

DeepSeek 暴雷了?!

当整个硅谷及国内民众还在为DeepSeek「仅用600万美元训练出匹敌GPT-4o的AI模型」疯狂刷屏兴奋时,半导体分析机构SemiAnalysis一纸报告指出——
这个数字的水分实在有点大!

其称所谓的600万美元,不过是最终训练阶段的GPU电费账单,却完全忽略了资本支出和研发成本。
并指出,模型训练真正的烧钱黑洞藏在冰山之下:
-
1.3亿美金的服务器基建
-
9.44亿美金的集群运维
-
数月的架构试错
-
……

要全部算下来,实际开支将直奔10亿美元量级!
甚至要更多。
公关「障眼法」?
OpenAI前脚刚秀完o1模型的推理肌肉,DeepSeek后脚就掏出R1模型叫板对标,甚至反超。
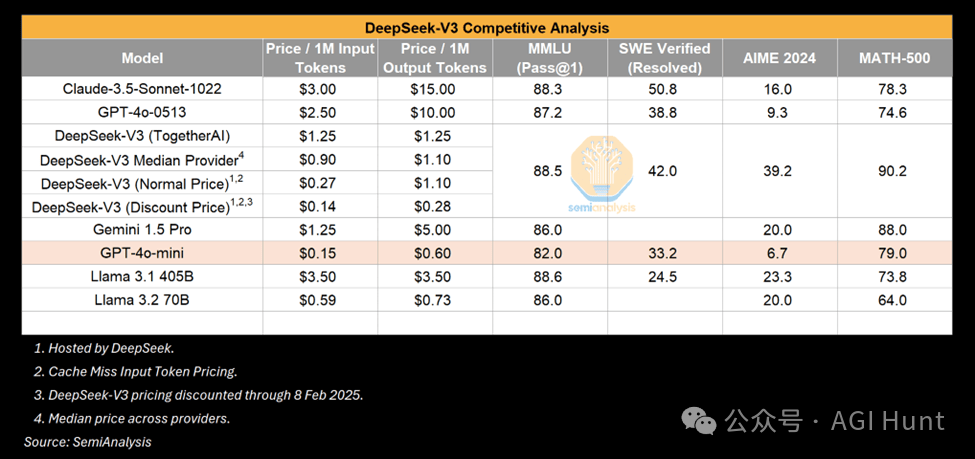
但细看论文会发现:R1的算力消耗被打码了,合成数据生成和强化学习需要的大量GPU资源也被刻意隐藏。
而Google早在1个月前就悄悄上线了性能相当、价格更低的Gemini Flash 2.0,却因市场策略拉胯惨遭无视。但DeepSeek靠着「中国黑马」的叙事红利,硬生生把行业带进了「算力性价比幻觉」的狂欢,甚至让Meta 的高薪高管们心头一紧。
