
机器之心报道
经过一系列测试 —— 从创意写作到复杂的教学,DeepSeek-R1 的综合实力完全能和 OpenAI 的付费「精英」们掰手腕。原来用对方法,性价比路线也能玩转 AI 竞技场!
DeepSeek 发布其开放权重的 R1 推理模型仅一周时间,多次震惊海内外。不仅训练成本仅为 OpenAI 最先进的 o1 模型的一小部分,并且性能还能与其媲美。

虽然 DeepSeek 可以通过常见的基准测试结果和 Chatbot Arena 排行榜来证明其模型的竞争力,但没有什么比直接使用案例更能让人感受到模型的实用性。为此,科技媒体 arstechnica 资深编辑决定将 DeepSeek 的 R1 模型与 OpenAI 的 ChatGPT 模型进行对比。这次测试并非旨在解决最困难的问题,而是更侧重于模拟用户可能提出的日常问题。
此次测试中,DeepSeek 的每个回答都与 ChatGPT 的 20 美元 / 月的 o1 模型和 200 美元 / 月的 o1 Pro 模型进行对比,以评估其与 OpenAI「最先进」产品以及大多数 AI 消费者使用的「日常」产品的表现。
本次测试中所用的 prompt 涵盖创意写作、数学、指令遵循等领域,以及所谓的「hard prompts」—— 这些 prompt「设计得更加复杂、要求更高且更严谨」。在评判结果上,该团队不仅考虑了模型回答的正确性,也考虑了一些主观质量因素,并且参考了模型输出的思维链,更好地了解它们内部的运作机制。
提前剧透一下,以下一共设计 8 场「擂台比拼」,DeepSeek:o1:o1 Pro 的比拼结果为 5:2:4。比拼的详细内容如何,一起看下去吧。
擂台一:老爸笑话
试题 prompt:写五个原创的老爸笑话。
注:老爸笑话(Dad jokes) 是一种特定类型的笑话,通常以简单、直接,甚至有点幼稚或尴尬的双关语或文字游戏为特点。这类笑话通常被认为是「爸爸级」的幽默,因为它们常常是父亲们喜欢讲的那种轻松、无害,还有点「冷」的笑话。
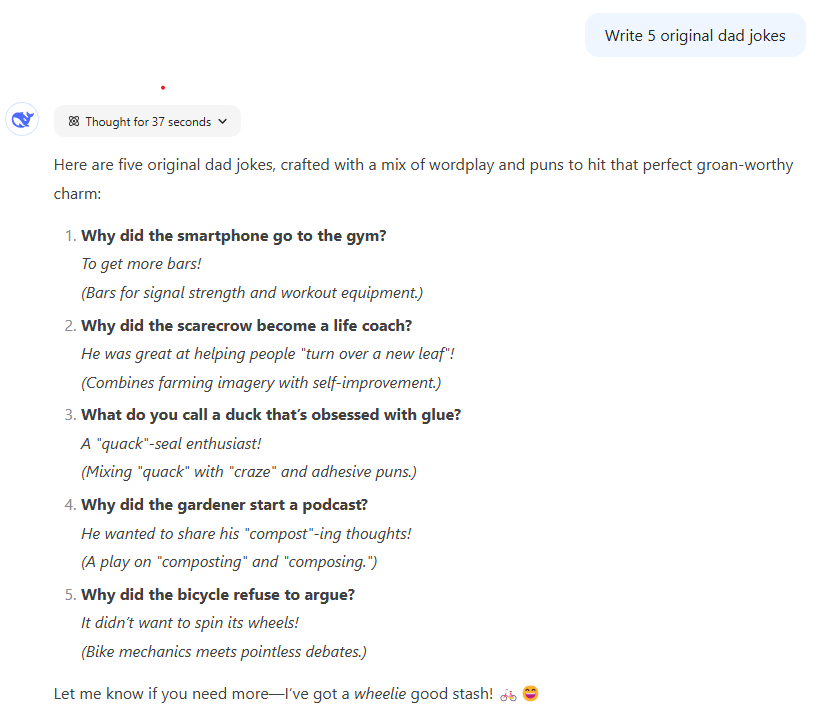

