

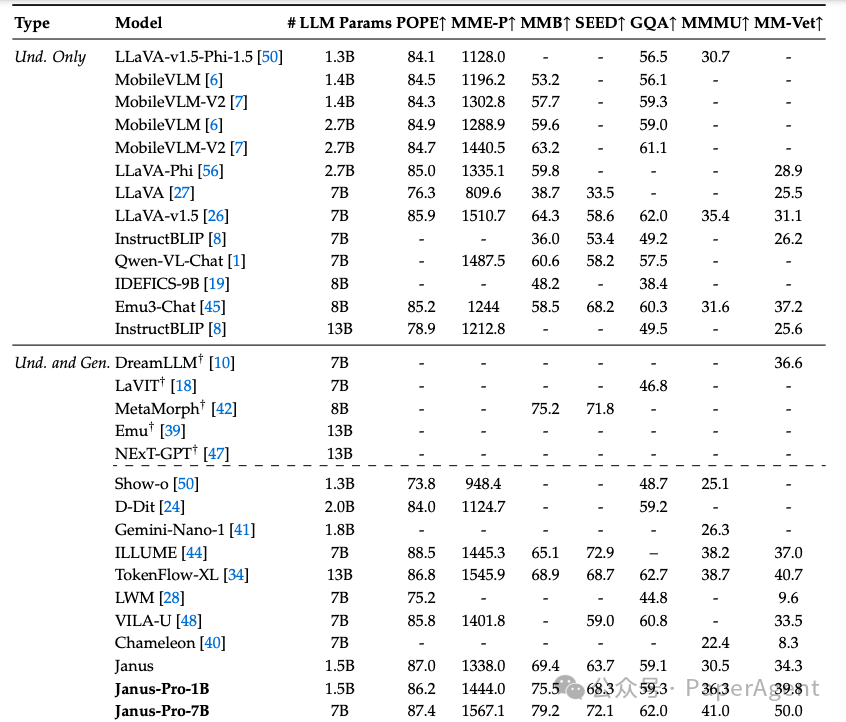
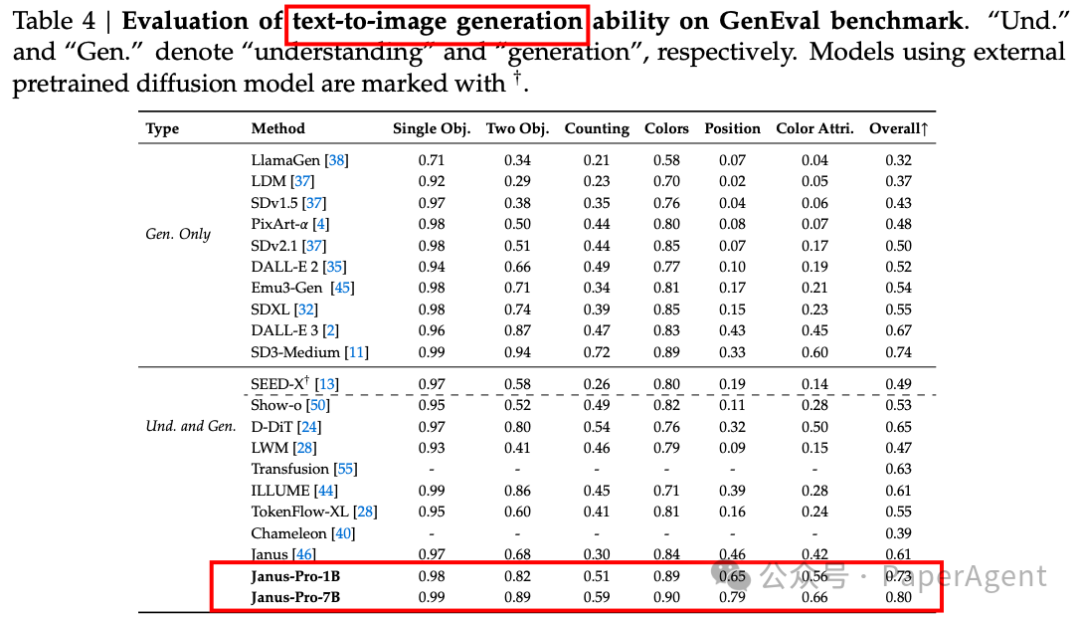
与多模态理解基准测试中的最新技术进行比较。“Und.”和“Gen.”分别表示“理解”和“生成”。使用外部预训练扩散模型的模型用†标记。



Janus-Pro 是 Janus 的高级版本,主要在三个方面进行了改进:优化的训练策略、扩展的训练数据和更大的模型规模。这些改进使得 Janus-Pro 在多模态理解和文本到图像指令遵循能力方面取得了显著进步,同时增强了文本到图像生成的稳定性。
架构
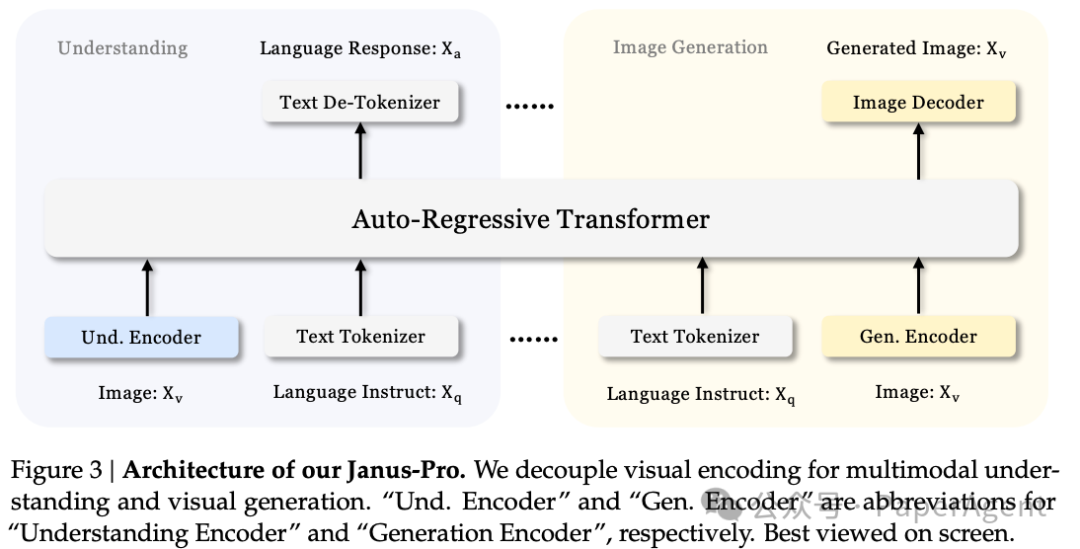
Janus-Pro 的架构与 Janus 相同,核心设计原则是解耦多模态理解和生成的视觉编码。使用独立的编码方法将原始输入转换为特征,然后由统一的自回归transformer处理。对于多模态理解,使用 SigLIP-L 编码器从图像中提取高维语义特征;对于视觉生成任务,使用 VQ tokenizer 将图像转换为离散 ID。这些特征序列被拼接后输入到 LLM 中进行处理。
优化的训练策略
Janus-Pro 对 Janus 的三阶段训练过程进行了优化:
-
第一阶段:增加训练步骤,充分训练 ImageNet 数据集,即使 LLM 参数固定,模型也能有效建模像素依赖并生成合理图像。
-
第二阶段:放弃 ImageNet 数据,直接使用正常的文本到图像数据训练模型生成图像,提高训练效率和整体性能。
-
第三阶段:调整数据比例,减少文本到图像数据的比例,以维持强大的视觉生成能力,同时提高多模态理解性能。
数据扩展
-
多模态理解:增加了约 9000 万样本,包括图像字幕数据集和表格、图表、文档理解数据。
-
视觉生成:增加了约 7200 万合成美学数据样本,使真实数据与合成数据的比例达到 1:1,提高了模型的收敛速度和输出的美学质量。
模型扩展
Janus-Pro 将模型规模从 1.5B 扩展到 7B,使用更大规模的 LLM 时,多模态理解和视觉生成的损失收敛速度显著提高,验证了该方法的强可扩展性。
https://hf-mirror.com/deepseek-ai/Janus-Pro-7Bhttps://hf-mirror.com/deepseek-ai/Janus-Pro-1Bhttps://github.com/deepseek-ai/Janus
(文:PaperAgent)