

北京大学DS-Lab团队 投稿
量子位 | 公众号 QbitAI
LLMs能当科研助手了?
北大出考题,结果显示:现有模型都不能胜任。
北京大学DS-Lab发布ScholarSearch,这是首个专门用于评估大语言模型在学术研究中复杂信息检索能力的数据集,包含223道高难度的学术检索题目及其答案。
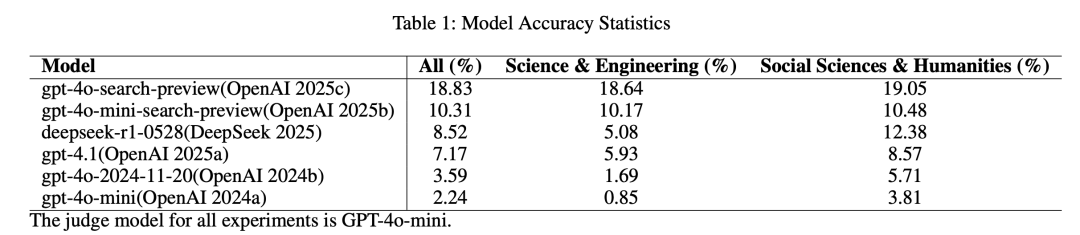
它对具备联网搜索能力的代表性模型及纯推理模型进行了评估,结果显示,顶尖的纯推理模型,如GPT-4.1、DeepSeek-R1,在处理这些问题时准确率普遍低于9%。
具备搜索功能的模型,相较于其无搜索能力的版本,准确率有显著提升,例如,GPT-4o-mini的准确率提升超过四倍。
尽管浏览能力带来了显著改进,但即便是最先进的搜索增强型模型,如GPT-4o-search-preview,其准确率仅为18.83%。
方法
OpenAI的Deep Research、Grok的DeepSearch、Gemini的Deep Research以及月之暗面的Kimi-Researcher等,以“深度搜索”功能为核心,为攻克高难度信息检索任务提供了新的范式。
然而,学术界与业界目前尚未建立起一套公认的评估体系与标准数据集,用以系统性地检验这些新兴模型在真实学术研究场景下的实际效能。
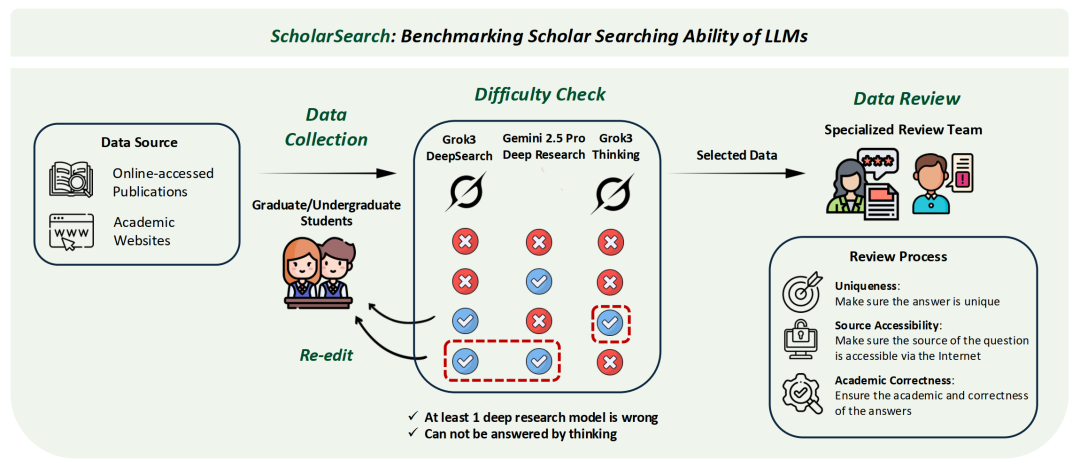
北京大学DS-Lab发布ScholarSearch,旨在对LLMs的检索、信息整合及推理能力进行综合性、极限性考验。
研究团队招募了来自北京大学各个学院的本科和研究生志愿者,并为他们提供了集中培训。志愿者从公开可访问的在线出版物和网站中选择材料,以制定需要网络搜索解答的学术问题。
为确保问题能真正考验模型的深度研究能力,所有初步构建的问题必须通过以下双重负向筛选标准的验证:
1.不能通过Grok 3的Thinking模式获得正确答案,确保问题需要深入广泛的信息检索能力。
2.Grok 3的DeepSearch模式或Gemini 2.5 Pro的Deep Research功能至少有一个未能提供正确答案,确保问题的高难度。
成功满足上述标准的问题随后提交给专门的审核团队进行数据审核,以确保以下几点:
答案唯一性:每个问题对应唯一的、明确无误的答案。
来源可访问性:回答问题所需的参考来源可通过互联网公开获取。
学术正确性:问题的学术价值和答案的正确性根据提供的来源进行验证。
任何未能达标的问题都将被退回进行迭代修订,直至合格。

ScholarSearch具有以下核心特点:
高度的真实性与应用价值:数据集中的所有问题均源于真实的学术研究与学习情境。其设计旨在忠实反映研究者面临的实际信息挑战,保证了评估结果能够真实地反映模型在实际应用中的效能。
