


在当今数字化信息呈爆炸式增长的时代,如何高效地检索和利用信息成为了各个领域面临的关键挑战。随着人工智能技术的不断发展,检索增强生成(RAG)技术应运而生,为解决这一难题提供了新的思路和方法。中科院研发的 FlexRAG 作为一款创新的高性能多模态 RAG 框架,在众多同类技术中脱颖而出,引起了广泛的关注。
一、项目概述
FlexRAG 是由中科院推出的一款专门用于检索增强生成任务的框架,其核心目标是解决传统 RAG 系统在处理长上下文时遇到的计算成本高昂和生成质量欠佳的问题。在实际应用中,传统 RAG 系统常常因为需要处理大量的上下文信息而导致计算效率低下,同时生成的结果也难以满足用户的需求。FlexRAG 通过引入一系列创新技术,有效地克服了这些局限性。

它的核心组件包括压缩编码器和选择性压缩机制。压缩编码器能够将检索到的长上下文信息转化为紧凑的嵌入表示,大大减少了输入给下游模型的负担,从而显著提高了计算效率。而选择性压缩机制则通过评估信息的重要性,优先保留对生成最为关键的信息,并且可以根据具体任务需求动态调整保留的上下文信息,使得压缩过程更加灵活高效。此外,FlexRAG 还支持多模态 RAG,能够处理多种数据格式,如文本(CSV、JSONL 等)、图像、文档、网页等,为不同领域的应用提供了广泛的可能性。
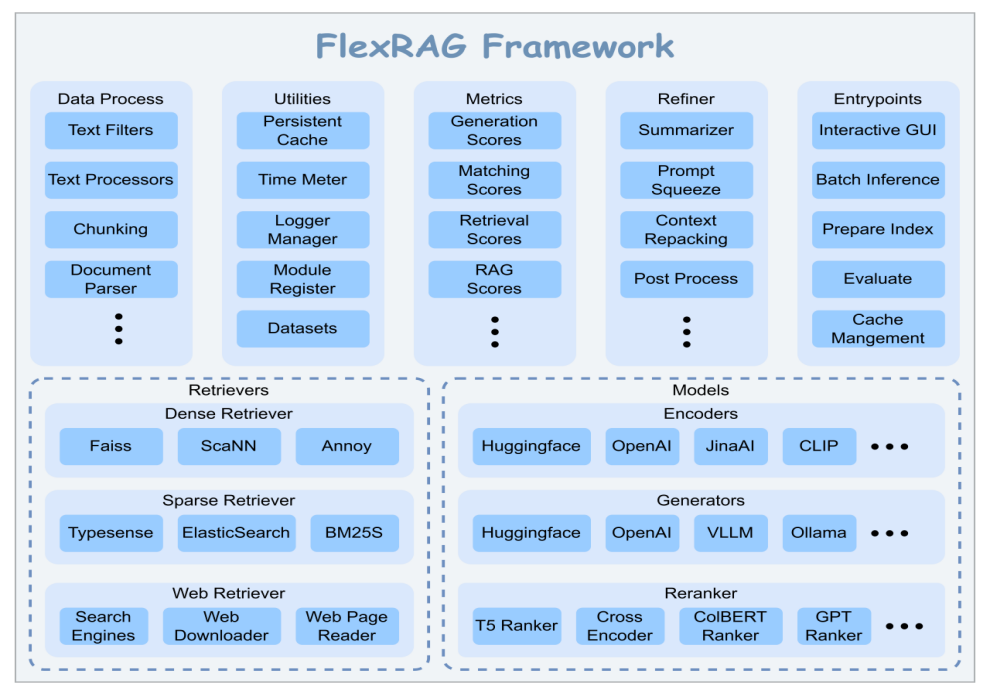
二、技术原理
1、压缩编码器
-
信息提取与数据压缩:压缩编码器是 FlexRAG 的关键技术之一,其主要作用是将长度不一的上下文信息转化为固定尺寸的嵌入。在这个过程中,它通过提取关键信息和特征,实现了对数据的有效压缩。例如,在处理一篇长篇文章时,它能够识别出文章中的核心主题、关键论点以及重要的事实依据等,将这些关键信息提取出来并转化为紧凑的嵌入表示,从而减少了不必要的信息冗余。
-
实现机制:FlexRAG 采用了特定的训练策略来训练压缩编码器,使其能够学习到哪些信息对于生成任务是最为重要的。在训练过程中,通过大量的样本数据和监督学习,压缩编码器逐渐掌握了如何筛选和提取关键信息的能力。例如,对于一个问答任务,它会学习到问题中的关键词以及与这些关键词相关的上下文信息的重要性,从而在压缩过程中能够准确地保留这些关键信息,为后续的生成任务提供有力支持。
2、选择性压缩机制
-
重要性评估与动态调整:该机制通过对不同上下文信息的重要性进行评估,能够优先保留那些对生成结果最为关键的信息。它采用了一系列的评估指标和算法,如基于语义理解的重要性评分、信息的相关性分析等,来判断信息的重要性。同时,它还可以根据具体的任务需求动态调整保留的上下文信息。例如,在一个需要详细解释的任务中,它会适当增加保留的信息数量和范围;而在一个只需要简要回答的任务中,它会更加严格地筛选和压缩信息,确保生成的结果简洁明了。
-
压缩比分配:为了在压缩效果和上下文信息保留之间达到平衡,FlexRAG 根据估计的重要性对上下文进行分组,并为每组分配不同的压缩比。对于重要性较高的信息组,采用较低的压缩比,以尽量保留更多的细节;而对于重要性较低的信息组,则采用较高的压缩比,以实现更高效的压缩。这种灵活的压缩比分配策略使得 FlexRAG 能够在不同的任务场景下都能取得较好的性能表现。
3、双阶段训练工作流
预训练与微调:FlexRAG 的训练过程分为预训练和微调两个阶段。在预训练阶段,模型在大规模数据集上进行训练,主要目的是建立起基本的语言理解和生成能力。通过学习大量的文本数据,模型能够掌握语言的语法、语义和语用规则,以及常见的知识和概念。在微调阶段,模型则在特定任务的数据集上进行训练,针对具体的应用场景和任务需求,对模型的参数进行优化,以提高模型在特定任务上的表现。例如,在一个医疗领域的问答任务中,通过在医疗相关的数据集上进行微调,模型能够更好地理解医疗术语、疾病症状和治疗方法等专业知识,从而给出更准确的回答。
三、主要功能
1、多模态 RAG 支持
FlexRAG 突破了传统 RAG 仅基于文本的限制,实现了对多模态数据的支持。这使得它能够在处理包含图像、文本、音频等多种数据类型的任务中发挥重要作用。
2、多数据类型支持
它能够无缝集成多种数据格式,包括文本(如 CSV、JSONL)、图像、文档、网页等。这为用户提供了极大的灵活性,使其能够轻松应对各种数据源。无论是结构化的数据库数据,还是非结构化的网页内容或文档资料,FlexRAG 都能够有效地进行处理和利用。
3、统一的配置管理
基于 python `dataclass` 和 hydra-core,FlexRAG 实现了统一的配置管理。这使得 RAG 流程的配置变得更加简单和便捷。用户可以通过简洁明了的配置文件,轻松地调整模型的各种参数和设置,如检索器类型、压缩比、生成模型的选择等。这种统一的配置管理方式不仅提高了开发效率,还降低了用户的使用门槛,使得即使是没有深厚技术背景的用户也能够快速上手和定制 FlexRAG 以满足自己的需求。
