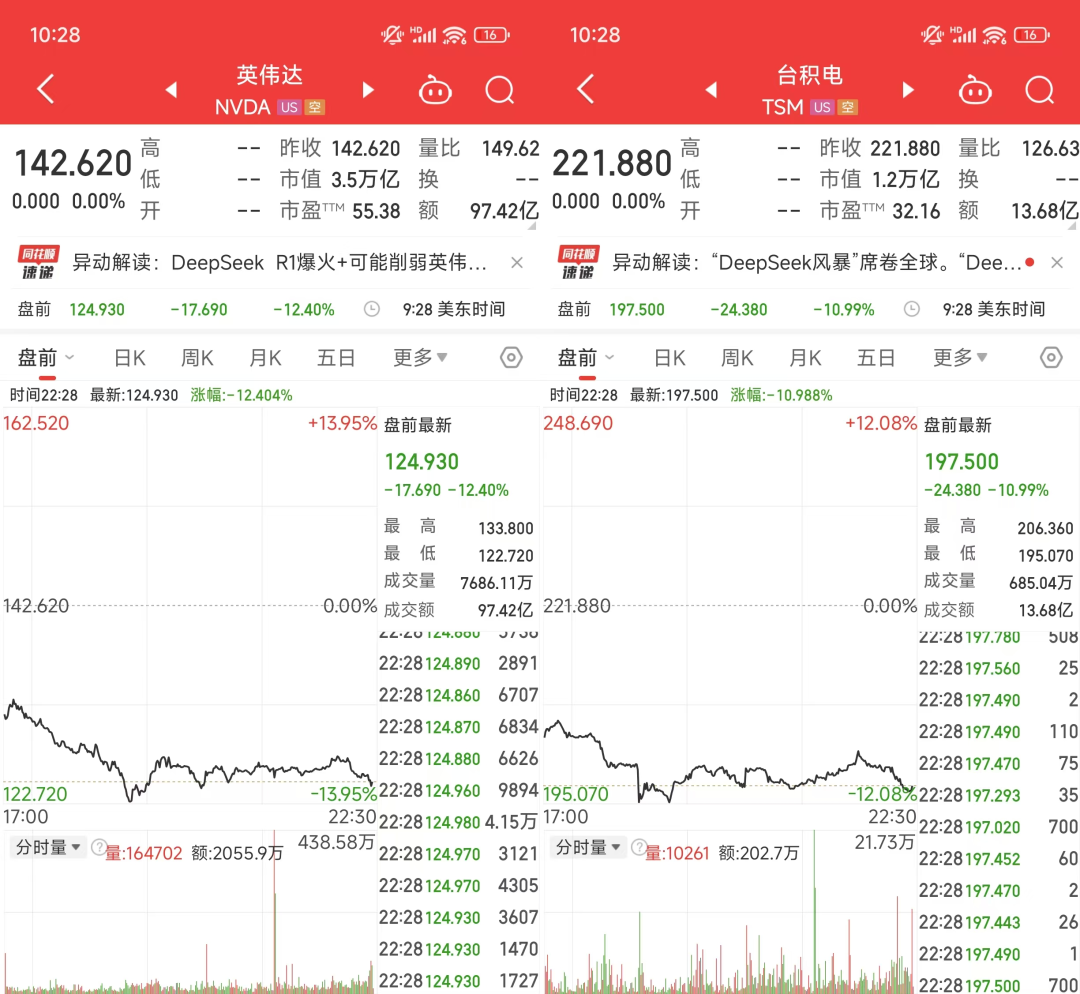
这两天,DeepSeek-R1火的飞起,在中日美三个Appstore榜上登顶。
昨晚,还直接干崩英伟达,盘前先死13个点,连带着台积电一起。
几乎一夜之间,所有人都在关注DeepSeek,甚至我在老家,完全没用过AI的七大姑八大姨,都在问我,DeepSeek是什么,怎么用。
还有一些人体验了一下后,拿着8.11和8.9谁大谁小的截图跟我说,这玩意也不行啊。
所以,今天除夕,龙年的最后一篇文章,献给DeepSeek,也献给我们自己。
我想用8个问题和答案,来让大家详细的了解,DeepSeek-R1这个模型,是什么,以及,提示词应该怎么写,到底怎么用。
DeepSeek,是一家在2023年7月17日成立的公司深度求索所开发的大模型名称。
2024年1月5日,他们正式发布DeepSeek LLM,这是深度求索第一个发布的AI大模型。
2024年5月7日,他们发布DeepSeek-V2,正式打响中国大模型价格战,当时新发布的 DeepSeek-V2 的API价格只有 GPT-4o 的 2.7%,随后一周时间,国产厂商全部跟进,字节、阿里、百度、腾讯全部降价。
2024年12月26日,DeepSeek-V3正式发布且直接开源,而且训练成本仅为557.6万美元,剔除掉Meta、OpenAI等大厂的前期探索成本,大概是别人的三分之一,并且整体模型评测能力媲美闭源模型,震惊海外,自此,东方的神秘力量彻底坐实。