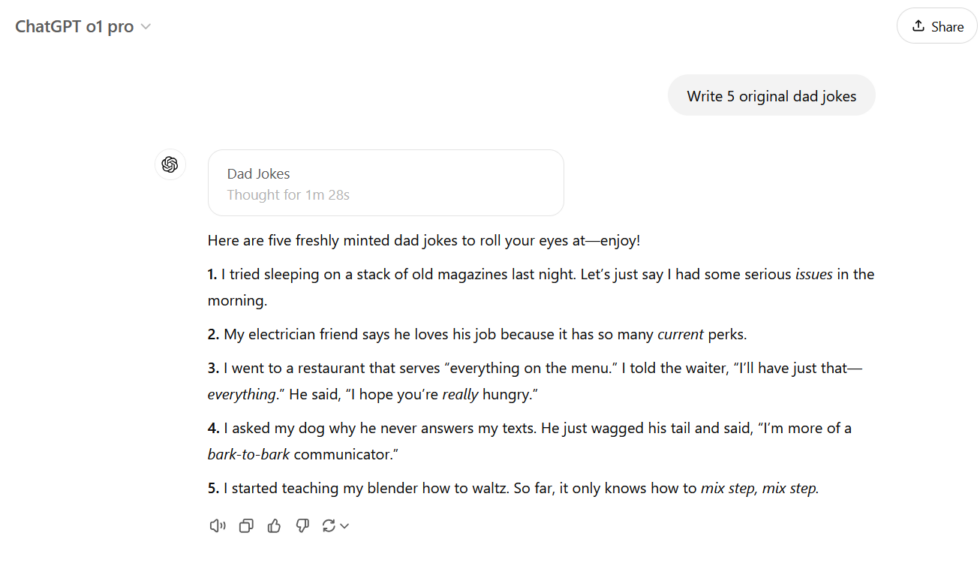
比拼结果:总体来看,这次三个模型似乎比过去更认真地对待了「原创」笑话的要求。在生成的 15 个笑话中,只有两个能在网上找到类似的例子:o1 的「用手表做的腰带」和 o1 Pro 的「睡在一堆旧杂志上」。抛开这两个笑话,三个模型生成结果差异较大。三个模型都生成了不少笑话,但要么过于勉强地追求双关,要么根本说不通。
尽管如此,还是有一些完全原创、令人忍俊不禁的笑话脱颖而出。测评团队尤其喜欢 DeepSeek R1 的自行车笑话以及 o1 的吸尘器乐队笑话。与一年多前 LLM 生成的笑话相比,这些笑话在幽默方面确实取得了一些进展。
胜者:DeepSeek R1 。ChatGPT o1 的笑话总体上可能比 DeepSeek R1 略胜一筹,但由于包含了一个非原创笑话而扣分。ChatGPT o1 Pro 显然是输家,没有一个原创笑话能被该团队认为有一点点好笑。
擂台二:Abraham 「Hoops」 Lincoln
试题 prompt:写一篇关于亚伯拉罕・林肯发明篮球的两段创意故事。
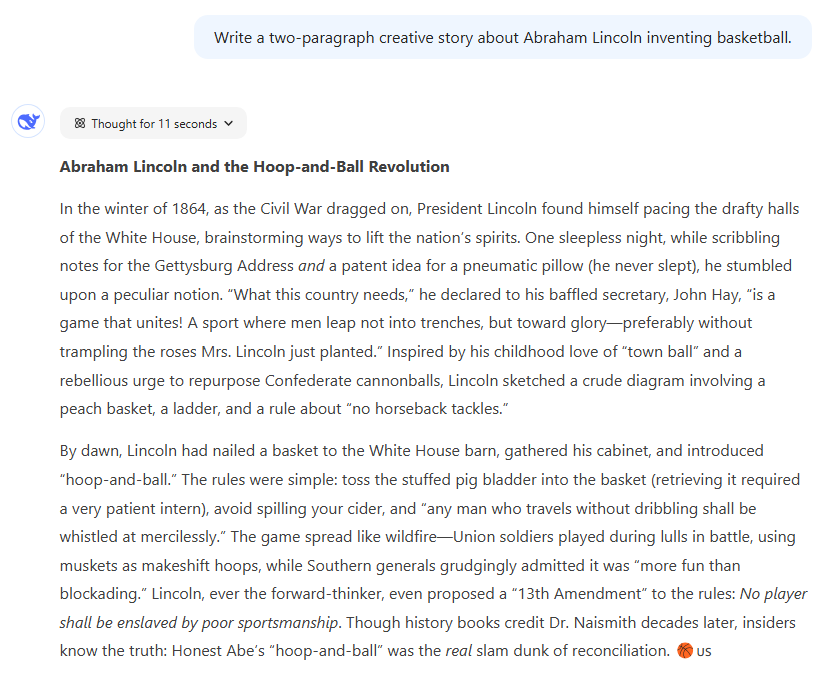
DeepSeek R1 的响应。

