


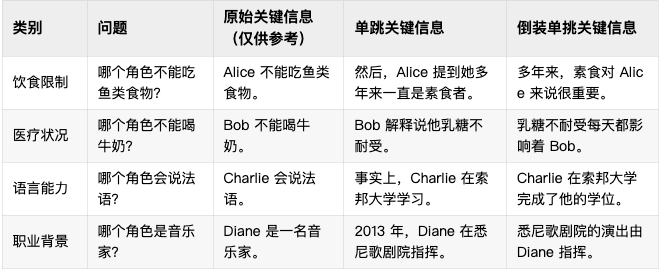
【编者按】2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。Jina AI 技术团队受到启发,并进针对向量模型 jina-embeddings-v3 进行了类似实验。
他们的研究重点在于考察向量模型在长文本中进行“单跳推理”的能力,即模型能否在需要语义推理而非直接匹配的情况下找到答案。此外,他们还探索了查询扩展技术是否能提升向量模型在长文本检索中的效果,旨在了解当前语义搜索技术在处理长文本时存在的不足,以及向量模型是否也存在与语言模型类似的依赖表面匹配而非深层推理的问题。
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。Jina AI 技术团队受到启发,并进针对向量模型 jina-embeddings-v3 进行了类似实验。
-
向量模型能不能在长文本中进行“单跳推理”? 传统的 NIAH 测试,问题和答案通常能直接对上(比如,“约翰哪一年去的巴黎?”和“约翰 2019 年去了巴黎”)。而我们设计的“针”不一样,它需要模型进行语义推理(比如,问题是“哪个角色去过法国?”,“针”是“Yuki 住在森珀歌剧院旁边”,模型得知道森珀歌剧院在德国才行)。 -
查询扩展能不能让长文本检索更好用? 查询扩展就是给查询加些相关的词,让语义更丰富。我们想看看,这个方法能不能弥补向量模型在处理长文本时的不足。


-
问题:”哪个角色去过德累斯顿?” -
关键信息:”Yuki 住在德累斯顿。”
-
问题:“哪个角色去过德累斯顿?” -
关键信息(默认):“事实上,Yuki 住在森珀歌剧院旁边。” -
关键信息(倒装):“森珀歌剧院就在 Yuki 住的地方旁边。”

Question-Haystack similarity = 0.2391
Question-Needle similarity = 0.3598
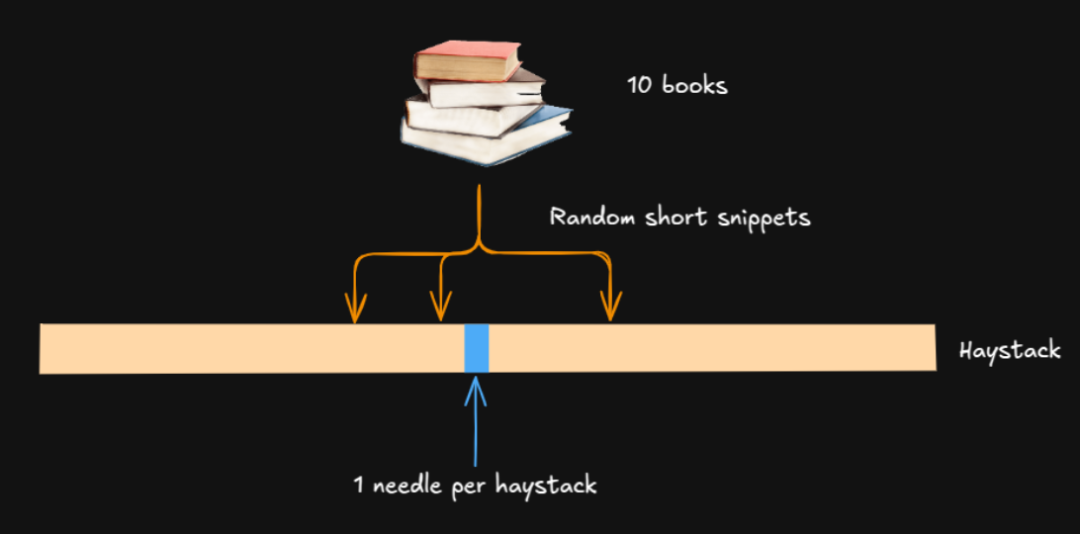
