

本文从DeepSeek的独特优势出发,全面分享了DeepSeek的使用方法,包括:扔掉提示词模板的正确方式、让其 “说人话” 的方法、深度思考技能、强大文风转换器运用,以及使用禁区。
《DeepSeek使用攻略》如下:
注:本文所有技巧均来自真实案例,所有提示词都经过反复验证。
一、最重要的秘密:扔掉你的提示词模板
如果你还在用各种”专业提示词”和”模板”,那就是走错了方向。
DeepSeek根本不吃这一套。
为什么?
因为它的核心是推理型大模型,不是指令型大模型。
这就像两个实习生:
-
一个小书呆子,需要你事无巨细地安排任务步骤。(指令型) -
一个小机灵鬼,只要你说明目的,他就能自己思考怎么做。(推理型)
让我用一个真实案例来说明,
我们社群一位运营同学的实测,进行新能源行业分析,用于准备与比亚迪供应商谈判。
传统方式:
请你扮演一位新能源行业分析师,按照以下步骤分析:
1. 市场规模
2. 竞争格局
3. 技术路线
4. 未来趋势
要求:每部分800字,引用权威数据...
结果:得到一份干巴巴的报告,一眼AI。

正确方式:
我下周要和比亚迪的供应商谈判,但对动力电池一窍不通。帮我用最通俗的语言说明:
1. 他们的技术优势在哪
2. 可能要价多少
3. 有什么谈判时能用的专业术语
重点是让我听得懂,能装得像内行
结果:DeepSeek直接给出接地气的分析,还附带谈判话术。

这就是最大的区别:
DeepSeek不需要你写”专业提示词”,
它需要的是真实场景和具体需求。
送您一个通用公式:
我要xx,要给xx用,希望达到xx效果,但担心xx问题…
就像你跟一个聪明的下属说话:
-
不要说”请按照STAR法则写周报”
-
而要说:
我要写周报,老板周一要看,希望重点放在xxx上,重点是让咱们部门在老板面前能达到装逼效果,力压隔壁研发部,但担心研发质疑我们产品文档写得不够详细……”
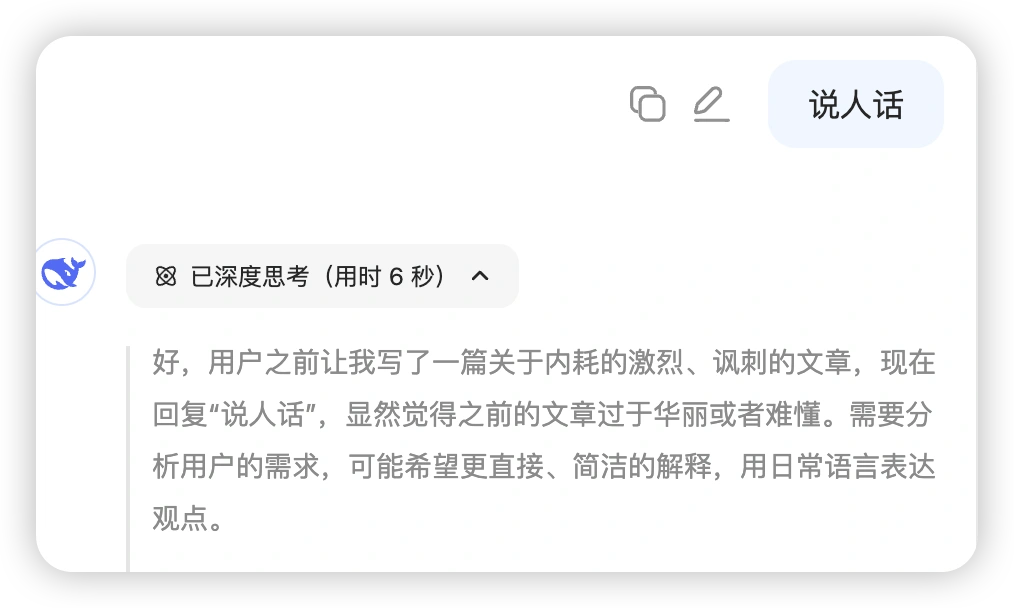
二、最被低估的功能:让它”说人话”
很多人抱怨DeepSeek的回复太抽象,像是在读天书。