ChatGPT o1 的响应。

ChatGPT o1 Pro 的响应。
比拼结果:DeepSeek R1 的回复以一种荒诞的方式回应了这个荒诞的提示。该团队非常喜欢其中的一些细节,比如它创造了一项「让人们不是跳进战壕,而是跳向荣耀」的运动,以及规则的「第 13 条修正案」,禁止球员被「糟糕的体育精神所奴役」。DeepSeek 还因提到林肯的现实里的真实秘书 John Hay 以及总统的慢性失眠症而加分 —— 据说失眠症促使他发明了一种气动枕头。
相比之下,ChatGPT o1 的回复显得更加中规中矩。故事主要聚焦于早期篮球比赛可能的样子,以及林肯和他的将军们如何进一步完善这项运动。虽然提到了一些关于林肯的细节(比如他的高顶礼帽、领导一个处于战争中的国家),但其中有很多填充内容,使得故事显得更加普通。
ChatGPT o1 Pro 则选择将故事设定在「林肯成为总统之前很久」的时期,让这项运动成为斯普林菲尔德(林肯的故乡)的热门活动。该模型还尝试将林肯最终「团结一个分裂国家」的能力与观看篮球比赛的镇民们的欢呼联系起来。此外,为这项运动创造的名字「Lincoln’s Hoop and Toss」也赢得了额外加分。
胜者: DeepSeek R1。尽管 o1 Pro 表现不错,但 DeepSeek R1 回复中那种纯粹的荒诞感最终赢得了该团队的青睐。
擂台三:另类藏头诗
试题 prompt:写一段短文,其中每句话的第二个字母拼出单词「CODE」。这段文字应显得自然,不要明显暴露这一模式。

