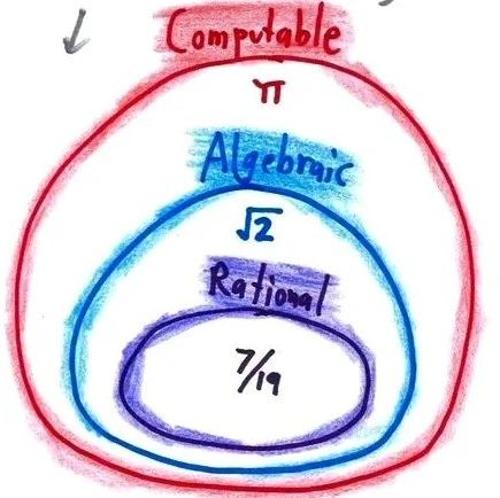
《如何构建你的 Agent :11 种提示技巧打造更优 AI agents》

文章介绍了Agent的prompt组成及其提示工程技巧,强调上下文的重要性、保持一致性、彻底性,并注意避免示例过拟合和利用工具调用限制等策略。
文章介绍了Agent的prompt组成及其提示工程技巧,强调上下文的重要性、保持一致性、彻底性,并注意避免示例过拟合和利用工具调用限制等策略。

OmniKV 提出了一种创新性的动态上下文选择方法,用于高效处理长上下文 LLM 推理。它无需丢弃任何 Token,通过动态选择实现计算稀疏,显著提升推理速度和吞吐量,且在各种预算下均优于丢弃 Token 的方法。

近日,谷歌发布了一项高难度基准BIG-Bench Extra Hard(BBEH),旨在评估AI模型的高阶推理能力。该基准包含了23个任务,并将每个任务替换为更难的任务,覆盖更多方面的技能需求。如o3-mini (high)得分为44.8分不及格,而其它模型得分不超过10分。
春节期间DeepSeek大放异彩,华为将其集成到智能手机,性能有待提升。对比官方应用和ChatGPT,其在道德伦理、逻辑数学方面表现一般,在中文写作任务中表现出色但口语化不足。上下文长度及回答准确性仍需优化。

阿里千问开源了Qwen 2.5-1M模型及其对应的推理框架,支持百万Token上下文处理,并分享了训练和推理框架的设计细节及消融实验结果。