
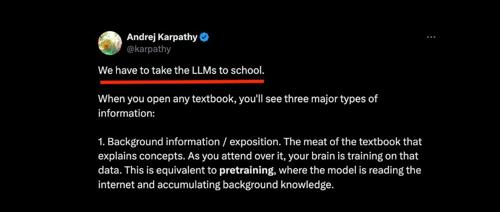

AI 大神Andrej Karpathy 刚刚发了一篇推文,他将训练大型语言模型 (LLM) 的过程巧妙地比作教育学生,并以教科书的结构为框架,阐述了当前 LLM 训练的现状和未来方向
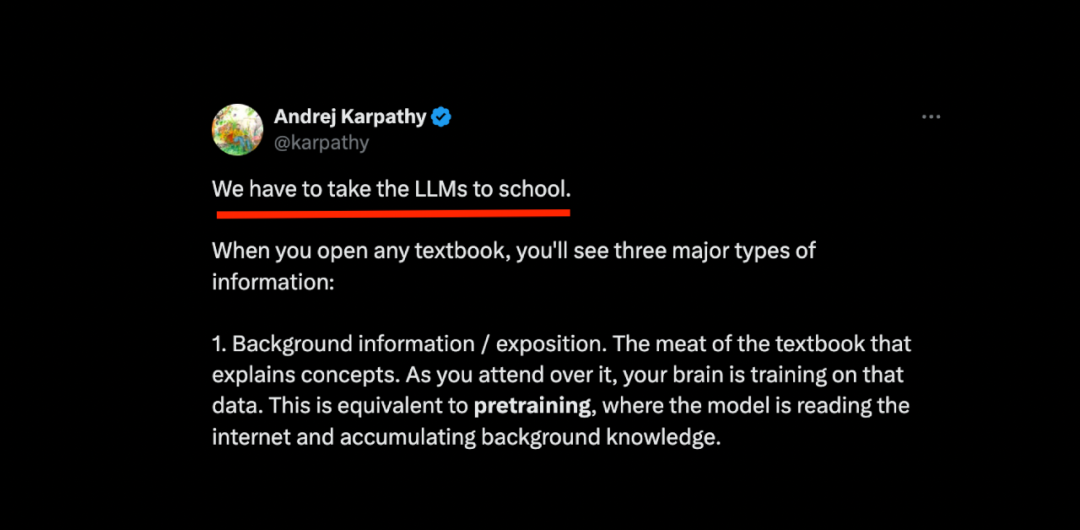
这可能是目前我看到过关于预训练,监督式微调,强化学习最好最通俗易懂的解释,分享给大家
Karpathy指出,当我们打开任何一本教科书,都会看到三种主要类型的信息:
-
1. 背景信息 / 阐述 (Background information / exposition): 这是教科书的核心内容,用于解释各种概念和知识。学生通过阅读和学习这些内容来构建知识体系,这就像是 LLM 的预训练 (pretraining) 阶段。在预训练阶段,模型通过阅读海量的互联网文本,学习语言的规律、世界的知识,积累广泛的背景知识,为后续的学习打下基础
-
2. 例题及解答 (Worked problems with solutions): 教科书会提供具体的例题,并详细展示专家如何解决这些问题。这些例题是示范,引导学生模仿学习。这与 LLM 的 监督式微调 (supervised finetuning) 阶段相对应。在微调阶段,模型学习人类专家提供的“理想答案”,学习如何生成高质量、符合人类期望的回复,例如助手类应用的“理想回答”
-
3. 练习题 (Practice problems): 教科书每章节末尾通常会设置大量的练习题,这些题目往往只提供最终答案,而不给出详细的解题步骤。练习题旨在引导学生通过 试错 (trial & error) 的方式进行学习。学生需要尝试各种方法,才能找到正确的答案。卡帕西认为,这与 强化学习 (reinforcement learning) 的概念高度相似
Karpathy强调,目前我们已经让 LLM 经历了大量的“阅读”和“示例学习”,也就是预训练和监督式微调,但对于“练习题”这一环节,也就是强化学习,我们还处于一个新兴的、尚待开发的阶段
他认为,当我们为 LLM 创建数据集时,本质上与为它们编写教科书并无二致。为了让 LLM 真正“学会”,我们需要像编写教科书一样,提供这三种类型的数据:
大量的背景知识 (Background information): 对应预训练,让模型积累广泛的知识
示范性的例题 (Worked problems): 对应监督式微调,让模型学习高质量的输出
大量的练习题 (Practice problems): 对应强化学习,让模型在实践中学习,通过试错和反馈不断改进
写在最后
卡帕西总结道,我们已经让 LLM 经历了大量的“阅读”和“学习例题”,但更重要的是,我们需要引导它们进行大量的“实践练习”。 LLM 需要阅读,更需要实践。 只有通过大量的实践练习,才能真正提升 LLM 的能力,让它们更好地理解世界、解决问题
参考:
https://x.com/karpathy/status/1885026028428681698
⭐
(文:AI寒武纪)