2025年1月20日,全新的推理模型DeepSeek-R1发布,同样发布并开源,效果媲美OpenAI o1,同时API价格仅为OpenAI o1的3.7%,再一次震惊海外,让Meta连夜成立四个研究小组,让全球算力暴跌,英伟达的神话都岌岌可危。
就是这么一家公司,而深度求索的背后,是著名量化私募幻方基金,而基金的盈利模式非常简单,跟管理规模绑定,固定收取管理规模的管理费和收益部分的提成资金,无论基金涨跌都能赚钱,真正的旱涝保收的行业。
所以,幻方不缺钱,当年赚了钱,在英伟达还没向中国禁售的时候,幻方直接能掏钱搭一个万卡A100集群。
这也让深度求索,让DeepSeek,不以盈利为导向,目标,就是AI的星辰大海。
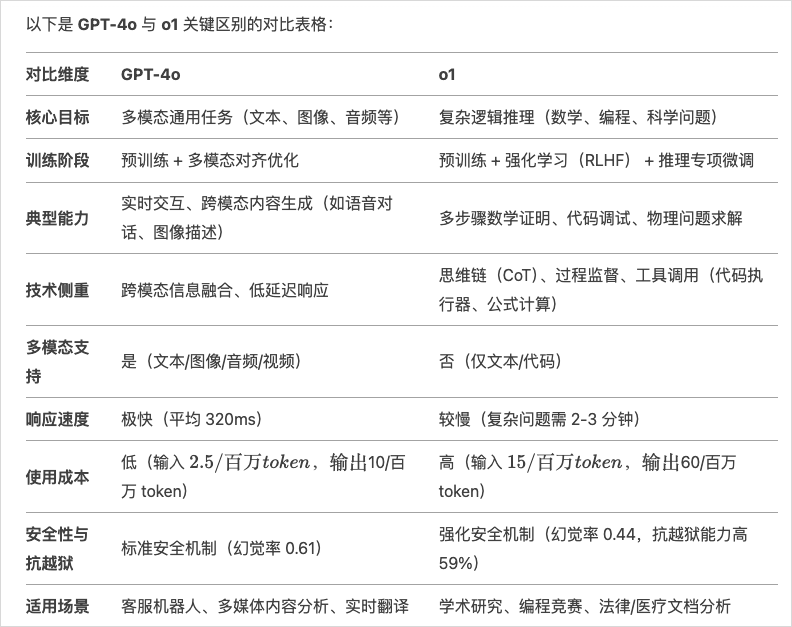
很多人拿DeepSeek-R1和GPT4o比,其实是不对的。
首先,GPT4o是个多模态通用模型,可以理解图片、语音、视频,也可以输出语音。多模态往后做,更像Gemini 2,是一个多模态大一统模型,可以理解一切模态,也可以输出一切模态。
而DeepSeek-R1是一个深度推理模型,对标OpenAI的应该是OpenAI o1,而不是GPT4o。
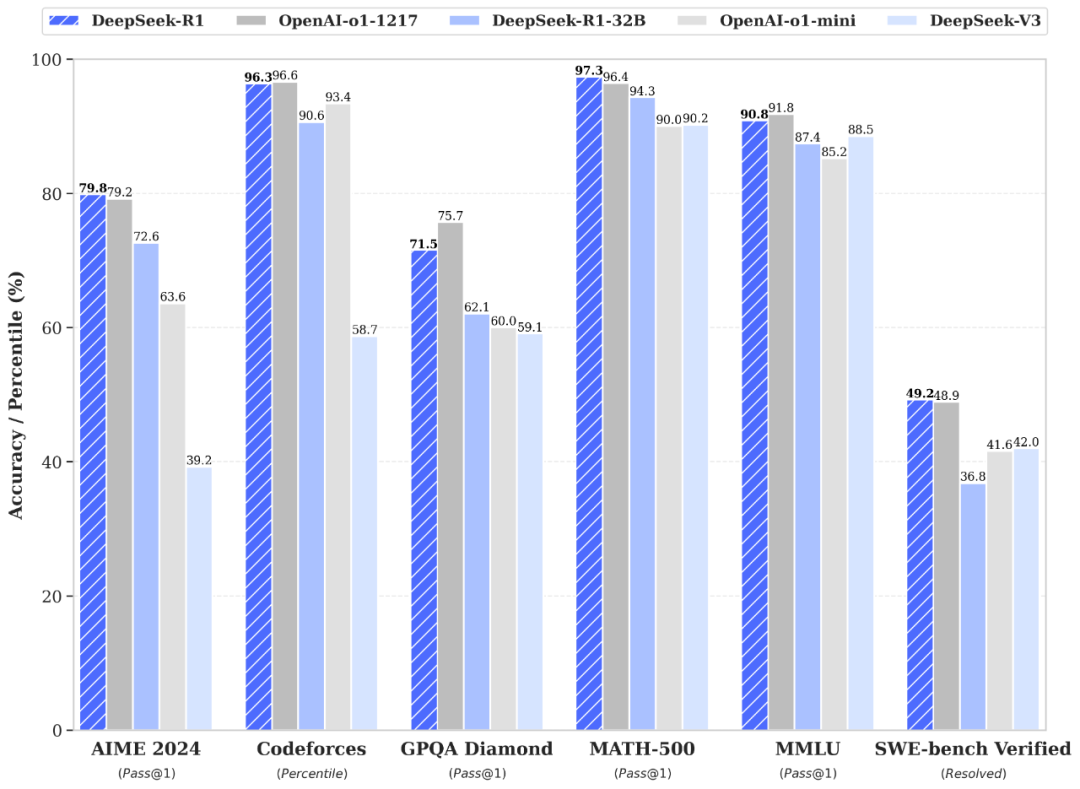
我也让DeepSeek列个了4o和o1的对比表格,大家应该也能一目了然。
而R1,可以直接类比o1,两者在跑分上,几乎相同。
HuggingFace 链接:https://huggingface.co/deepseek-ai
