
UC Berkeley教授发现了一个规律:AI答对题时话少,答错时反而话多!
Berkeley教授Alex Dimakis最近发现了一个有趣现象:
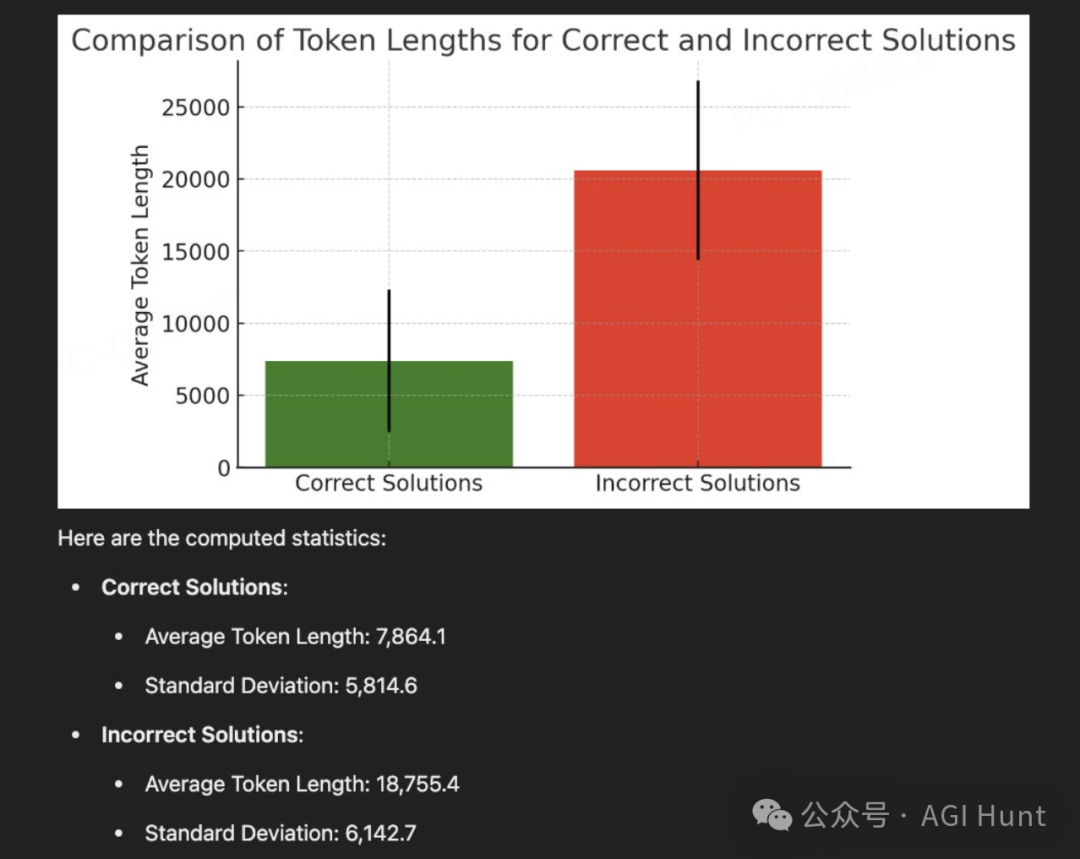
当AI模型「DeepSeek-R1」回答问题时,错误答案往往字数更多,而正确答案却简短精炼。
这听起来像不像曾经的你写论文时的状态?
不懂就疯狂凑字数!