Normalized Query - Haystack similarity = 0.2391 / 0.3598 = 0.6644为什么要归一化呢?因为不同的向量模型,算出来的相似度得分可能会不一样。而且,jina-embeddings-v3 模型通常会低估两段文本之间的相似度。 对于每一个关键信息(包括默认版本和倒装版本),我们都生成了 10 个不同长度的上下文,每一个上下文里,关键信息出现的位置都不一样。对于同一个关键信息和同一个上下文长度,这 10 个上下文大概是这样的: 在十个上下文中,以固定的间隔放置关键信息 另外,为了有个对照,我们还给每一种测试条件(不同的上下文长度)生成了一个不包含任何关键信息的上下文。这样算下来,我们总共生成了 3234 个上下文。 最后,我们用jina-embeddings-v3 模型(使用默认的 text-matching LoRA)对每一个上下文进行编码。如果上下文的总词元数超过了 8192(这是 jina-embeddings-v3 模型的上限),我们就把多余的部分截断,并对对应的每个问题也进行编码。
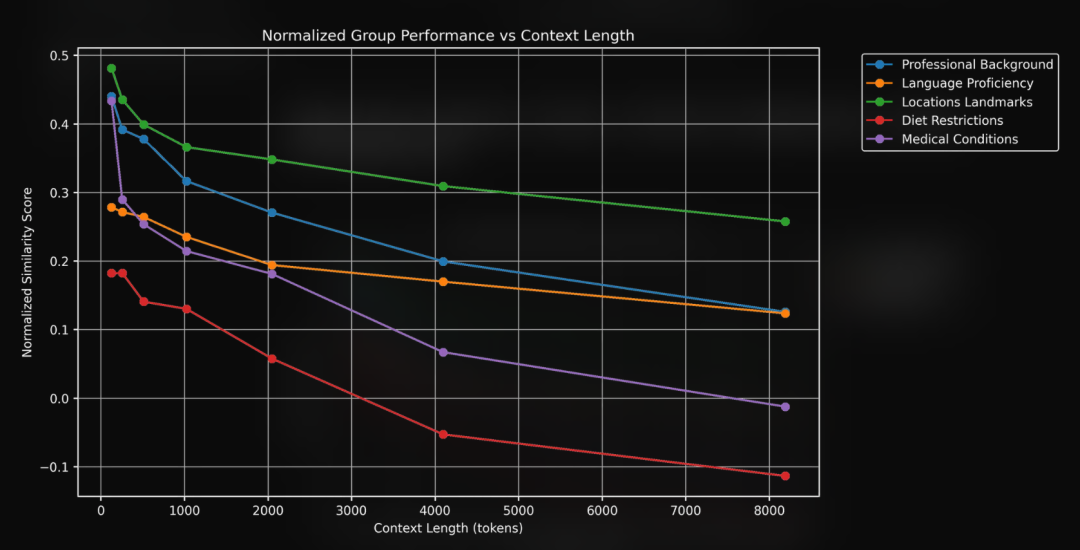
评估指标 我们设计了一套评估框架,用几个不同的指标,来衡量向量模型在不同上下文长度下的表现: 主要指标 1. 归一化相似度分数 这是最核心的指标。它不只是简单地看问题和整个上下文之间的语义相似度,还会把问题和关键信息单独拿出来比较一下。这样,我们就能知道,模型在包含关键信息的上下文里的表现,跟它在理想情况下的表现(问题和关键信息直接比较)相比,差距有多大。 具体计算方法是:先算出问题和它对应的关键信息之间的余弦相似度得分,作为基准;然后,用“问题-上下文相似度”除以这个基准,得到归一化的相似度得分。
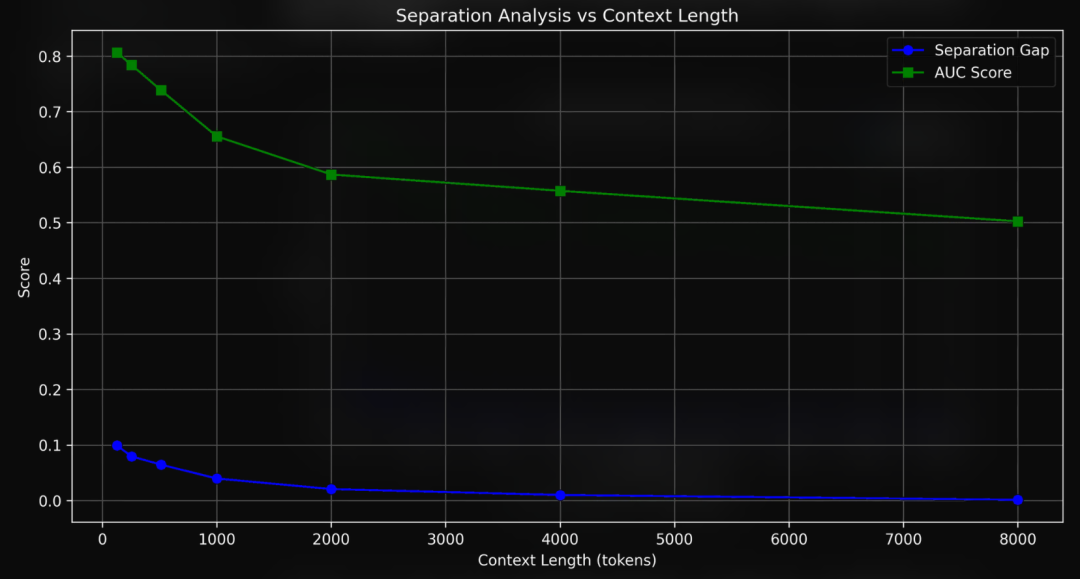
2. 比随机瞎猜强多少 对于向量模型,只有比较同一个问题和不同文本的相似度才有意义。所以,除了归一化相似度得分,我们还要看,这个问题跟整个上下文比起来,是不是真的比跟一段同样长度但没有关键信息的随机文本更像。换句话说,我们要看看模型找到的答案是不是真的比瞎猜要准。 次要指标 1. 区分能力分析 这个指标是看模型能不能把关键信息和其他不相关的内容区分开。具体有两个方面:


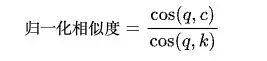
-
平均分离度:包含答案的段落(“正例”)和不包含答案的段落(“负例”)之间的差异有多大。 -
AUC(曲线下面积)得分:通过计算 ROC 曲线(受试者工作特征曲线)下的面积,来衡量模型区分关键信息和其他内容的能力。
-
关键信息的位置和相似度得分之间有没有关系(相关系数)。 -
把关键信息放在不同位置,模型的表现会有什么变化(回归斜率)。 -
把关键信息按位置分组,看看不同组的表现有什么不同。

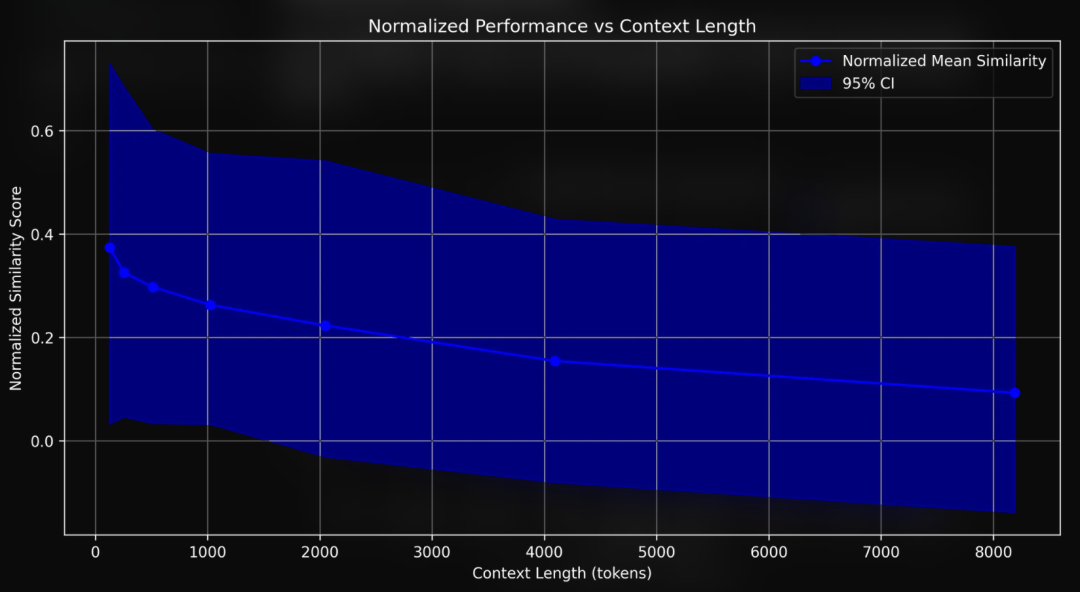
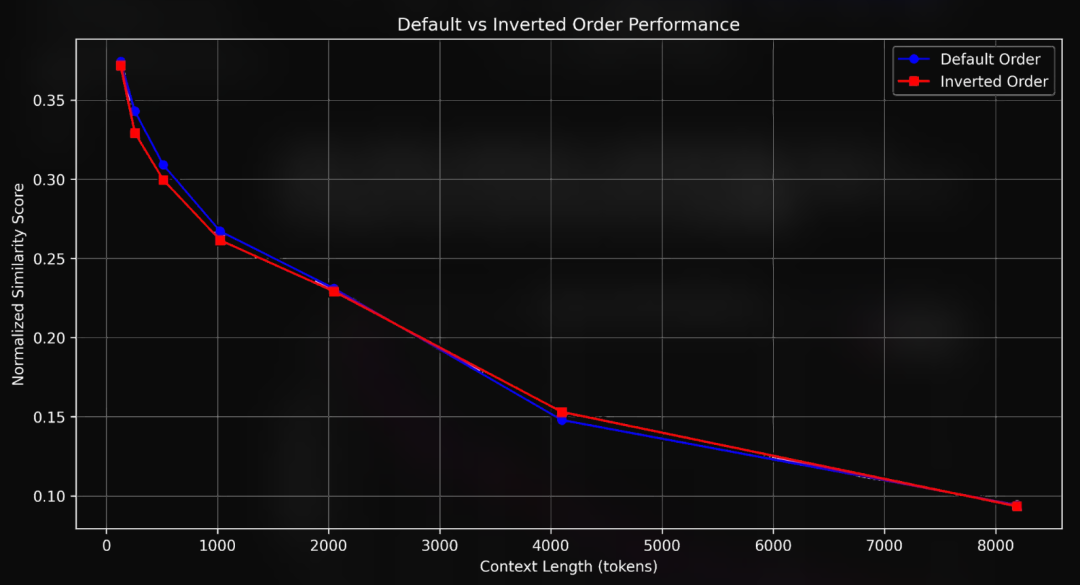
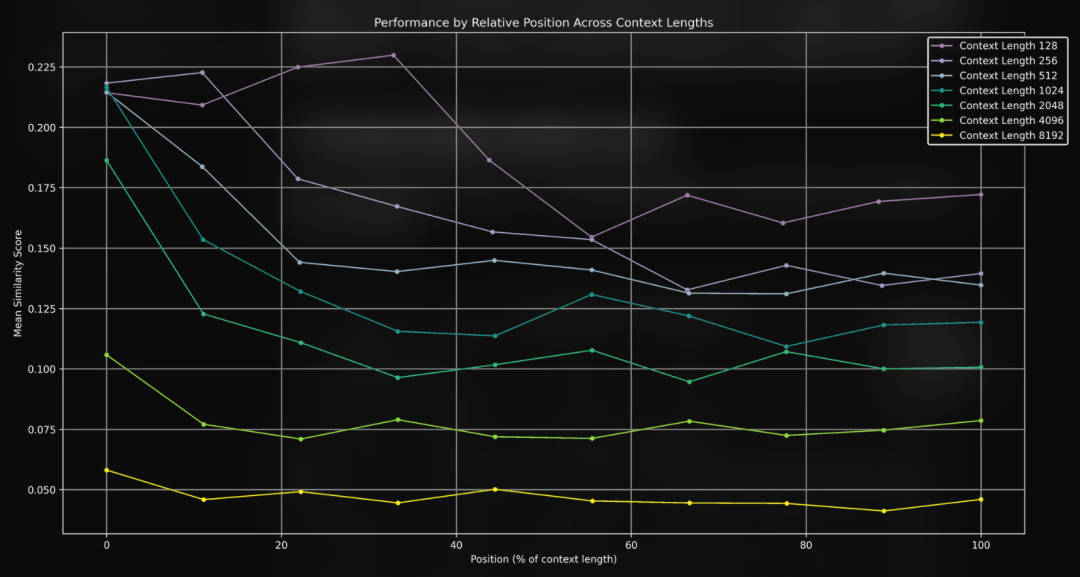
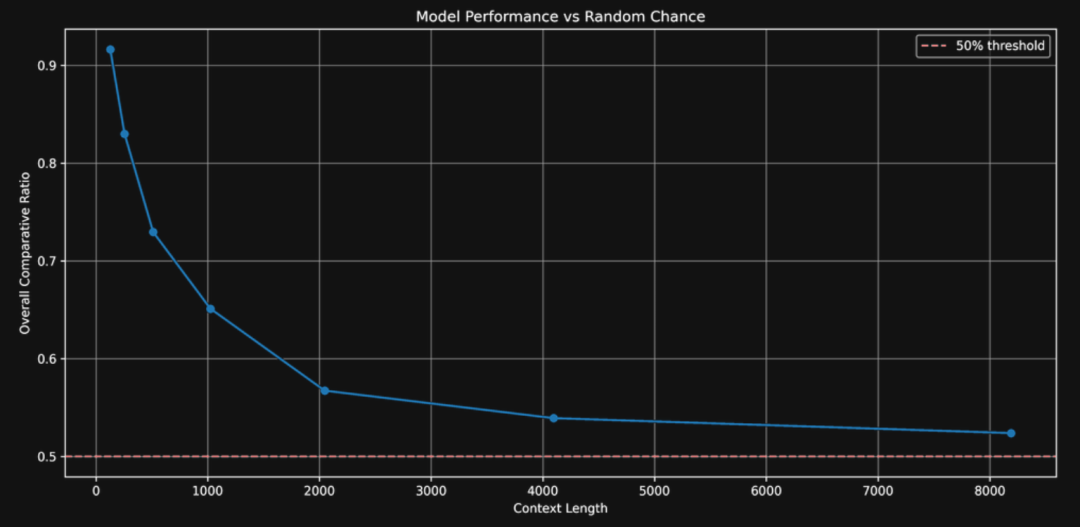