创新「明暗线」
如果说成本争议是烟雾弹,有些公关作风,那DeepSeek的多头潜在注意力机制(MLA) 则是实打实的硬核技术创新和突破了。
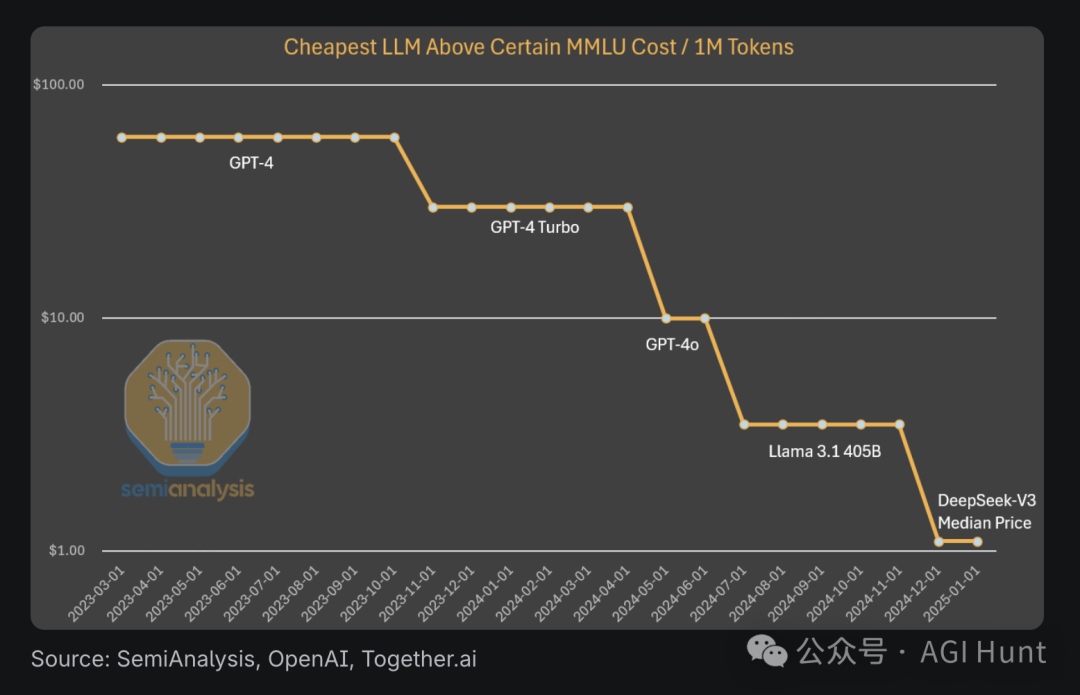
这项让KV缓存暴降93.3%的黑科技,直接把推理成本砍到地地价,让DeepSeek 变身AI 界拼多多。
甚至多家北美AI实验室都连夜成立专项组,对DeepSeek 论文和代码逐字研读。据说连Hinton本人都对着论文拍大腿:
这玩意我们怎么就没想到?
但技术创新掩盖不了战略焦虑。
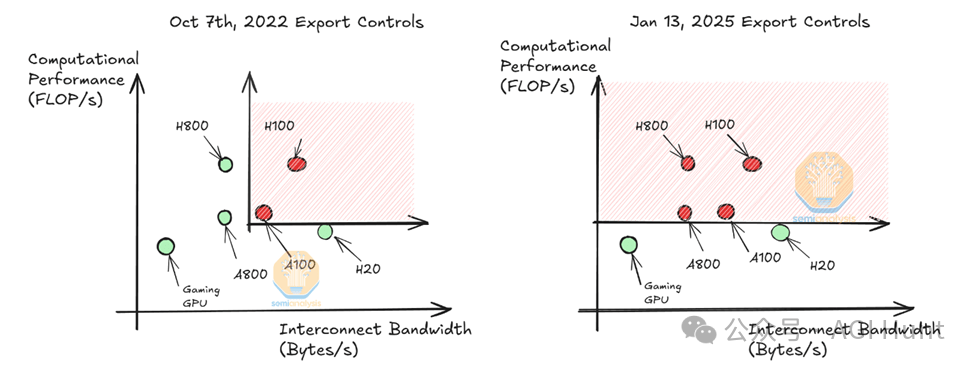
当美国收紧芯片出口管制,DeepSeek的算力底牌靠的将只能是提前囤积的1万张A100显卡。而如今面对禁售令升级,中国团队不得不用特供版H20芯片硬刚,性能缩水后或只能指望:「算法优化能解决一切」了。
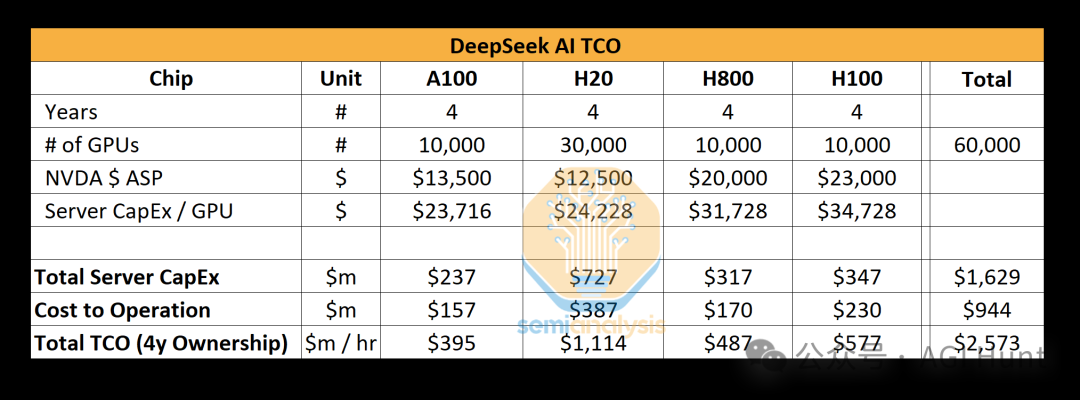
也许,还有华为的升腾?
