

-
开源模型: 是 Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M,首次将开源 Qwen 模型的上下文扩展到 1M 长度。 -
推理框架: 完全开源了基于 vLLM 的推理框架,并集成了稀疏注意力方法,在处理 1M 长度输入时的速度能够提升 3倍到7倍。 -
技术报告:分享了 Qwen2.5-1M 系列背后的技术细节,包括训练和推理框架的设计思路以及消融实验的结果。
-
Qwen2.5-7B-Instruct-1M:至少需要 120GB 显存(多 GPU 总和)。 -
Qwen2.5-14B-Instruct-1M:至少需要 320GB 显存(多 GPU 总和)。
关键技术长上下文训练
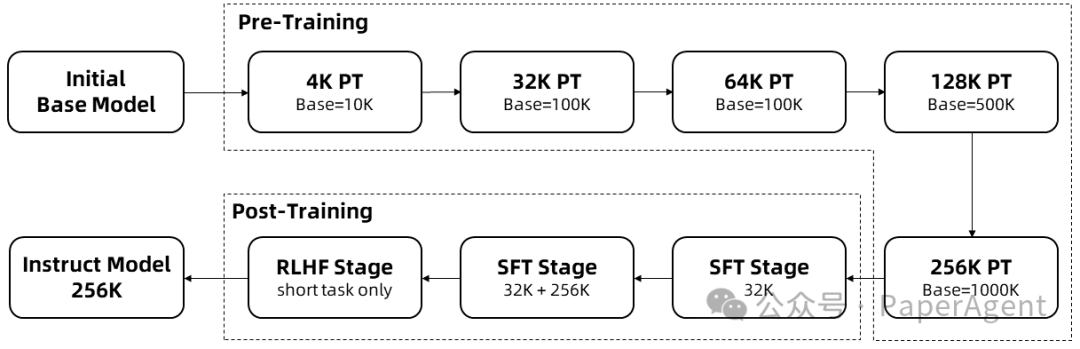
长序列的训练需要大量的计算资源,因此采用了逐步扩展长度的方法,在多个阶段将 Qwen2.5-1M 的上下文长度从 4K 扩展到 256K:
-
从预训练的Qwen2.5的一个中间检查点开始,此时上下文长度为4K。
-
在预训练阶段,逐步将上下文长度从 4K 增加到 256K,同时使用Adjusted Base Frequency的方案,将 RoPE 基础频率从 10,000 提高到 10,000,000。
-
在监督微调阶段,分两个阶段进行以保持短序列上的性能:
-
第一阶段: 仅在短指令(最多 32K 长度)上进行微调,这里使用与 Qwen2.5 的 128K 版本相同的数据和步骤数,以获得类似的短任务性能。
-
第二阶段: 混合短指令(最多 32K)和长指令(最多 256K)进行训练,以实现在增强长任务的性能的同时,保持短任务上的准确率。
-
在强化学习阶段,在短文本(最多 8K 长度)上训练模型。即使在短文本上进行训练,也能很好地将人类偏好对齐性能泛化到长上下文任务中。
通过以上训练,最终获得了 256K 上下文长度的指令微调模型。
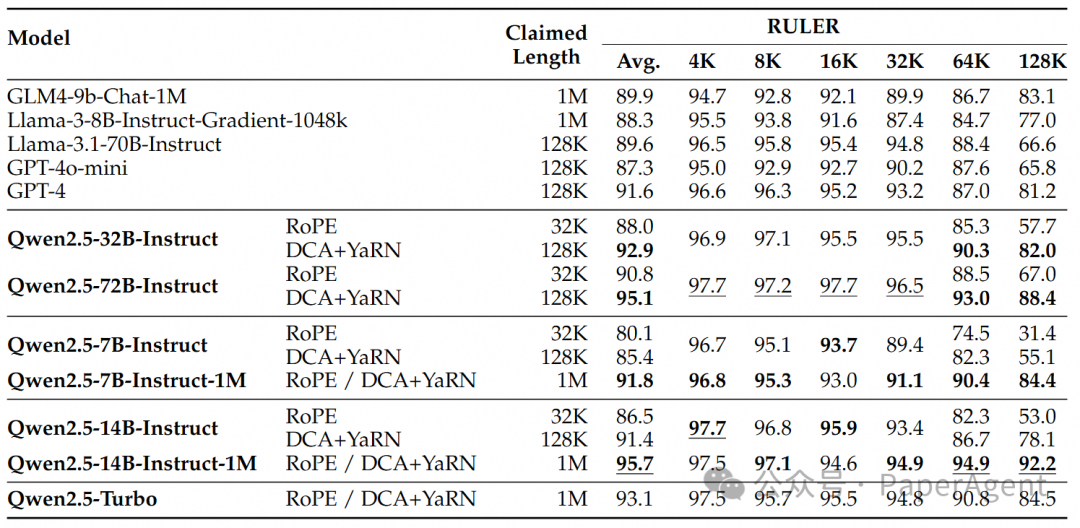
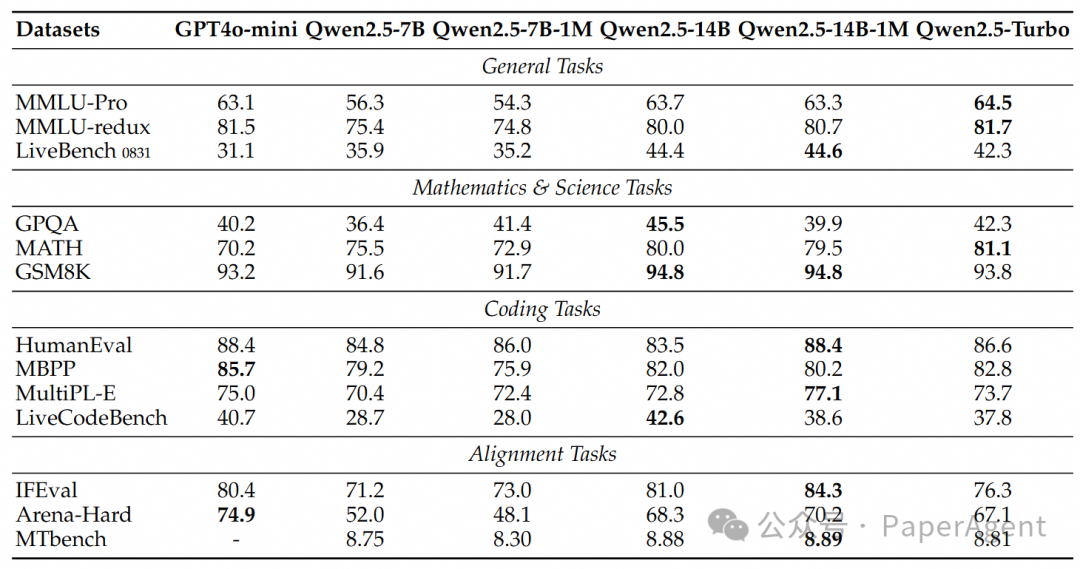
https://qwenlm.github.io/zh/blog/qwen2.5-1m/https://hf-mirror.com/Qwen/Qwen2.5-14B-Instruct-1Mhttps://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
(文:PaperAgent)