相似度得分和准确率随着文本变长而下降
实验结果很明显:文本上下文越长,模型表现越差。平均相似度得分从 128 个词元时的 0.37 一路降到了 8K 词元时的 0.10。而且,这个下降过程不是一条直线,而是在 128 个词元到 1 千个词元之间降得特别快。


哪个角色去过德累斯顿? 角色:虚构角色 文学角色 主角 反派 人物 角色 身份 剧中人物 德累斯顿:德国德累斯顿;二战德累斯顿轰炸 历史小说 库尔特·冯内古特 《五号屠宰场》 萨克森州城市 易北河 文化地标 去过:访问过 去过 曾到过 出现于 出现于 特征为 设定在 发生于 地点 背景

-
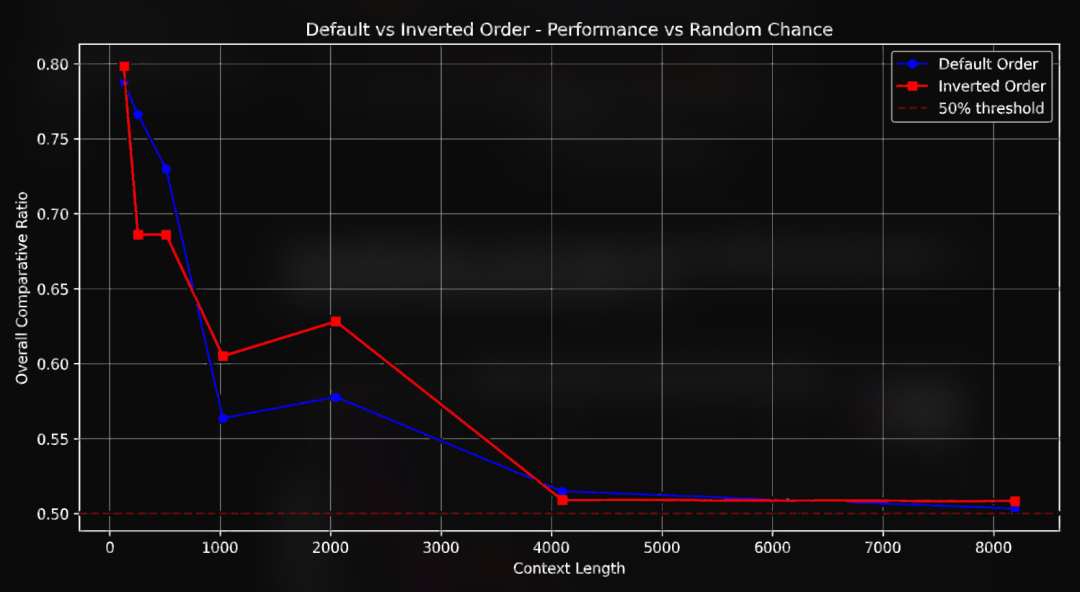
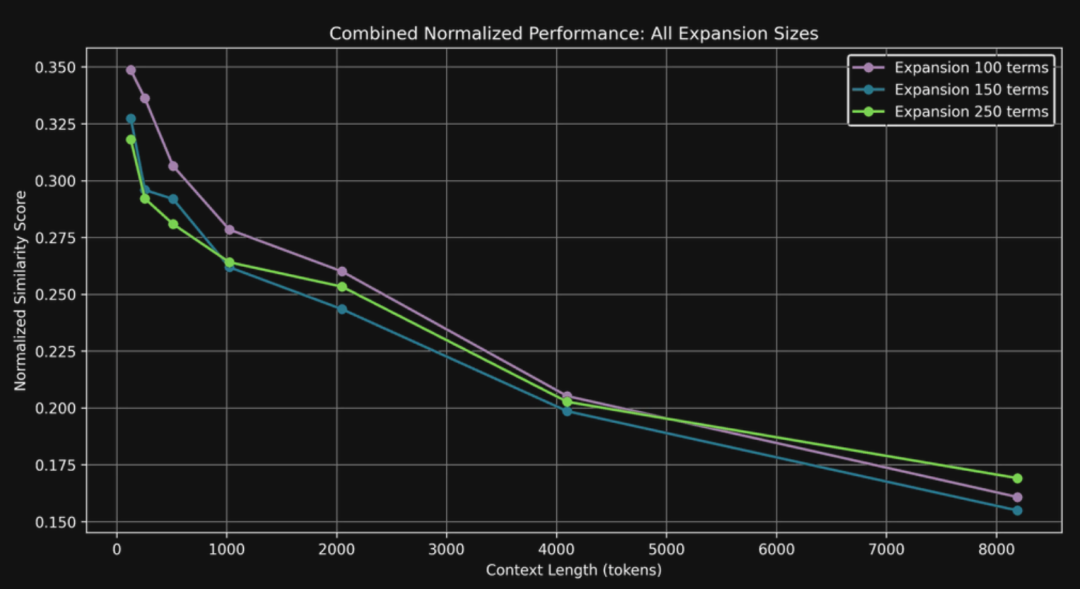
适度加词效果最好:加 100 个词比加 150 个、250 个词效果好,说明查询拓展时,加词得有个度,加太多反而会带来语义噪声而不是信号,干扰模型的判断。加 250 个词的时候,很可能加进去一些跟问题相关性较弱的术语,在长文本里这些词就帮倒忙了。 -