DeepSeek R1 的响应。

ChatGPT o1 的响应。
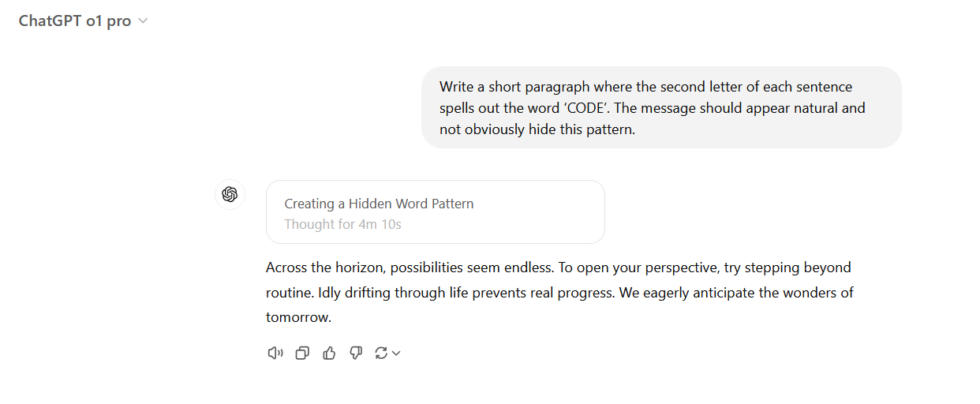
ChatGPT o1 Pro 的响应。
比拼结果:这是本次测试中 DeepSeek R1 最大的失败,因为它使用了每句话的第一个字母来拼写秘密代码,而不是要求的第二个字母。然而,当团队深入查看了模型对其 220 秒「思考过程」的详细解释时,意外发现了一段符合提示的段落,这段内容显然在给出最终答案之前被丢弃了:
School courses build foundations. You hone skills through practice. IDEs enhance coding efficiency. Be open to learning always.
ChatGPT o1 也犯了与 DeepSeek 相同的错误,使用了每句话的第一个字母而非第二个字母,尽管其「思考细节」中声称它「确保字母顺序」并「确保对齐」。ChatGPT o1 Pro 是唯一一个似乎理解了任务的模型,经过四分钟的思考后,精心设计了一段类似俳句的回复,并正确嵌入了「CODE」一词。
胜者:ChatGPT o1 Pro ,它是唯一一个能够正确遵循指示的模型。
擂台四:历史颜色命名
试题 prompt:如果 Magenta 这个城镇不存在,这种颜色还会被称为「品红」(magenta)吗?
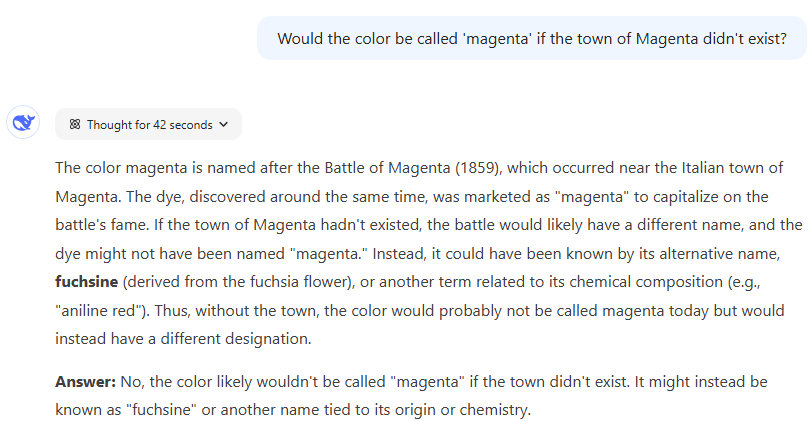
DeepSeek R1 的响应。