卓越的挑战性与深度:ScholarSearch的难度经过严格审查,确保即便是顶尖的模型(如 Grok DeepSearch 或 Gemini Deep Research)也难以一次性给出正确答案。大多数问题需要进行多次深度搜索才能得出答案,充分考验模型的复杂推理和信息整合能力。
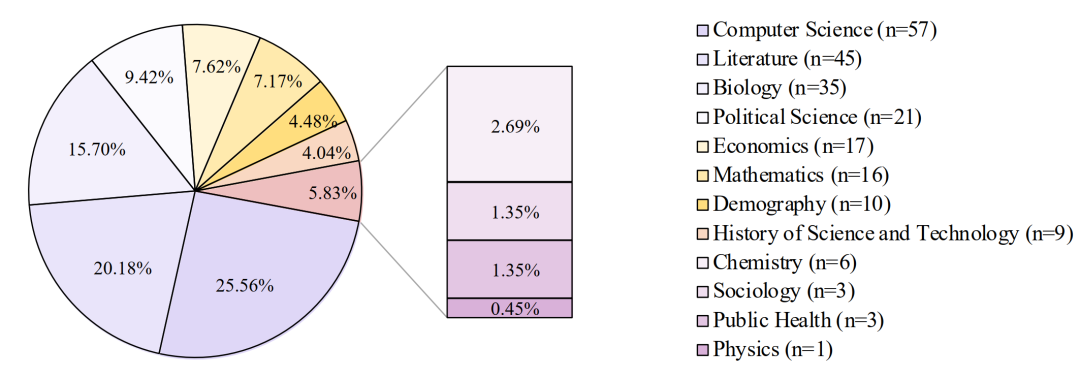
广泛的学科覆盖:为确保评估的全面性与代表性,ScholarSearch围绕科学与工程领域(Science & Engineering)和社会科学与人文学科领域(Social Sciences & Humanities)两大门类进行构建,共涵盖了15个不同的细分学科。
结果
研究团队使用ScholarSearch对具备联网搜索能力的代表性模型及纯推理模型进行了评估,结果如图所示。评估结果明确揭示,现有模型的整体表现欠佳,其学术搜索能力亟待提升。
仅凭推理无法解决学术研究问题: 实验明确指出,ScholarSearch数据集中的问题无法仅通过模型的预训练知识和推理能力解决。顶尖的纯推理模型,如GPT-4.1、DeepSeek-R1,在处理这些问题时准确率极低,普遍低于9%。这表明学术查询具有高度复杂性,这超出了静态、内嵌知识库的能力范畴。
浏览能力显著提升模型性能: 赋予模型访问互联网的浏览能力可以提高其准确性。具备搜索功能的模型,相较于其无搜索能力的版本,准确率有显著提升,例如,GPT-4o-mini的准确率提升超过四倍。此外,搜索能力也平衡了模型在不同学科领域的表现,在科学与工程领域和社会科学与人文学科领域达到了相当的水平。这一结果证实,对于解决复杂的学术问题,进行实时信息检索、访问数据并进行交叉引用的能力至关重要。
当前搜索模型仍不足以应对深度学术探究: 尽管浏览能力带来了显著改进,但即便是最先进的搜索增强型模型,如GPT-4o-search-preview,准确率仅为18.83%。在解决复杂学术问题方面仍表现不充分。这揭示了当前模型在进行深度研究、整合专业知识以及执行复杂的多源推理时存在的差距,也揭示了Deep Research模型的研发需求。
ScholarSearch作为一个在深度搜索领域的学术基准测试集,不仅衡量了模型的当前能力,更揭示了现有技术与真实学术工作流之间的核心差距,为未来的大语言模型掌握复杂综合的语境理解、海量资料来源的批判准确性验证,提供了有挑战的参考。
论文链接:https://arxiv.org/abs/2506.13784
数据集链接:
https://huggingface.co/datasets/PKU-DS-LAB/ScholarSearch
课题组huggingface主页:
https://huggingface.co/PKU-DS-LAB
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)