
北大发布学术搜索评测ScholarSearch:难倒一众DeepResearch的“开卷考试”

北京大学DS-Lab发布ScholarSearch数据集,评估LLMs在学术研究中的信息检索能力。结果显示现有模型普遍表现不佳,仅凭推理无法解决复杂问题,需结合搜索功能以提高准确率。
北京大学DS-Lab发布ScholarSearch数据集,评估LLMs在学术研究中的信息检索能力。结果显示现有模型普遍表现不佳,仅凭推理无法解决复杂问题,需结合搜索功能以提高准确率。

MathFusion团队提出了一种新的方法,通过指令融合增强大语言模型解决数学问题的能力。仅使用45K的合成指令,在多个基准测试中平均准确率提升了18.0个百分点。MathFusion通过顺序、并列和条件三种融合策略将不同数学问题巧妙结合生成新问题,显著提升模型性能与数据效率,并在in-domain和out-of-domain基准测试中均表现出优越表现。

R-KV团队发布了一种新的高效压缩方法,可以显著减少大模型推理时的冗余信息。该方法通过实时对token进行排序和重要性评估来保留关键且多样化的信息,并在计算开销适中的情况下实现了更高的准确率和吞吐量。
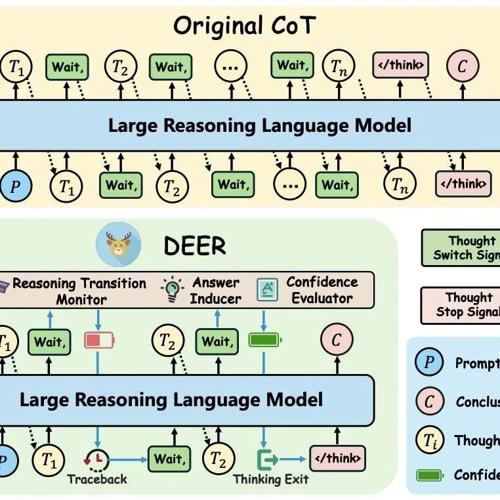
MLNLP是国内外知名的机器学习与自然语言处理社区。旨在促进学术界、产业界和爱好者的交流合作。近期提出DEER技术来解决大型语言模型冗长推理的问题,通过监测思考转折词和置信度评估实现。

OmniParser V2通过更大规模的数据集训练,提升了对小图标检测的准确率和推理速度。其与LLM结合后在多个基准测试中表现优异,平均准确率达到39.6%。
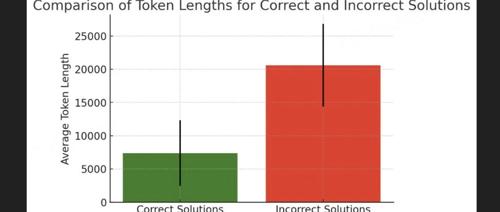
UC Berkeley教授发现AI答错题时话多答对题时话少的现象。为了提高准确率,Dimakis提出「Laconic解码」方法,在AIME24测试中提升了6-7个百分点的准确率。


