

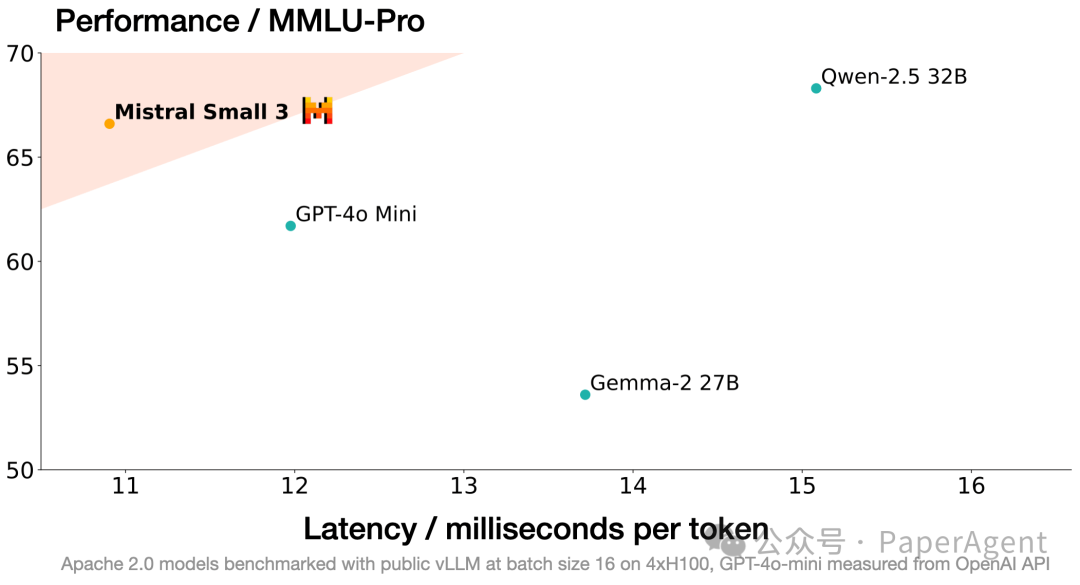
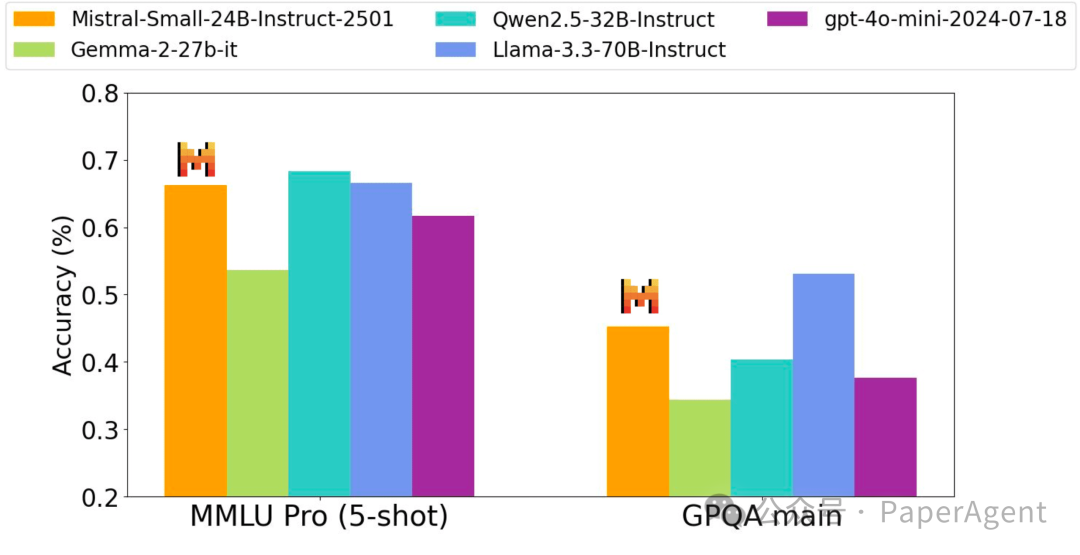
Mistral Small 3 在70B以下的“小型”大型语言模型类别中树立了新的标杆,在性能上能够与更大的模型(例如 Llama 3.3 70B 或 Qwen 32B)竞争,并且是像 GPT4o-mini 这样的封闭专有模型的优秀开源替代品。
-
多语言支持:支持多种语言,包括英语、法语、德语、西班牙语、意大利语、中文、日语、韩语、葡萄牙语、荷兰语和波兰语。
-
以Agent为中心:提供顶级的Agent能力,支持原生功能调用和JSON输出。
-
高级推理:具有最先进的对话和推理能力。
