
825 https://github.com/mshumer/OpenDeepResearcher
658 https://github.com/nickscamara/open-deep-research
529 https://github.com/btahir/open-deep-research
499 https://github.com/dzhng/deep-research
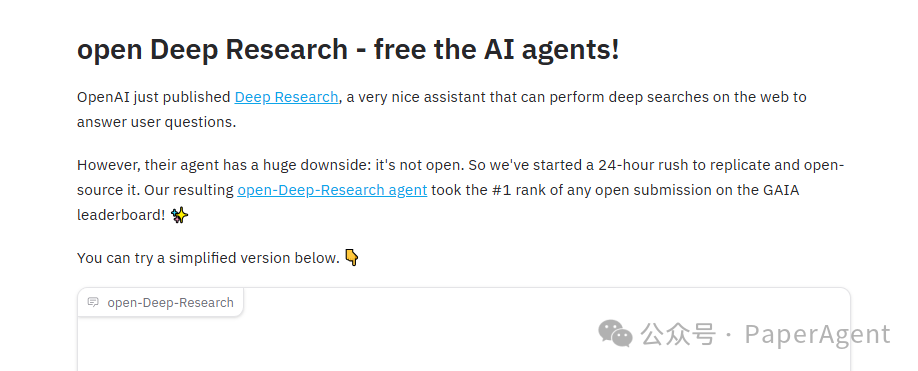
open-Deep-Research是一个完全开放的智能Agent,能够:自主浏览网页、滚动和搜索页面、下载和操作文件、对数据进行计算……
在GAIA基准测试中,Deep Research在验证集上的准确率为67%。
➡️ open Deep Research的准确率是55%(由o1提供支持),但它已经是:
-
提交的解决方案中最佳的pass@1方案
-
最佳的开源方案
体验:https://m-ric-open-deep-research.hf.space/
-
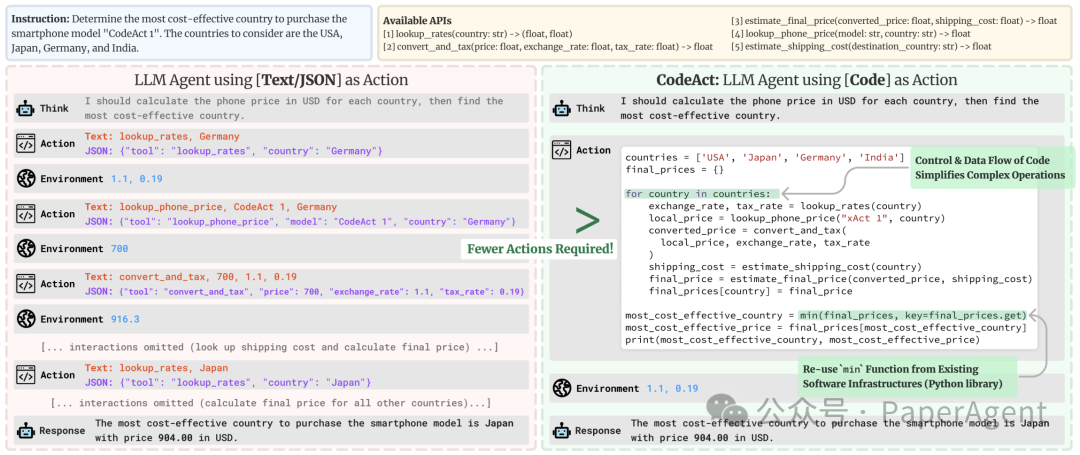
代码操作比JSON简洁得多。 -
需要运行 4 个包含 5 个连续操作的并行流?在 JSON 中,您需要生成 20 个 JSON blob,每个都在其单独的步骤中;在 Code 中只需 1 个步骤。 -
论文显示,平均而言,代码操作所需的步骤比 JSON 少 30%,这相当于生成的token也减少了 30%。由于 LLM 调用通常是Agent系统的度量成本,这意味着Agent系统运行成本降低了约 30%。 -
代码允许重复使用来自公共库的工具 -
基准测试中表现更佳,原因有二: -
更直观的表达动作的方式 -
LLM在训练中广泛接触代码
-
网络浏览器。虽然需要像Operator这样的功能齐全的网络浏览器交互才能实现全部性能,但目前我们从一个非常简单的基于文本的网络浏览器开始进行第一个概念验证。 -
一个简单的文本检查器,能够读取一堆文本文件格式。
-
扩展可读取的文件格式的数量 -
提出更细粒度的文件处理 -
用基于视觉的浏览器取代网络浏览器
https://huggingface.co/blog/open-deep-researchhttps://github.com/huggingface/smolagents/tree/gaia-submission-r1/examples/open_deep_research
(文:PaperAgent)