论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
DeepSeek-R1除了面向开发者的开源模型和API,也有面向普通用户的C端版本。
网页版:https://chat.deepseek.com/
当你勾上深度思考功能,此时就是使用R1模型,当你不勾的时候,使用的是类GPT4o的v3模型。
当然他们也有APP版本,你直接在应用商店搜索DeepSeek就好。
跟网页端交互基本一致。目前免费,就是用户增速过快,所以偶尔会有崩溃断网连不上问题,你可以在这个地方,来看DeepSeek的服务器状态。
https://status.deepseek.com/
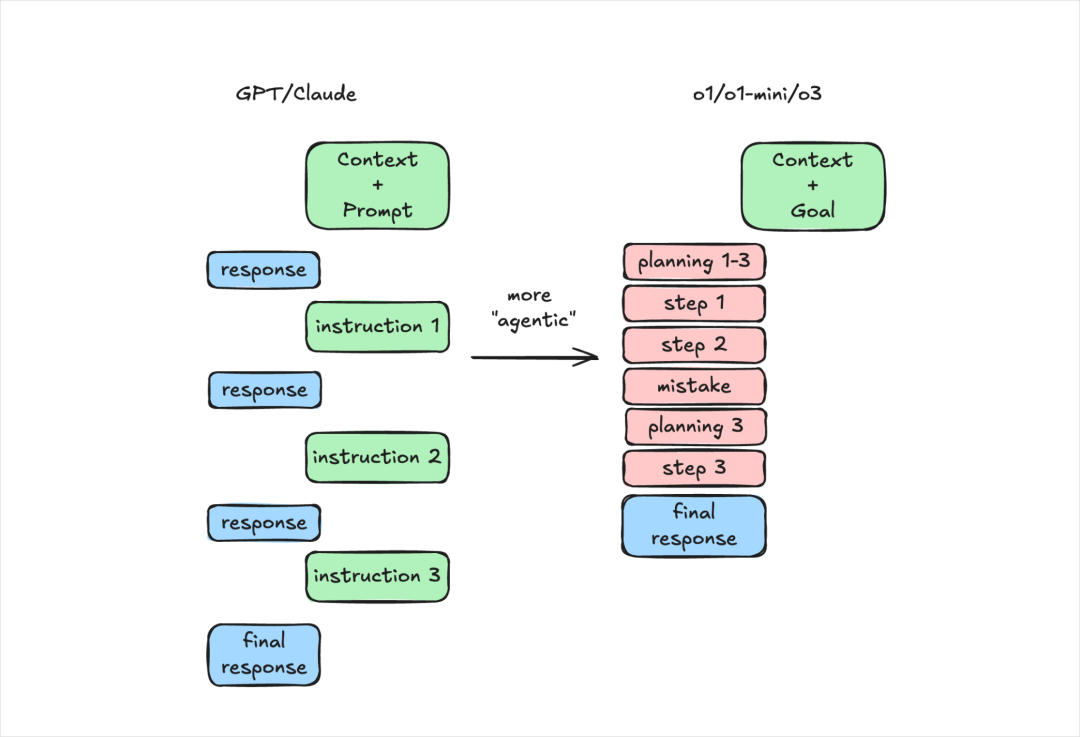
首先,我想明确一点的是,DeepSeek-R1是推理模型,不是通用模型。
在几个月前OpenAI o1刚刚发布时,我用通用模型的方式跟o1对话,写了一堆的结构化提示词,得到了极差的效果,那时候我一度觉得这玩意是个垃圾。
而后面,我才发现,其实是我自己的思维惯性,这玩意跟4o不一样,这不是一个很傻的聊天模型。
今年1月也有一篇海外的文章很火,叫《o1 isn’t a chat model (and that’s the point)》。
所以,有一个点一定要注意,明确你的目标,而不是给模型任务。
例如我们以前在写prompt的时候,总是会写你是一个XXX,现在我的任务是XXX,你要按照1、2、3步来给我执行balabala。