「灰犀牛」洗牌行业
这场争议暴露出AI军备竞赛的残酷真相:小模型逆袭的神话,本质是巨头们的技术溢出。
DeepSeek的R1模型被扒出大量使用GPT-4生成数据,OpenAI的法务团队已磨刀霍霍准备起诉。
而Meta、Mistral等开源阵营更是集体破防——他们辛苦调教的小模型,转眼就被中国团队用RLHF(人类反馈强化学习)弯道超车。
需要关注的是算法进步与硬件消耗的死亡交叉——SemiAnalysis预测年底推理成本还将再降5倍,但代价是需要吞噬更多算力资源。
当Anthropic CEO达里奥说出「10倍算法进步抵得上100倍算力增长」时,不知道他有没有听见老黄在仓库数钞票的笑声。
而DeepSeek 的模型也证明了一个重要趋势:一个资金充足、重点突出的初创公司,完全有可能推动技术的边界。
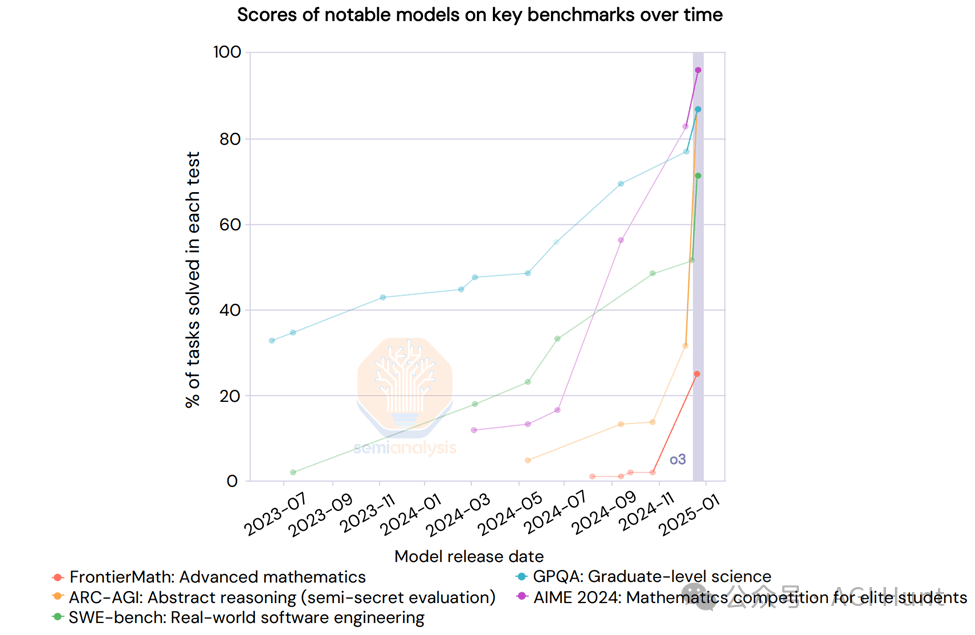
在报告最后,SemiAnalysis 指出:
「说到底,成本只是故事的一部分。真正重要的是技术创新和其带来的影响。」
这场始于成本争议的风暴,正演变成中/美、开源/闭源等多方的角力。
而当这些闭源AI 实验室还在为「是否该相信中国公司的技术报告」吵得不可开交时,DeepSeek已经默默更新了招聘页:
「诚聘GPU芯片架构师,年薪上不封顶」。
下为译文:
(文:AGI Hunt)