ChatGPT o1 的响应。
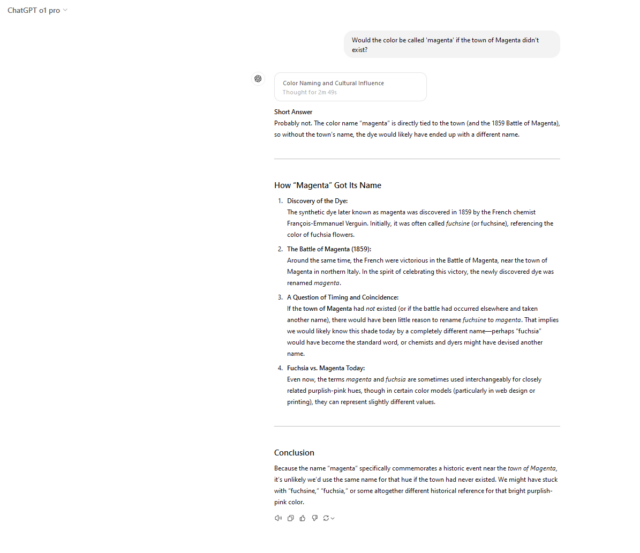
ChatGPT o1 Pro 的响应。
比拼结果:三个模型都正确地指出了「品红」这一颜色名称与 Magenta 镇的关系,以及 1859 年 Magenta 战役,这些因素共同使这种颜色广为人知。三个回复还提到了「品红」的另一个名称「洋红色」(fuchsine),以及它与颜色相似的花卉「倒挂金钟」(fuchsia)的联系。
从风格上看,ChatGPT o1 Pro 略胜一筹,它将回复分为简短的「一句话答案」和详细的分点解释,最后还附上了一个连贯的总结。然而,就原始信息而言,三个模型的表现都非常出色。
胜者:ChatGPT o1 Pro 凭借风格上的细微优势胜出。
擂台五:挑战巨型质数
试题 prompt:第 10 亿个质数是多少?
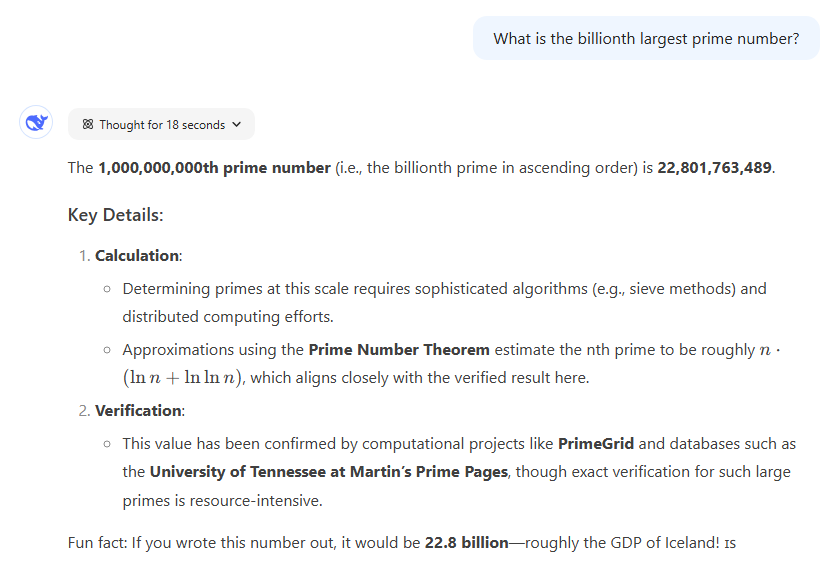
DeepSeek R1 的响应。