把你的一切,交给AI,让它去进行自我推理,效果会更好。AI会自动填上那些你没说出口的话,会给你想出可能更好的解决方案。
有一个不得不承认的事实是,我是一个很普通的普通人,而像我一样的很多普通人们,现在大概率是不如AI博学和聪明的。
所以,不如说出你的目标,把他当作一个很牛逼的员工,让他,放手去做。
所以请抛弃掉一起过往所学习的结构化框架,如果真的需要有一个万能Prompt模板,那就是:
背景信息给的越多越能让R1理解你的需求帮助你更好的完成任务。
所以,千言万语汇聚成一句话就是:用人话清晰的表达出你的需求,这就够了。
很多人在用“说人话”这三个字,来表达推理模型和通用模型不一样,这其实有点奇怪。
不过从实用角度来说,这确实是一个能让普通人看懂AI输出专业内容的小技巧。
不过这并不是一个推理模型才有的技巧,因为一直就存在,本质上就是对方不知道你是谁,不知道你的理解能力和你的学识能力是什么水平。
所以我也想分享一个我自己这两年跟AI对话时用的最多的一个小技巧,也是我自己最常用的“人话”prompt:
当你在跟AI对话时,把这句话往前一摆,自降身位,你就会发现,一切都通了,一切都能看的懂了。
比如我想让R1给我解释一下什么叫大模型中的RL用法。
我相信你看到一定脑壳疼。你就是不懂才需要让它给你解释,结果解释了个这。
反正我是一下子能看了,舒服了多了,可能我就真的是个小学生的水平。。。
当然如果你想稍微进阶一点,就可以说,我是一个初中生,或者,我是一个高中生,一点一点的可控升级。
R1除了能非常好的做常规推理模型都能做的数学题、代码等等,这次有一个非常非常特别的点是:
过往,大家都说,在写作能力上几乎所有的大模型都是众生平等的一坨屎,唯有Claude超出了一坨之外,独立于三界之上。
而这一次,DeepSeek-R1在中文写作和文笔上,已经是独一档的领先了。
比如我非常非常喜欢知乎上一个大V叫大师兄朱炫的文笔。
我甚至都不需要跟DeepSeek-R1说朱炫的文笔是什么样的,直接就说一句话:
以知乎大V朱炫的文风,来锐评一下爱情的求而不得,告诉大家,总会有人在等你。
虽然达不到朱炫那百分百的功力,达不到他那种多智而近妖的文笔,但是已经非常非常强了。
毕竟,只需要一句话而已。
“以李煜的诗词风格,来写一首我回老家没有朋友玩的感觉”
《虞美人·归乡感怀》
故园旧巷行人少,空有榆钱老。
秋千院落锁苍苔,偶见邻家黄犬过阶来。
重游往日嬉春处,蛛网斜阳驻。
笑谈声远柳风凉,唯剩一庭明月照空廊。
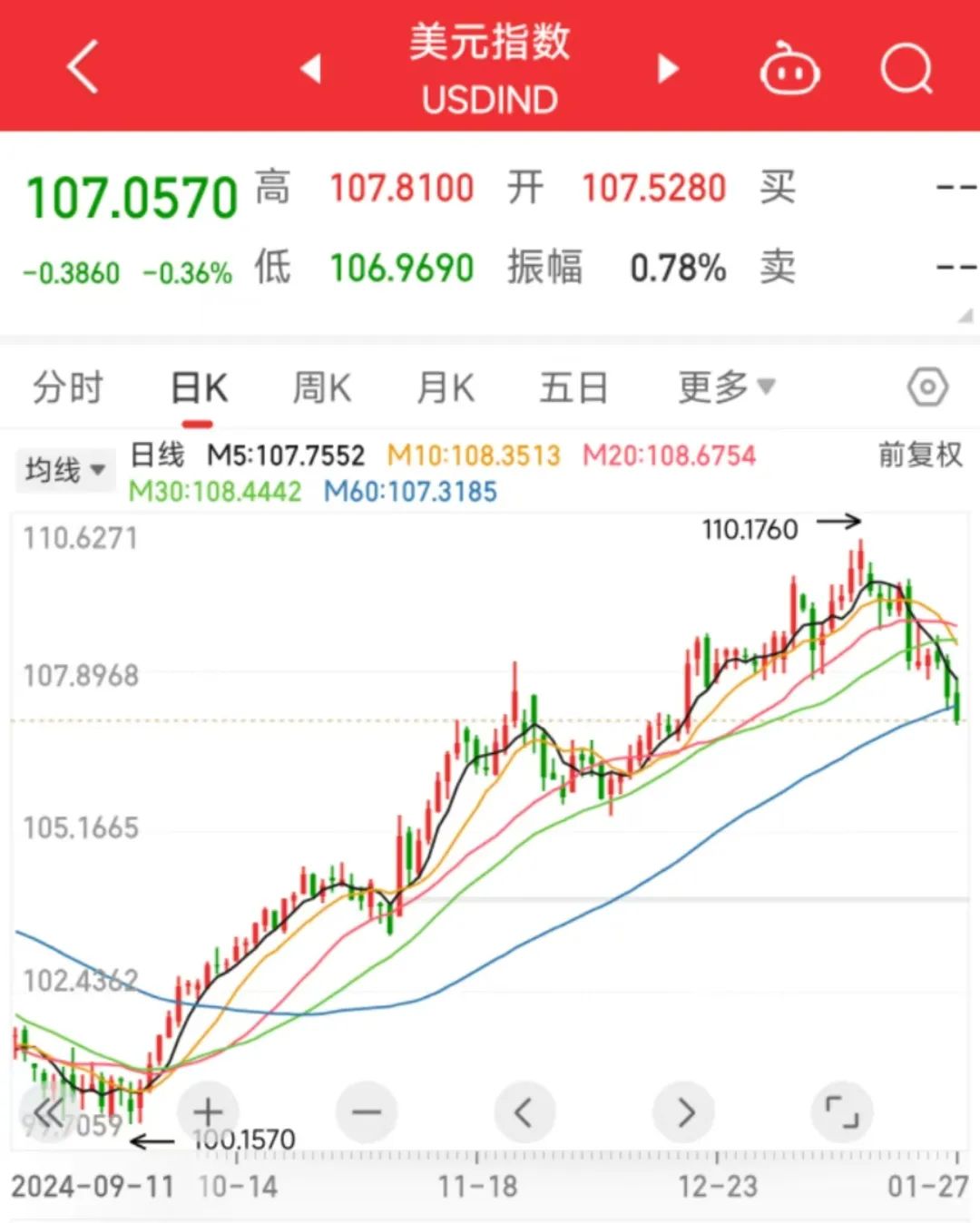
这给我带来了非常的多的困扰,要知道,OpenAI o1的知识库还是24年,很多东西都不知道,更别提一些所谓的实事了,你想用它来梳理分析一些最近的数据,比如美元指数、比如最近的财报等等,它完全不知道,甚至还传不了PDF,就非常的der比。
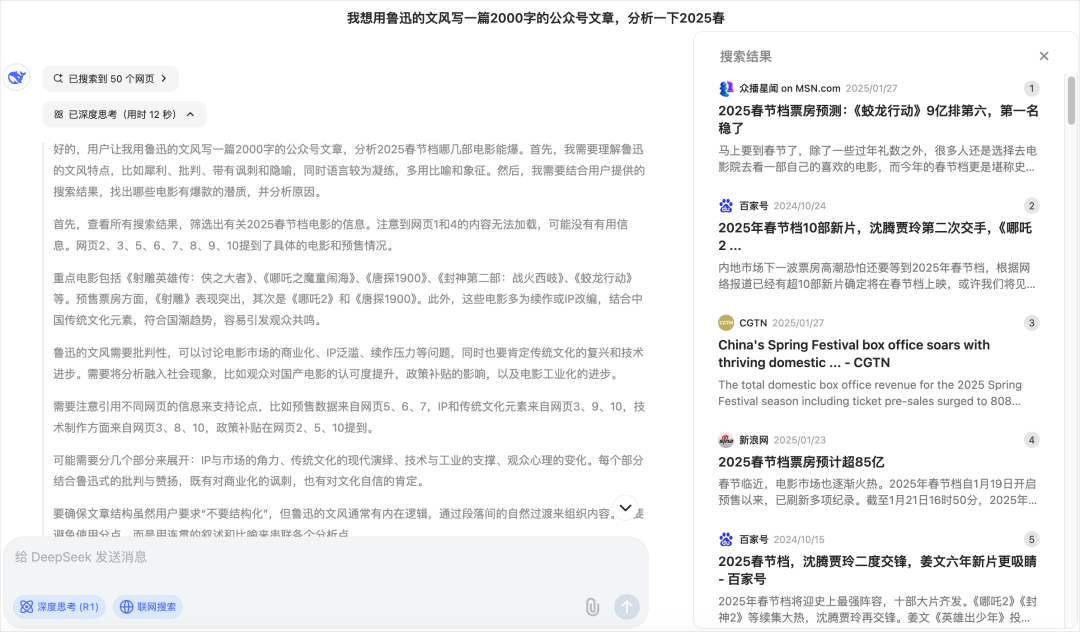
我们来试试这句话:我想用鲁迅的文风写一篇2000字的公众号文章,分析一下2025春节档哪几部电影能爆,不要结构化。
DeepSeek去网上搜了50个网页,然后思考了半天。
