

-
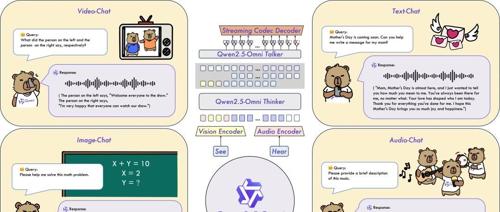
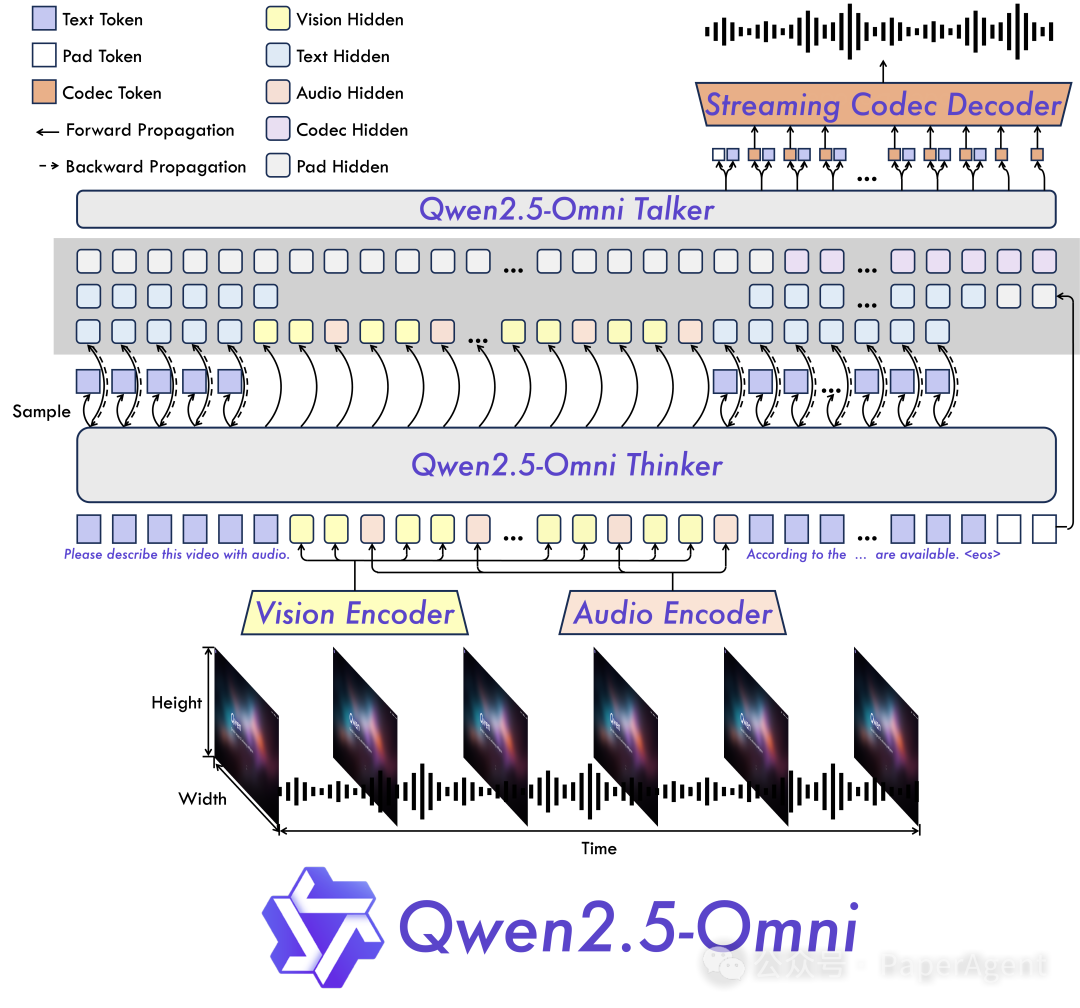
全模态与创新架构:提出了 Thinker-Talker 架构,这是一款端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式方式生成文本和自然语音响应。我们提出了一种名为 TMRoPE(时间对齐多模态 RoPE)的新型位置嵌入,用于同步视频输入与音频的时间戳。 -
实时语音和视频聊天:该架构专为完全实时交互而设计,支持分块输入和即时输出。 -
自然且稳健的语音生成:超越了许多现有的流式和非流式替代方案,在语音生成方面展现出卓越的稳健性和自然性。 -