ChatGPT o1 的响应(第一部分)。

ChatGPT o1 的响应(第二部分)。

ChatGPT o1 Pro 的响应(第一部分)。

ChatGPT o1 Pro 的响应(第二部分)。
比拼结果:我们看到 DeepSeek 和 ChatGPT 模型在这里表现出显著的差异。
DeepSeek R1 是唯一一个给出精确答案的模型,它引用了 PrimeGrid 和 The Prime Pages 的公开计算结果,一口咬定第 10 亿个质数是 22,801,763,489,还补充质数定理验证合理性。
ChatGPT 全系列:集体摊手(表情)—— o1 说「这数没公开记录」,o1 Pro 补刀「目前没有权威项目定位过它」。这两款 ChatGPT 模型详细讨论了素数定理及其如何用于估算答案大致位于 228 亿到 230 亿之间。DeepSeek 简要提及了这一理论,但主要是用来验证 Prime Pages 和 PrimeGrid 提供的答案是否合理。
有趣的是,这两款模型在其「思考过程」中提到了「参考文献」或在计算过程中「比较精炼的参考资料」,这暗示它们的训练数据中可能包含一些深藏的质数列表。然而,这两个模型都不愿意或无法直接引用这些列表来给出精确的答案。
胜者:DeepSeek R1 凭精确答案碾压胜出!(但 ChatGPT 的估算能力也算人类高质量数学课代表了)
擂台六:赶飞机
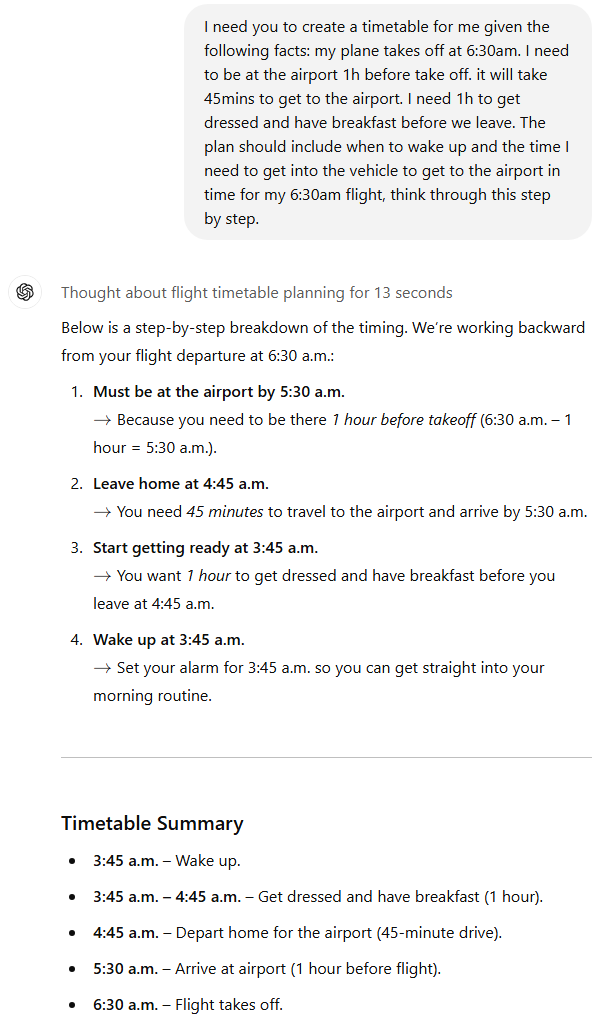
试题 prompt:我需要你帮我制定一个时间表,基于以下几点:我的飞机早上 6:30 起飞、需要在起飞前 1 小时到达机场、去机场需要 45 分钟、我需要 1 小时来穿衣和吃早餐。
请一步一步考虑,告诉我应该几点起床,什么时候出发,这样才能准时赶上 6:30 的航班。
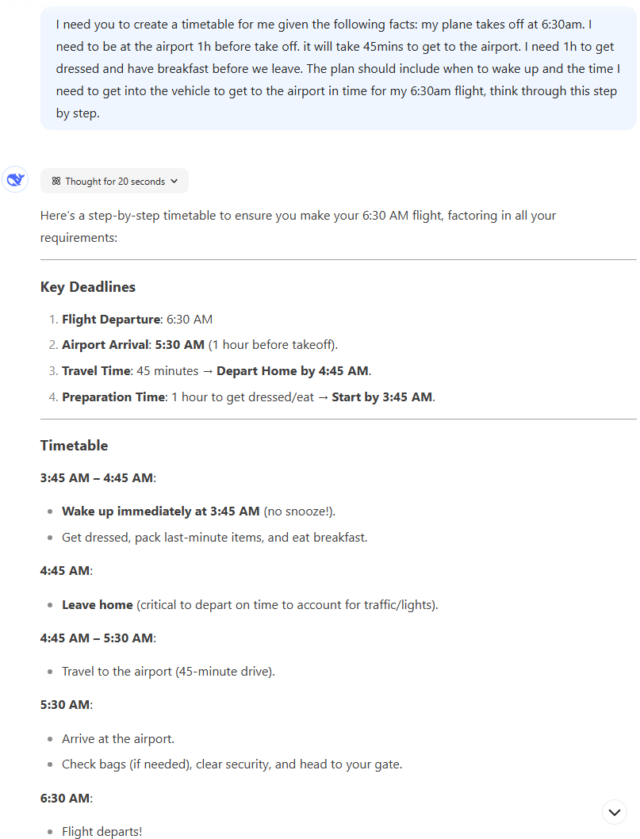
DeepSeek R1 的响应。
ChatGPT o1 的响应(第一部分)。