4、上下文压缩
通过压缩编码器,FlexRAG 能够将检索到的长上下文信息转化为紧凑的嵌入表示,有效地减少了计算负担。这使得模型能够更高效地处理大量数据,提高了系统的响应速度和性能。在处理大规模文本数据集或复杂的多模态数据时,这种上下文压缩功能尤为重要。
5、支持多种检索器类型
FlexRAG 支持多种类型的检索器,包括稀疏检索器、密集检索器、基于网络的检索器和多模态检索器。这种多样性使得它能够灵活地应用于不同的数据类型和场景。
6、提示微调
通过学习一个软提示(soft-prompt),FlexRAG 能够改善下游任务的性能,使模型更好地适应特定任务。在实际应用中,不同的任务具有不同的特点和要求,通过提示微调,FlexRAG 可以根据具体任务的特点对模型进行优化。
四、应用场景
1、开放域问答
在开放域问答场景中,FlexRAG 能够充分发挥其优势。当面对未知领域的复杂问题时,它可以通过检索相关知识库中的信息来生成准确且详细的答案。例如,用户询问“量子计算的原理和应用有哪些?”FlexRAG 会首先在其关联的知识库中搜索与量子计算相关的文章、论文、百科条目等信息,然后利用其强大的生成能力,对这些检索到的信息进行整合和分析,最终生成一个全面且易于理解的答案,帮助用户快速了解量子计算的相关知识。
2、对话系统
在多轮对话中,FlexRAG 能够根据历史对话内容检索相关信息,生成连贯且有深度的回应。比如在一个智能客服场景中,用户与客服机器人进行对话,询问关于某款产品的使用方法和常见问题。FlexRAG 会根据之前的对话记录,检索相关的产品手册、用户反馈等信息,为客服机器人提供更丰富的背景知识,使其能够生成更加准确和个性化的回答,提高用户的满意度和对话的效果。
3、文档摘要与生成
基于知识库中的信息,FlexRAG 可以更好地提炼和合成文档的关键信息,生成高质量的摘要。在学术研究领域,研究人员常常需要阅读大量的文献资料,FlexRAG 可以帮助他们快速生成文献的摘要,节省时间和精力。它能够准确地识别文献中的核心观点、研究方法和重要结论,将这些信息整合在一起,生成简洁明了的摘要,为研究人员提供有价值的参考。
4、知识密集型任务
在需要大量背景知识的任务中,如自然语言推理、文本分类等,FlexRAG 可以通过检索外部知识来提高模型的准确性和可靠性。例如,在一个自然语言推理任务中,判断“所有的鸟都会飞”这句话的真假,FlexRAG 可以检索相关的生物学知识,了解到鸵鸟、企鹅等鸟类是不会飞的,从而得出正确的答案。通过引入外部知识,FlexRAG 能够弥补模型自身知识的局限性,提高在这些复杂任务上的表现。
5、多模态内容处理
由于 FlexRAG 支持多种数据类型的集成,包括文本、图像、文档等,因此它在多模态内容的生成和处理方面具有很大的优势。在一个数字艺术创作平台上,它可以结合图像和文本信息,为艺术家提供创意灵感和创作建议。例如,根据用户提供的一幅风景画图像和一些描述性的文字,FlexRAG 可以生成关于这幅画的创作背景、艺术风格、色彩运用等方面的分析和建议,帮助艺术家更好地理解和创作作品。
五、快速使用
1、安装
从 pip 安装:可以通过在命令行中执行 `pip install flexrag` 来快速安装 FlexRAG。这是一种简单便捷的安装方式,适合大多数用户。在安装过程中,确保网络连接稳定,以便顺利下载和安装所需的依赖包。
pip install flexrag从源码安装:如果需要对 FlexRAG 进行定制开发或深入研究,也可以选择从源码安装。
pip install pybind11git clone https://github.com/ictnlp/flexrag.gitcd flexragpip install ./
2、准备检索器
-
下载语料库:在运行 RAG 应用之前,需要下载相应的语料库。以使用 DPR 提供的 wikipedia 语料库为例,
# Download the corpuswget https://dl.fbaipublicfiles.com/dpr/wikipedia_split/psgs_w100.tsv.gz# Unzip the corpusgzip -d psgs_w100.tsv.gz
在下载过程中,注意选择合适的存储路径,并确保有足够的磁盘空间。
-
准备索引:下载语料库后,需要为检索器构建索引。如果使用密集检索器,可以通过运行以下命令构建索引:
CORPUS_PATH='[psgs_w100.tsv]'CORPUS_FIELDS='[title,text]'DB_PATH=<path_to_database>python -m flexrag.entrypoints.prepare_index \corpus_path=$CORPUS_PATH \saving_fields=$CORPUS_FIELDS \retriever_type=dense \dense_config.database_path=$DB_PATH \dense_config.encode_fields=[text] \dense_config.passage_encoder_config.encoder_type=hf \dense_config.passage_encoder_config.hf_config.model_path='facebook/contriever' \dense_config.passage_encoder_config.hf_config.device_id=[0,1,2,3] \dense_config.index_type=faiss \dense_config.faiss_config.batch_size=4096 \dense_config.faiss_config.log_interval=100000 \dense_config.batch_size=4096 \dense_config.log_interval=100000 \reinit=True
如果使用稀疏检索器,则需要运行相应的稀疏检索器构建索引的命令,具体命令可参考项目文档。在构建索引过程中,根据硬件资源和数据规模合理调整参数,如 `batch_size` 等,以提高索引构建的效率和质量。
3、运行 FlexRAG 助手
1)运行示例 RAG 应用(带 GUI)
当索引准备好后,可以运行 FlexRAG 提供的示例 RAG 应用。例如,通过以下命令运行一个模块化助手:
python -m flexrag.entrypoints.run_interactive \assistant_type=modular \modular_config.used_fields=[title,text] \modular_config.retriever_type=dense \modular_config.dense_config.top_k=5 \modular_config.dense_config.database_path=${DB_PATH} \modular_config.dense_config.query_encoder_config.encoder_type=hf \modular_config.dense_config.query_encoder_config.hf_config.model_path='facebook/contriever' \modular_config.dense_config.query_encoder_config.hf_config.device_id=[0] \modular_config.response_type=short \modular_config.generator_type=openai \modular_config.openai_config.model_name='gpt-4o-mini' \modular_config.openai_config.api_key=$OPENAI_KEY \modular_config.do_sample=False
在运行过程中,根据实际需求调整参数,如 `top_k`(检索结果数量)、`model_name`(生成模型名称)等。同时,确保提供正确的 `API_KEY` 等必要信息,以保证应用的正常运行。
2)运行知识密集型任务助手
可以通过以下命令在 Natural Questions(NQ)数据集上评估模块化助手(使用密集检索器):
OUTPUT_PATH=<path_to_output>DB_PATH=<path_to_database>OPENAI_KEY=<your_openai_key>python -m flexrag.entrypoints.run_assistant \data_path=flash_rag/nq/test.jsonl \output_path=${OUTPUT_PATH} \assistant_type=modular \modular_config.used_fields=[title,text] \modular_config.retriever_type=dense \modular_config.dense_config.top_k=10 \modular_config.dense_config.database_path=${DB_PATH} \modular_config.dense_config.query_encoder_config.encoder_type=hf \modular_config.dense_config.query_encoder_config.hf_config.model_path='facebook/contriever' \modular_config.dense_config.query_encoder_config.hf_config.device_id=[0] \modular_config.response_type=short \modular_config.generator_type=openai \modular_config.openai_config.model_name='gpt-4o-mini' \modular_config.openai_config.api_key=$OPENAI_KEY \modular_config.do_sample=False \eval_config.metrics_type=[retrieval_success_rate,generation_f1,generation_em] \eval_config.retrieval_success_rate_config.context_preprocess.processor_type=[simplify_answer] \eval_config.retrieval_success_rate_config.eval_field=text \eval_config.response_preprocess.processor_type=[simplify_answer] \log_interval=10
类似地,也可以使用稀疏检索器在该数据集上进行评估,只需调整相应的检索器类型和参数。在评估过程中,关注评估指标的结果,如 `retrieval_success_rate`(检索成功率)、`generation_f1`(生成结果的 F1 值)等,以了解助手在该任务上的性能表现。
3)构建自己的 RAG 助手
要构建自己的 RAG 助手,可以创建一个新的 Python 文件并导入必要的 FlexRAG 模块。以下是一个简单的示例:
from dataclasses import dataclassfrom flexrag.assistant import ASSISTANTS, AssistantBasefrom flexrag.models import OpenAIGenerator, OpenAIGeneratorConfigfrom flexrag.prompt import ChatPrompt, ChatTurnfrom flexrag.retriever import DenseRetriever, DenseRetrieverConfig@dataclassclass SimpleAssistantConfig(DenseRetrieverConfig, OpenAIGeneratorConfig):...@ASSISTANTS("simple", config_class=SimpleAssistantConfig)class SimpleAssistant(AssistantBase):def __init__(self, config: SimpleAssistantConfig):self.retriever =DenseRetriever(config)self.generator = OpenAIGenerator(config)returndef answer(self, question: str) -> str:prompt = ChatPrompt()context = self.retriever.search(question)[0]prompt_str = ""for ctx in context:prompt_str += f"Question: {question}\nContext: {ctx.data['text']}"prompt.update(ChatTurn(role="user", content=prompt_str))response = self.generator.chat([prompt])[0][0]prompt.update(ChatTurn(role="assistant", content=response))return response
在定义 `SimpleAssistant` 类并使用 `ASSISTANTS` 装饰器注册后,可以通过以下命令运行助手:
DB_PATH=<path_to_database>OPENAI_KEY=<your_openai_key>DATA_PATH=<path_to_data>MODULE_PATH=<path_to_simple_assistant_module>python -m flexrag.entrypoints.run_assistant \user_module=${MODULE_PATH} \data_path=${DATA_PATH} \assistant_type=simple \simple_config.model_name='gpt-4o-mini' \simple_config.api_key=${OPENAI_KEY} \simple_config.database_path=${DB_PATH} \simple_config.index_type=faiss \simple_config.query_encoder_config.encoder_type=hf \simple_config.query_encoder_config.hf_config.model_path='facebook/contriever' \simple_config.query_encoder_config.hf_config.device_id=[0] \eval_config.metrics_type=[retrieval_success_rate,generation_f1,generation_em] \eval_config.retrieval_success_rate_config.eval_field=text \eval_config.response_preprocess.processor_type=[simplify_answer] \log_interval=10
在构建过程中,根据具体的任务需求和数据特点,合理设计助手的配置和逻辑。同时,可以参考 `flexrag_examples` 仓库中的详细示例,获取更多的构建思路和方法。
4、运行自己的 RAG 应用
除了使用 FlexRAG 内置的入口点运行 RAG 助手外,还可以利用它构建自己的 RAG 应用。以下是一个简单的示例:
from flexrag.models import HFEncoderConfig, OpenAIGenerator, OpenAIGeneratorConfigfrom flexrag.prompt import ChatPrompt, ChatTurnfrom flexrag.retriever import DenseRetriever, DenseRetrieverConfigdef main():# 初始化检索器retriever_cfg = DenseRetrieverConfig(database_path="path_to_database", top_k=1)retriever_cfg.query_encoder_config.encoder_type = "hf"retriever_cfg.query_encoder_config.hf_config = HFEncoderConfig(model_path="facebook/contriever")retriever = DenseRetriever(retriever_cfg)# 初始化生成器generator = OpenAIGenerator(OpenAIGeneratorConfig(model_name="gpt-4o-mini", api_key="your_openai_key", do_sample=False))# 运行 RAG 应用prompt = ChatPrompt()while True:query = input("请输入您的查询(输入 `exit` 退出): ")if query == "exit":breakcontext = retriever.search(query)[0]prompt_str = ""for ctx in context:prompt_str += f"Question: {query}\nContext: {ctx.data['text']}"prompt.update(ChatTurn(role="user", content=prompt_str))response = generator.chat(prompt)prompt.update(ChatTurn(role="assistant", content=response))print(response)returnif __name__ == "__main__":main()
在构建自己的 RAG 应用时,需要根据实际需求仔细设计检索器和生成器的配置,以及应用的交互逻辑。可以参考 FlexRAG 的文档和示例代码,不断优化和完善应用的功能。
六、结语
FlexRAG 作为中科院研发的一款高性能多模态 RAG 框架,在信息检索和生成领域展现出了强大的实力和巨大的潜力。通过其独特的技术原理和丰富的功能特点,它能够有效地解决传统 RAG 系统面临的问题,并在多个应用场景中取得良好的效果。无论是在开放域问答、对话系统、文档处理还是多模态内容创作等方面,FlexRAG 都为用户提供了高效、准确的解决方案。
Github仓库:https://github.com/ictnlp/flexrag
(文:小兵的AI视界)