但你可能不知道,只要一个简单的提示词,就能彻底改变这个问题。
这个神奇的提示词是:
说人话。
没错,就这三个字。
我的学员第一次试时还不信,结果…
原始回答:

加上”说人话”后的回答:

瞬间就接地气了,对吧?
因为deepseek对“说人话”这个词语很敏感。
当然,有时候这三个字不够用,还可以用这个详尽版提示词,直接复制过去即可:
【请用以下规范输出:1.语言平实直述,避免抽象隐喻;2.使用日常场景化案例辅助说明;3.优先选择具体名词替代抽象概念;4.保持段落简明(不超过5行);5.技术表述需附通俗解释;6.禁用文学化修辞;7.重点信息前置;8.复杂内容分点说明;9.保持口语化但不过度简化专业内容;10.确保信息准确前提下优先选择大众认知词汇】
三、最强大的技能:深度思考
这是我不得不说的事:
一个免费的国产AI,正在让月付200美金的GPT-o1坐不住了。
为什么?
因为DeepSeek的思维方式,比GPT-o1更智慧。
让我用一个真实案例来对比:
GPT-o1的回答:

DeepSeek的回答:

这就是最大的区别:
-
GPT-o1线性罗列,像个高级文档工具 -
DeepSeek深度思考,像个思考伙伴
免费的DeepSeek,直接让整个硅谷AI公司的牛马连夜加班,
幸亏他们不用过春节。
但最近,我发现一个现象:
由于用户暴增,DeepSeek明显调整了响应策略:
-
思考时间从20秒降到5秒 -
回答深度明显下降 -
反思能力受限

这是可以理解的临时措施,毕竟算力就是烧钱。
但对于我们用户来说,如何继续激发它的深度思考能力?
我整理了三个核心提示词,为了装逼,称为深度思考三件套:
请在你的思考分析过程中同时进行批判性思考至少10轮,务必详尽 请在你的思考分析过程中同时从反面考虑你的回答至少10轮,务必详尽 请在你的思考分析过程中同时对你的回答进行复盘至少10轮,务必详尽
如此一来,深度思考将从5秒恢复为20秒左右。
斜体的部分,可以自由替换成你所擅长的形式,也可以组合叠加,
但核心是反思。

四、最强大的文风转换器
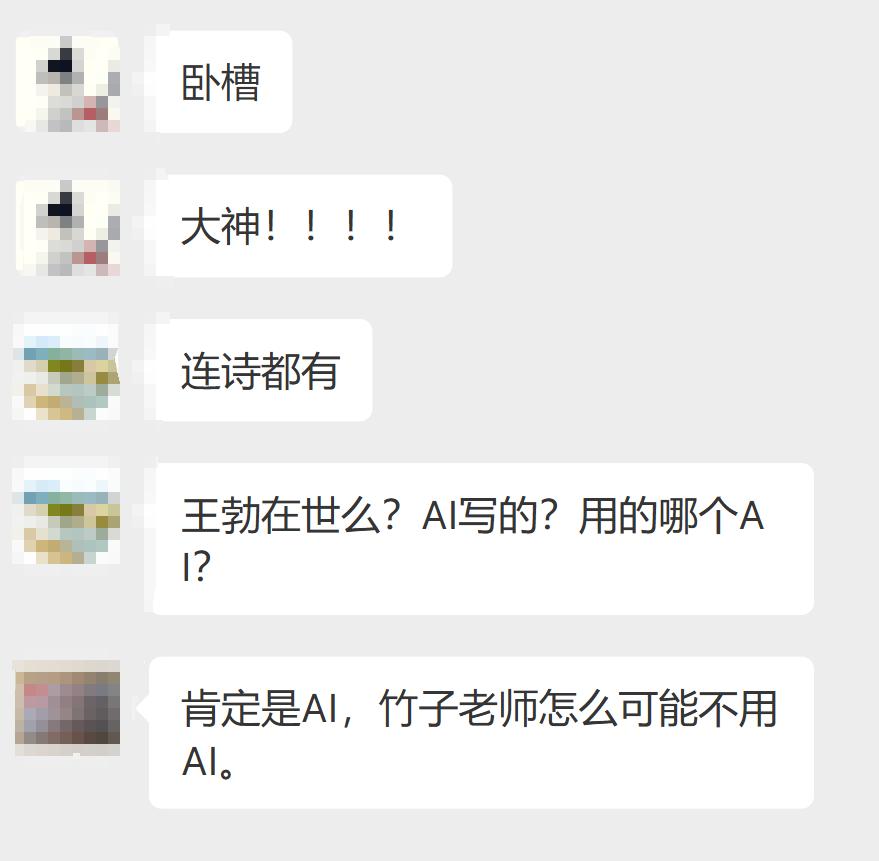
昨天,我用DeepSeek,写了一篇汉赋。
赞扬一下王星有情有义、智勇双全的女友。王星就是前阵子被卖到缅北的演员。