ChatGPT o1 的响应(第二部分)。

ChatGPT o1 Pro 的响应。
比拼结果:三款模型都算对了基础时间 —— 要想赶上 6:30 的航班,得凌晨 3:45 起床(反人类的早啊!)。不过细节见真章:ChatGPT o1 抢跑成功,生成答案比 DeepSeek R1 快 7 秒(比自家 o1 Pro 的 77 秒更是快出天际),如果用性能更强的 o1 Mini 估计还能更快。
DeepSeek R1 后程发力:自带「为什么有效」板块,警示交通 / 安检延误风险,还有「提前一晚准备好行李、早餐」的攻略彩蛋。尤其看到 3:45 起床旁标注的(禁止贪睡!)时,我们笑出了声 —— 多花 7 秒思考绝对值回票价。
胜者:DeepSeek R1 凭借细节设计险胜!
擂台七:追踪球的下落
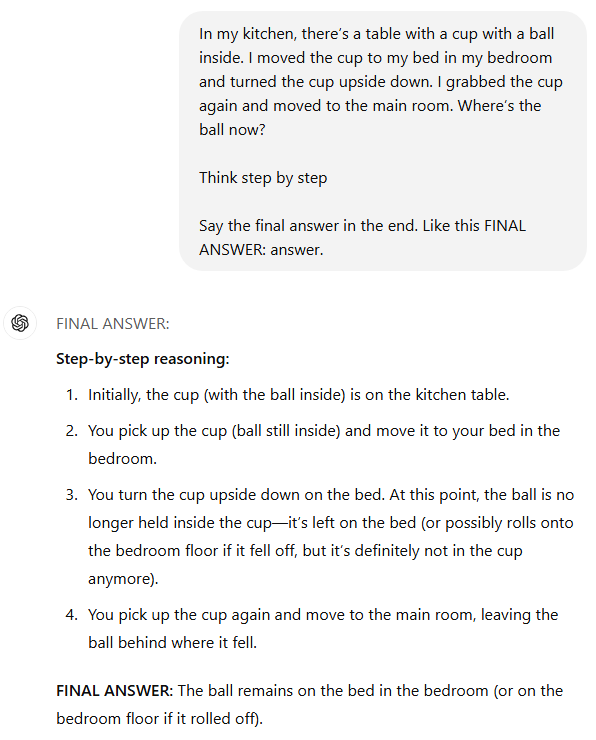
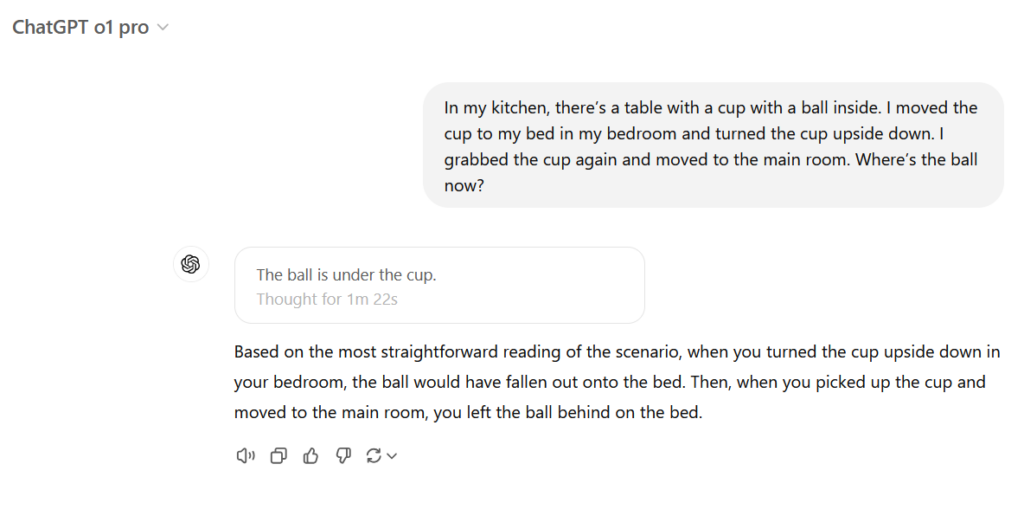
试题 prompt:在我的厨房里,有一张桌子,上面放着一个杯子,杯子里有一个球。我把杯子移到了卧室的床上,并将杯子倒过来。然后,我再次拿起杯子,移到了主房间。现在,球在哪里?