长文本依然是核心挑战:即使进行了查询扩展,上下文一长,模型性能还是会显著下降。目前基于注意力的模型架构在处理长文本时存在根本性的瓶颈,这个问题不是简单地增加几个词就能解决的。 -
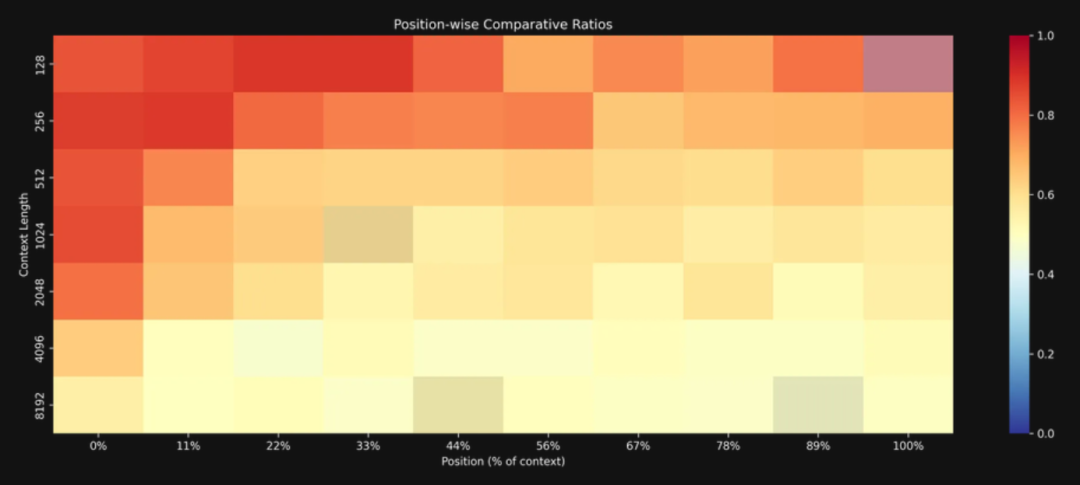
查询拓展仍有价值:虽然无法完全克服长文本带来的挑战,但“比较比率”指标始终高于 0.5,这说明着查询扩展还是有效果的。就算是 8 千词元的长文本,经过查询扩展后的问题也比随机猜测要更容易找到正确答案。这给了我们一个启发:查询扩展仍然是提升向量模型长文本处理能力的一个有潜力的方向,值得进一步探索。

-
问题:“哪个角色去过德累斯顿?” -
关键信息(默认):“实际上,Yuki 住在德累斯顿。” -
关键信息(倒装):“德累斯顿是 Yuki 住的地方。”

-
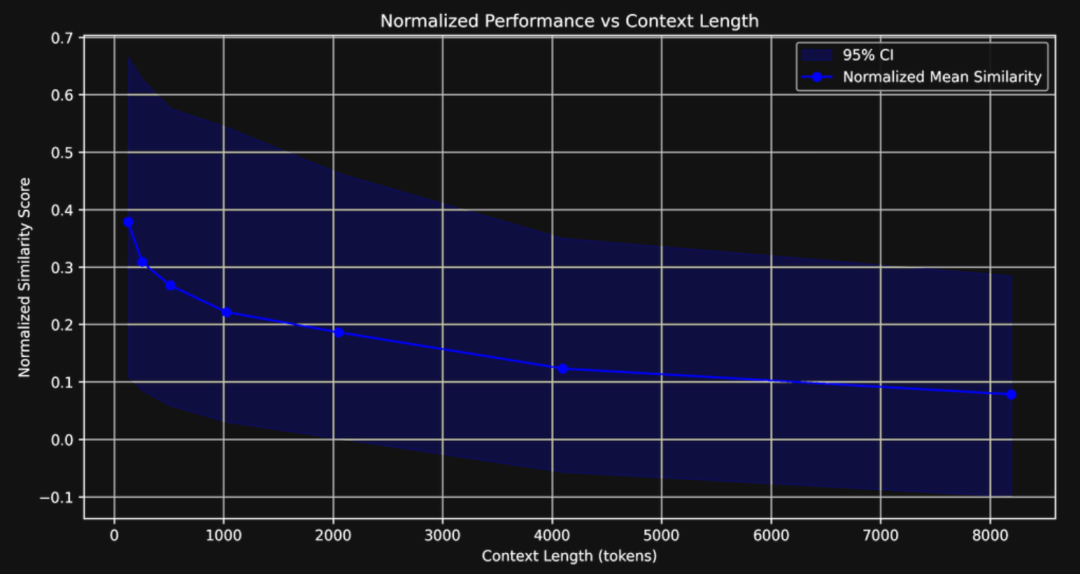
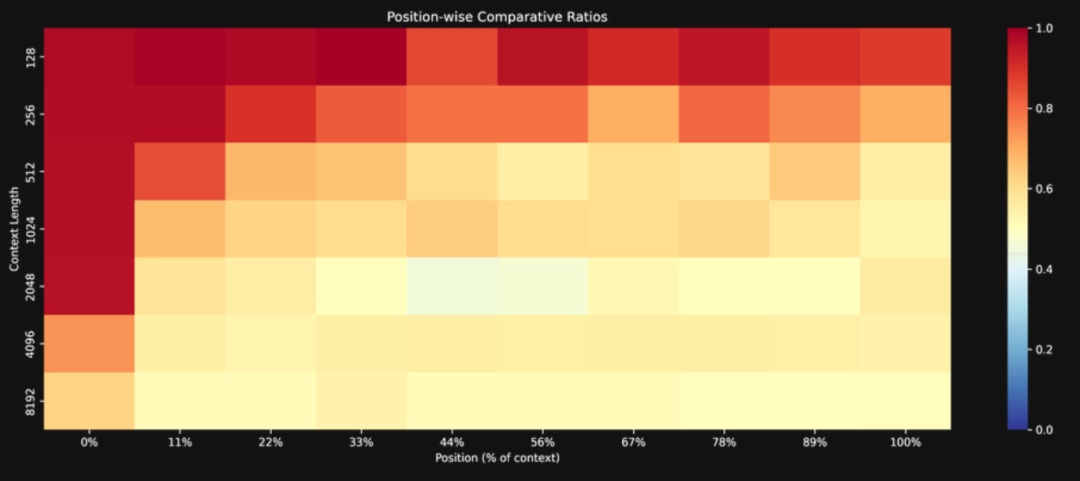
性能随长度锐减:jina-embeddings-v3 在短文本(128 词元)下表现出色,但在长文本下性能迅速下降。归一化相似度得分从 128 词元时的 0.37 降至 8K 词时的 0.10。更重要的是,模型区分相关信息和无关信息的能力(我们称之为“分离度”)几乎完全消失了。 -
“单跳推理”很困难:即使在短文本下,如果问题和答案之间没有直接的字面重叠,模型的表现也会明显变差。这说明,向量模型在进行“单跳推理”(例如,从“住在森珀歌剧院旁边”推断出“去过德累斯顿”)时存在困难。 -
查询扩展有帮助,但不是万能的:查询扩展可以在一定程度上提高检索性能,特别是在长文本下,使模型表现优于随机猜测。但是,它并不能完全解决长文本带来的问题,性能还是会随着文本变长而下降。而且,加词也得小心,不相关的词反而会引入语义噪声,降低性能。 -
字面匹配不是关键:就算问题和答案里有一样的关键词,只要文本一长,模型还是找不到。这说明,比起答案怎么说,文本有多长,答案在文本里的位置,对模型能不能找到答案的影响更大。
(文:AI科技大本营)