这用典,这骈文,真的没谁了。
发在群里后,直接炸出了三个语文老师…
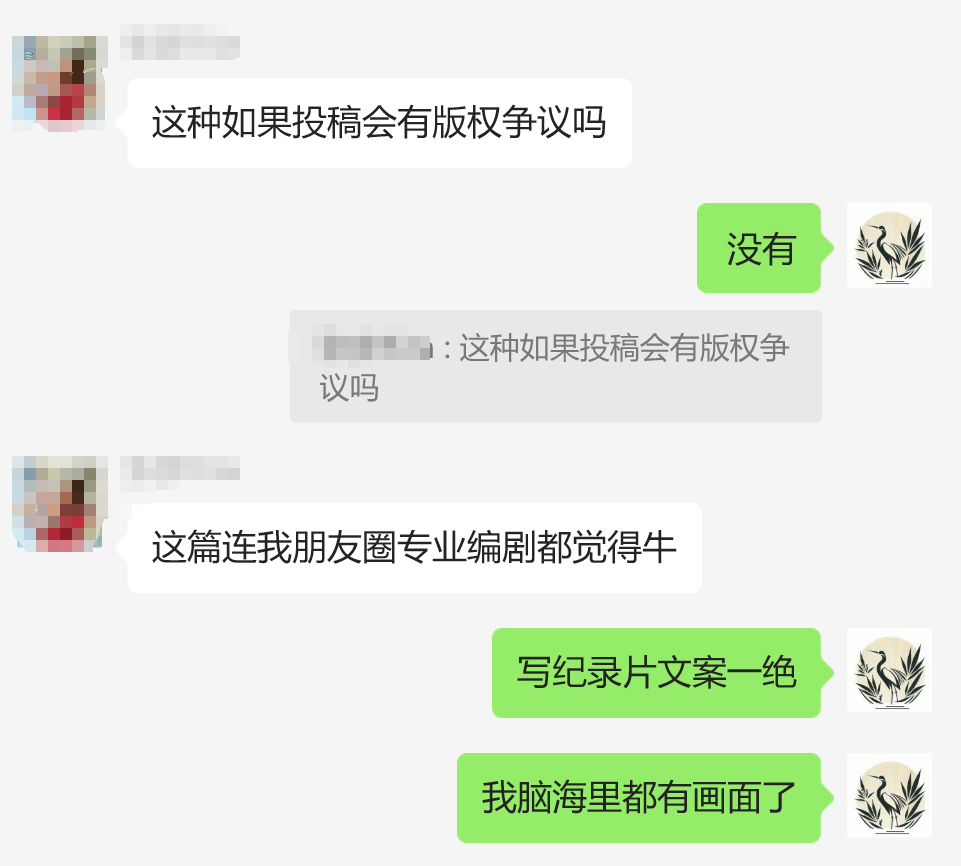
还有的朋友,写出的文字连专业编剧都说老到。