虽然整体测下来,在联网资料的RAG层面还有一些问题和不尽如意,但是已经非常强了,至少,能听懂我的话,知道我想要的是鲁迅风格。
昨天,A股算力和美股算力都崩了,大家几乎都把原因归结到DeepSeek很便宜,所以未来不需要那么多算力,算力神话崩塌了。
在第一次工业革命的时候,有一个经济学里面非常著名的悖论,是由威廉·斯坦利·杰文斯提出来的,叫做Jevons 悖论。
当时,英国的工业革命正在加速发展,蒸汽机的效率也在不断提高。人们普遍认为,蒸汽机会越来越节能,也越来越会减少煤炭消耗。
因为,更高效的蒸汽机降低了使用煤炭的成本,结果导致蒸汽机被更广泛应用,煤炭消耗总量反而大幅增加。
假设新技术让汽车的燃油效率提高了 50%(比如每加仑能跑 30 公里变成 45 公里)。照理来说,这应该减少燃油总消耗,但现实可能是:
由于油耗更低,开车的成本下降,人们更愿意开车,开车里程增加。
最终,油耗效率提高后,燃油消耗的总量可能不降反升。
跟现在算力逻辑是一摸一样,如果你要把DeepSeek对与算力的影响带入的话,那其实就会导致:
因为大模型需要的训练和推理算力成本下降,反而会推动AI应用和生态的繁荣,端侧、个人级别大模型逐渐成熟,算力的总需求反而越来越大。
而且美元指数都崩成什么样了,直接破了60日均线,纳斯达克和英伟达不崩才奇怪好吧。
只能说,DeepSeek有短期驱动效应,但是核心还是内身问题,DeepSeek踩中了这个节点,天时地利人和。
流浪地球、新能源车、黑神话悟空、六代机、TikTok、DeepSeek等等等等。
(文:开源星探)