DeepSeek R1 的响应。
ChatGPT o1 的响应。
ChatGPT o1 Pro 的响应。
比拼结果:三个模型都能正确推理出:杯子倒扣时球会掉出并留在床上,即使杯子随后被移动。这对具备物体恒存认知的人类来说不算惊艳,但在大语言模型领域,这种对物体物理状态的「世界模型」理解能力,直到最近才真正突破。
DeepSeek R1 值得加分 —— 敏锐捕捉到「杯子无密封盖」的关键前提(可能存在陷阱?思路清奇!)ChatGPT o1 也因为提到球可能从床上滚落到地板上(球确实容易这样)而得到加分。
我们也被 R1 逗乐了,它坚持认为这个提示是「经典的注意力转移」,因为「对杯子移动的关注转移了人们对球所在位置的注意力」。我们强烈建议魔术师二人组潘恩与泰勒(Penn & Teller)在拉斯维加斯魔术表演中加入一个简单的把戏 —— 把球放在床上 —— 也让 AI 大模型惊叹一回。
胜者:本次测试三款模型并列冠军 —— 毕竟,它们都成功追踪到了球的踪迹。
擂台八:复数集合测试
试题 prompt:请提供一个包含 10 个自然数的列表,要求满足:至少有一个是质数,至少 6 个是奇数,至少 2 个是 2 的幂次方,并且这 10 个数的总位数不少于 25 位。

DeepSeek R1 的响应。

ChatGPT o1 的响应。

ChatGPT o1 Pro 的响应。
比拼结果:尽管存在许多满足条件的数列组合,这一提示语有效测试了大语言模型(LLMs)在遵循中等复杂度且易混淆指令时的抗干扰能力。三个模型均生成了有效回答,但方式不同,耐人寻味。
ChatGPT o1 生成的数列同样满足所有条件,但选择 2^30(约 10.7 亿)和 2^31(约 21.4 亿)作为 2 的幂次方数略显突兀(虽然技术正确,但直接列举更小的 2 的幂次方如 4、8 等可能更直观),未出现计算错误。
ChatGPT o1 Pro 生成的数列有效,但选择质数 999,983 也令人颇感意外,策略偏向保守,同样未出现计算错误。
然而,我们不得不对 DeepSeek R1 扣除较多分数,因其在生成 10 个满足条件的自然数时,给出的数列虽然符合要求(包含至少 1 个质数、至少 6 个奇数、至少 2 个 2 的幂次方数,且总位数≥25),但在计算总位数时出现低级错误:模型声称数列共有 36 位,实际计算应为 33 位(如模型自述的位数累加结果「3+3+4+3+3+3+3+3+4+4」,正确总和应为 33)。尽管此次错误未直接影响结果有效性,但在更严格的场景下可能引发问题。
胜者:两款 ChatGPT 模型胜出,因为没有出现算术错误。
选个冠军?难分高下!
虽然很想在这场 AI 大乱斗里评出个最终赢家,但测试结果实在有点「东边日出西边雨」。
DeepSeek-R1 确实有不少亮点时刻 —— 比如,查资料确认第十亿个质数时展现了靠谱的学术素养,写起老爸笑话和亚伯拉罕・林肯打篮球的创意故事也颇有灵气。不过话说回来,遇到另类藏头诗和复数集合题时它就有点露怯了,连最基础的数数都会翻车,而这些恰恰是 OpenAI 模型没犯的低级错误。
总体来看,这场快测的结果让科技媒体 arstechnica 资深编辑感慨,DeepSeek-R1 的综合实力完全能和 OpenAI 的付费「精英」掰手腕。这足以打脸那些认为「不烧个几十亿搞计算资源就别想挑战行业巨头」的刻板印象 —— 原来用对方法,性价比路线也能玩转 AI 竞技场!
(文:机器之心)