事实上,这正是DeepSeek的第四个秘密武器:文风转换器
提示词很简单,哪怕口述就行:
模仿xxx的文风,撰写关于xxxxx的一篇xx文体。
但要注意两点局限:
一方面,它更适合模仿经典作家,因为训练数据充足,风格特征明显。
另一方面,不要期待100%还原,80%相似度已经很厉害,重点是能抓住神韵。
我觉得deepseek肯定是训练了大量的文学语料,尤其是中国古典文学。
比如鲁迅、莫言,都是惟妙惟肖。

记住那个万能公式:
我要xx,要给xx用,希望达到xx效果,但担心xx问题…
例如:
我要写一篇关于赞颂王星女友机智勇敢用心的赋,用来小红书上面炫技,希望重点放在模仿王勃的篇文上,重点是让我本人的文采装逼,在小红书获得一个亿的赞,但担心别人看不懂太晦涩了……”
类似的风格迁移,也可以放在当代作家上,比如我们模仿刘润老师的跨年演讲:
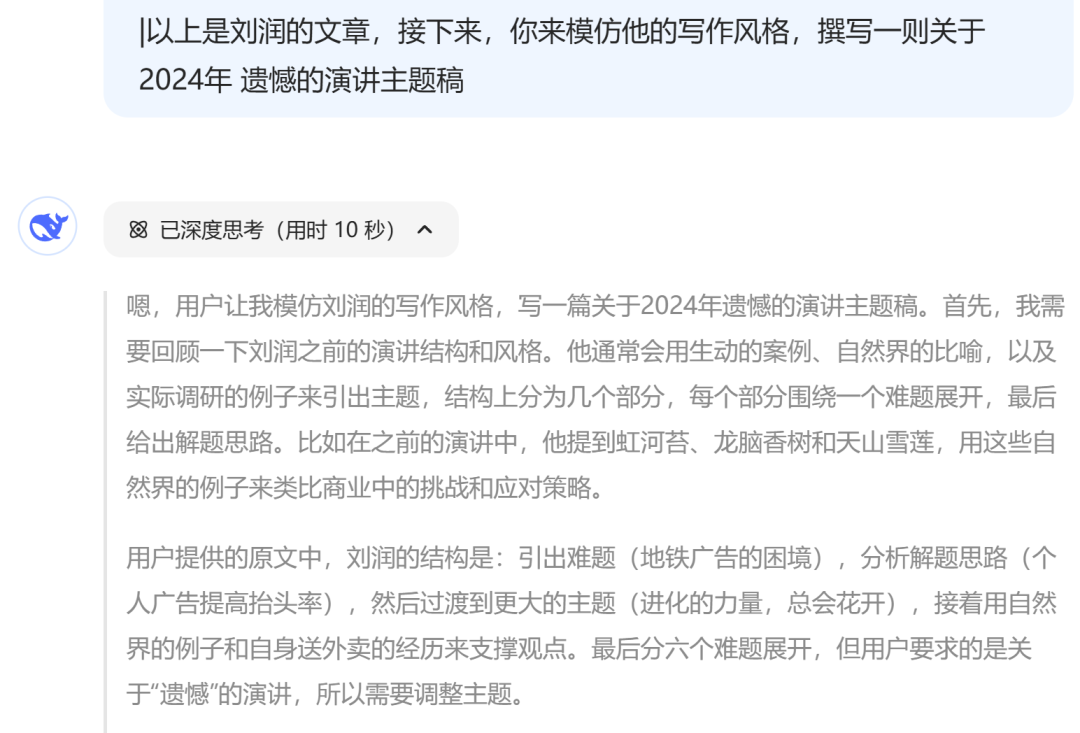
注意要先提供内容原文(尽量详尽,一般不少于8000字),然后直接要求其模仿即可。