-
Apache 2.0许可:开放许可,允许用于商业和非商业目的的使用和修改。
-
上下文窗口:32k上下文窗口。
-
系统提示:对系统提示有很强的遵循和支持。
-
分词器:使用Tekken分词器,词汇量为131k。
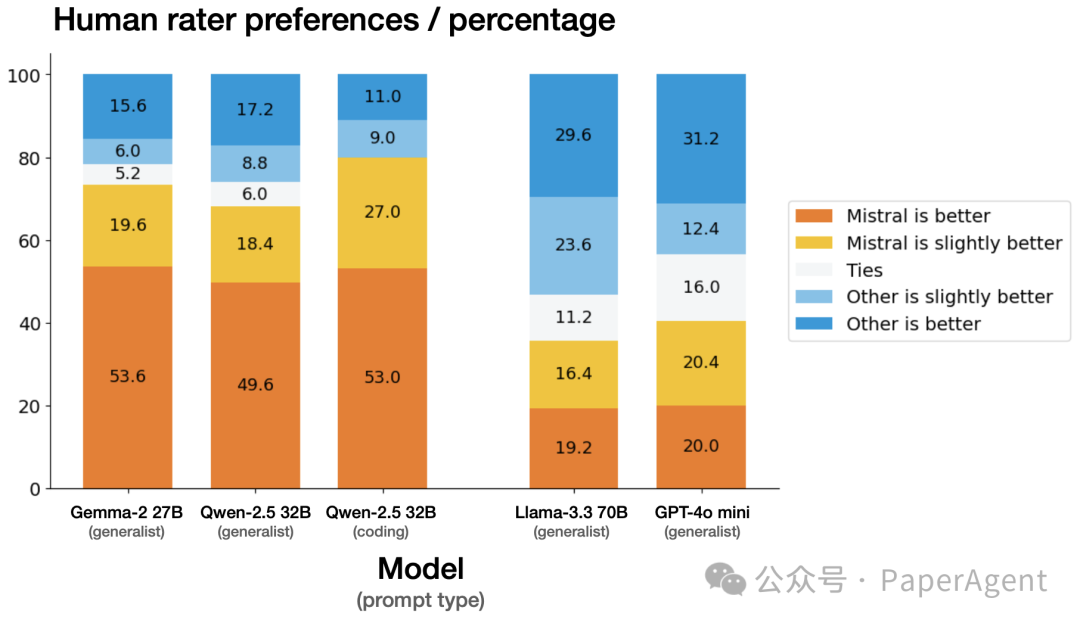
人类评估
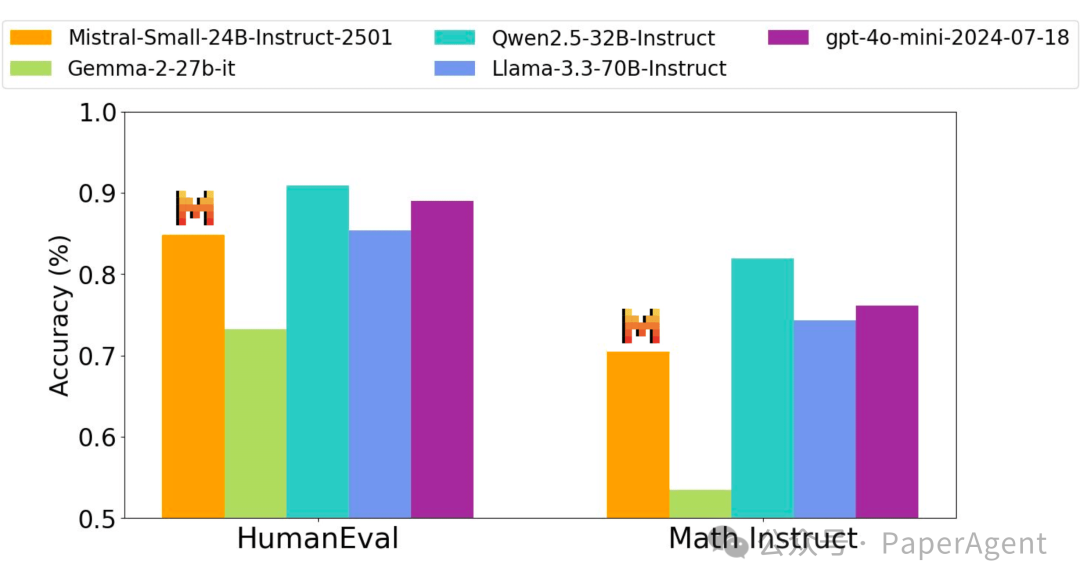

https://mistral.ai/news/mistral-small-3/https://hf-mirror.com/mistralai/Mistral-Small-24B-Instruct-2501
(文:PaperAgent)