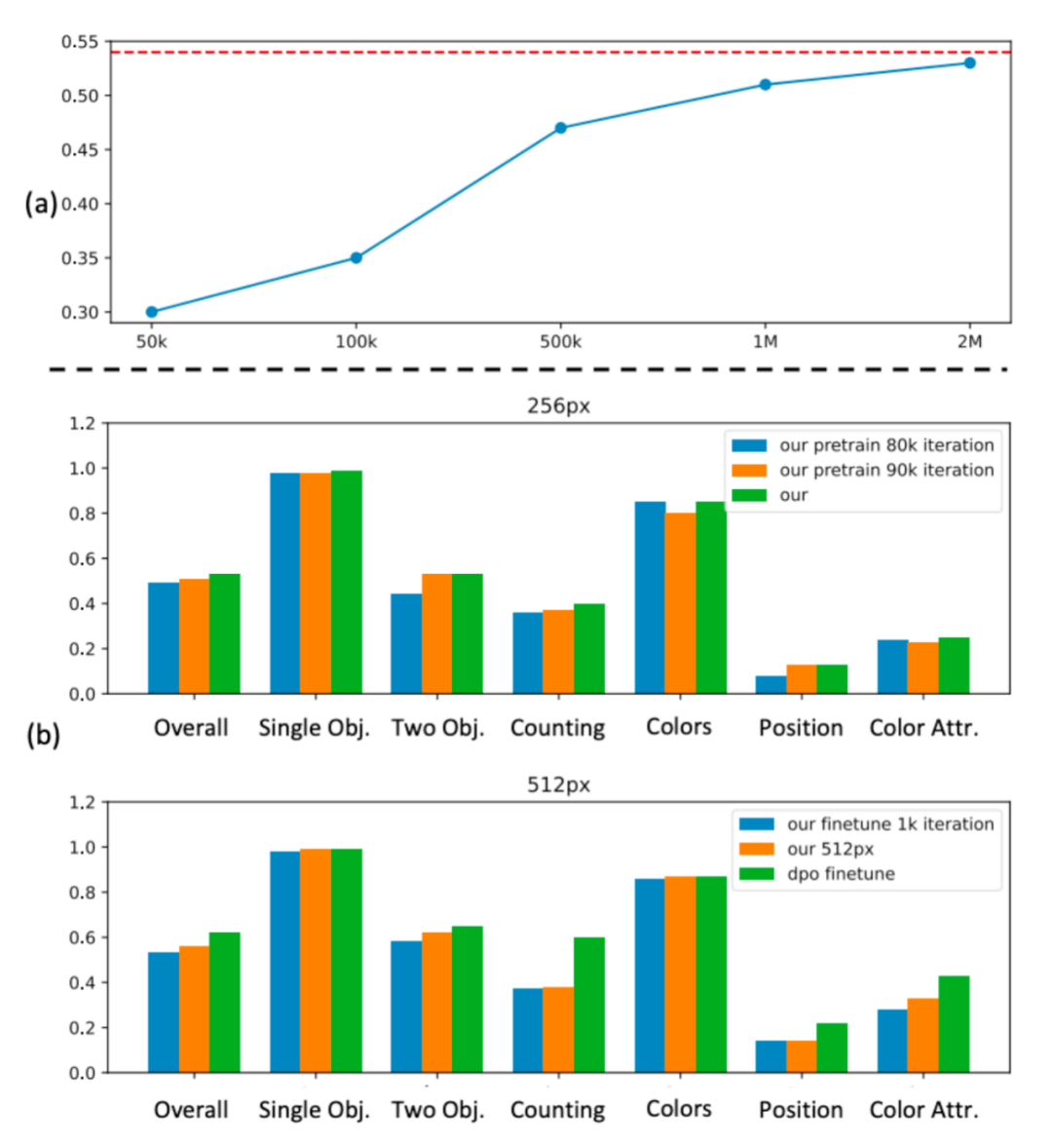
消融实验结果显示,当数据规模达到约 100 万张图像时,性能提升会遇到瓶颈,进一步增加数据规模带来的收益很有限。因此,我们最终选择了 200 万张图像作为最优的预训练数据规模。
上图 (b) 探讨了不同训练迭代次数对 GenEval 在 256 与 512 分辨率下性能的影响。值得注意的是,在 256 像素阶段,仅经过 80k 训练步数便能达到相当不错的性能,这突显了数据蒸馏方法在训练效率上的优势。
LightGen 研究有效地降低了 T2I 模型训练的资源门槛,证明了通过关注数据多样性、小型化模型架构和优化训练策略,可以在极少量数据和计算资源的情况下达到最先进模型的性能表现。未来研究可进一步探索该方法在其他生成任务(如视频生成)上的应用,推动高效、低资源需求的生成模型进一步发展,以实现更加广泛的技术普及与落地应用。
(文:机器之心)