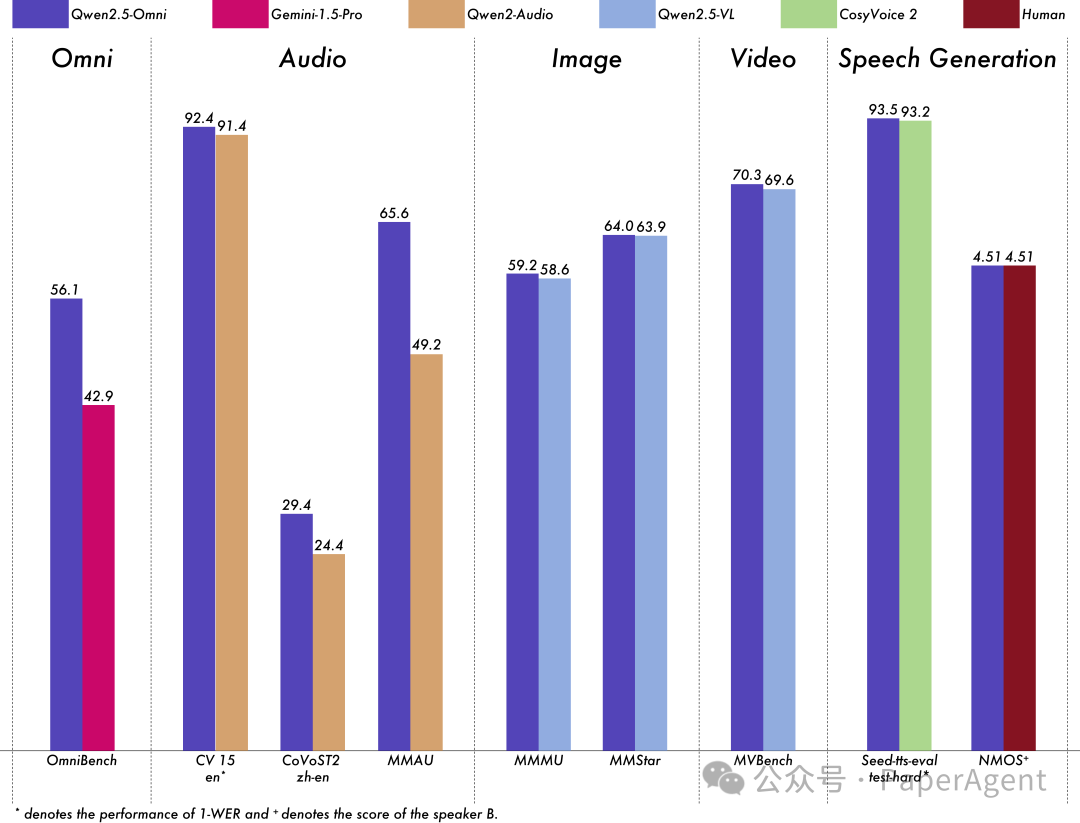
跨模态的卓越性能:在与同样大小的单模态模型进行对比时,展现了在所有模态上的卓越性能。Qwen2.5-Omni 在音频能力上超越了同样大小的 Qwen2-Audio,并且在性能上与 Qwen2.5-VL-7B 相当。 -
出色的端到端语音指令遵循能力:Qwen2.5-Omni 在端到端语音指令遵循方面的表现可与文本输入的效果相媲美,这一结论得到了 MMLU 和 GSM8K 等基准测试的验证。

https://hf-mirror.com/Qwen/Qwen2.5-Omni-7B
(文:PaperAgent)