当然,为了更好的效果,最好用上万能公式。
五、使用禁区:什么情况不要用它
说了这么多优点,也必须说说它的局限性。
以下场景不建议使用DeepSeek:
1. 长文本写作
超过4000字的文章容易出现逻辑断裂,建议用Claude200k。
因为deepseek默认是64k,长文不够用。

2. 敏感内容
毕竟是国产AI,内置审核尺度丧心病狂。

很多时候你不知道哪句话就触发审核了。
这种情况怎么解决呢?
因为deepseek是后置审核,所以有以下三种方案:
3.个人风格写作
这个就不赘述了,这是个推理模型,适合解决问题、模仿。
但很难通过精确控制来确保你想要的风格写作效果。
这其实不算deepseek的缺点,只能算特性。
具体的,我下一篇再来论述吧。
七、它将如何改变我们的AI时代?
经过几天的密集测试,我越来越确信:
DeepSeek代表了AI的未来方向 —— 更懂人话,更会思考。
你不需要学习它的语言,它在学习理解你的语言。
这意味着什么?
AI的使用门槛正在快速降低。
未来,我们不需要背诵提示词模板、学习特定的指令,研究各种参数。
只需要,说清楚你要什么,告诉它具体场景,说人话。
因为DeepSeek干掉了23年以来AI最反人类的设定
——让人类学习机器语言(提示词)。

这就像手机进化史的关键转折点:
-
诺基亚时代:看说明书,学组合键,刷机 -
iPhone时代:三岁小孩上手都会玩
我的投资圈朋友说得更直接:
2024年还教人写提示词的大V,都是在收智商税。
总之,还学个屁的提示词!
所以,这也是为什么我要坚持在过年前发布这篇文章。
Deepseek就是代表了新一代AI的使用范式,辞旧迎新!
声明,deepseek一分钱都没给我,但我就是要吹爆。
第八章:国产AI的歼20时刻
我们等这一天太久了。
当我在2023年3月15日,第一次用上GPT-4时,手在发抖。
一方面因为它的强大。
另一方面,也是因为我知道:
这个级别的AI,我们可能要追十年。
直到deepseek发布了R1,我依旧用怀疑的心态试一试,根本没报任何希望,
但看到它的深度思考,给到我的完全不逊于,甚至部分超越了御三家(GPT、claude、gemini)的回答。
我的手再次发抖了。
我知道,时代变了。
DeepSeek让我看到:
-
它懂”说人话”背后的人情世故 -
它理解”装逼效果”里的社交规则 -
它能用《滕王阁序》写缅北诈骗的荒诞
当硅谷还在教用户如何”驯化AI”时,DeepSeek正在做一件更伟大的事:
教会AI理解人的思维。
关键,DeepSeek还是开源的,这也是开源世界AI第一次光明正大地追上闭源世界。
就像歼20总设计师杨伟说的:
“我们不再追赶,我们在定义新的战场。”
这或许就是最好的新年礼物:
在AI的竞赛中,我们第一次与世界站在同一个黎明。

后记
写到这里,评论区肯定有人要喷我了,
觉得一个破deepseek,至于上升到什么家国情怀么。
我不管,我任性,我就是要上升。
科技没有国界,但老子有祖国,老子有自己人。
老子就想用自家东西,你管我?
今天,终于可以对着西方AI巨头的技术封锁说一句:
你们有的,我们会有。
你们没有的,我们正在创造。
PS
写完这篇文章时,窗外正好响起一声爆竹。
北京其实六环内禁止烟花爆竹燃放,谁知道哪个不知名勇士干的。
我突然想起OpenAI首席科学家Ilya Sutskever说过的话:
真正的涌现,往往发生在主流视野之外。
此刻,在杭州某个未眠的写字楼里,或许正有工程师在调试下一代模型。
而你我手中的DeepSeek,就是那颗已经点燃的爆竹。
听,AI革命的声音。

一起点赞三连↓
(文:Datawhale)