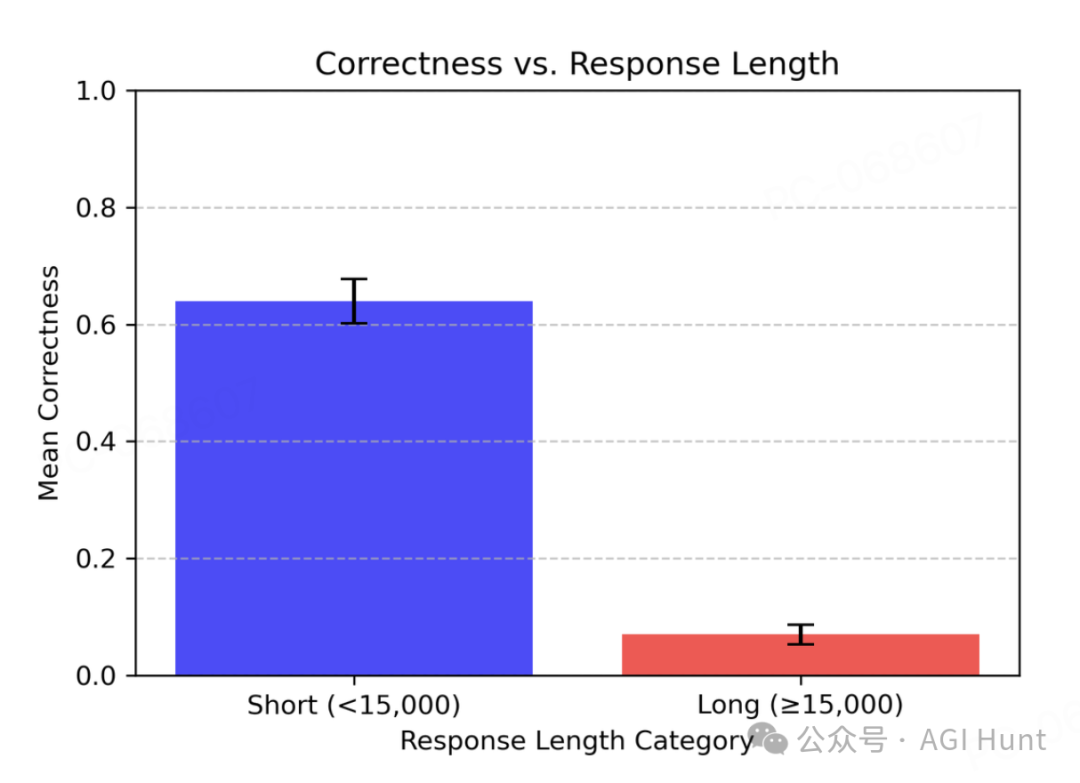
基于这个发现,Dimakis教授提出了一个简单而巧妙的方法,他称之为「Laconic解码」:
——让模型并行运行5次,然后选择字数最少的那个答案。
实验结果令人振奋:仅仅使用这个方法,在AIME24测试中的准确率就提升了6-7个百分点!
而且,比其他解码方法更快。
为什么会这样?
对此,众多研究人员给出了不同的解释:
Shreyas表示:
这可能是因为AI能答对的问题本来就比较简单,所以不需要太长的推理链。
RiQi的比喻更形象:
这就像考试时的学生,当不知道答案时,会写很多自己不确定的内容,希望能蒙对几分。
Leonard Volner 则引用了爱因斯坦的话:
如果你不能简单地解释它,那说明你理解得还不够透彻。
训练能解决这个问题吗?
对此,一些研究者已经开始探索解决方案。
mkurman分享了他的经验:
我在研究GRPO时注意到这个问题,已经修改了评分函数来惩罚过长的序列。如果序列超过最大长度,甚至不会得到任何奖励。
Soumanta Das则指出:
Kimi 1.5在RL训练步骤中就加入了长度惩罚,而R1没有。这或许能解释这种行为。

实践应用
Agent B分享了他们的实践经验,提出了一个两步走的方案:


不过Ahmad Zaim Hilmi 提醒道:
这种并行运行多次的方法可能会在输入较长时变得开销很大。
Bálint Barna 则提出了一个更简单的想法:
为什么不直接在提示词中要求模型保持回答简短呢?
这个发现不仅让我们对AI模型的行为有了新的认识,也为提高AI系统的准确性提供了一个简单而有效的方法。
这似乎也应验这句话:
——真相只有一个,但谎言却有无数种。
(文:AGI Hunt)