

近年来,大模型技术突飞猛进,全球各大科技公司纷纷投入研发,形成了一系列成熟的主流大模型。以下是目前国内外最具代表性的大模型:
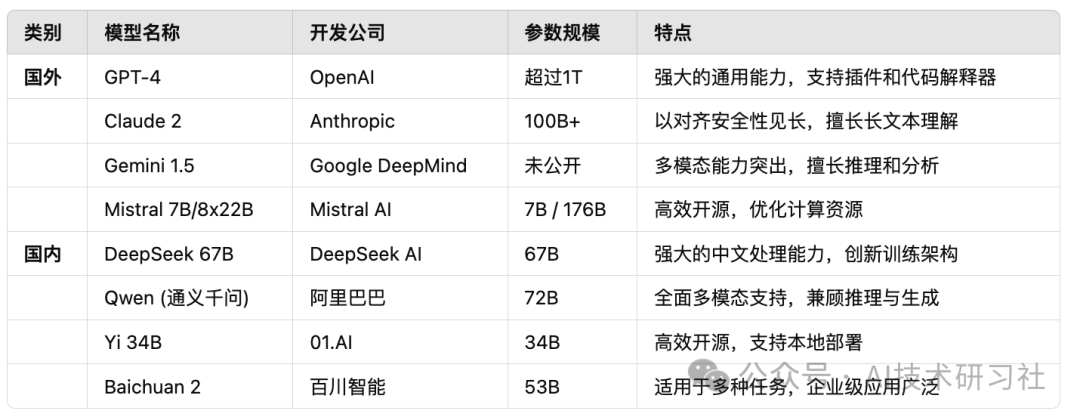
从上表可以看出,国内大模型在中文理解方面更具优势,同时涌现出大量开源方案,为用户提供了更灵活的部署选择。
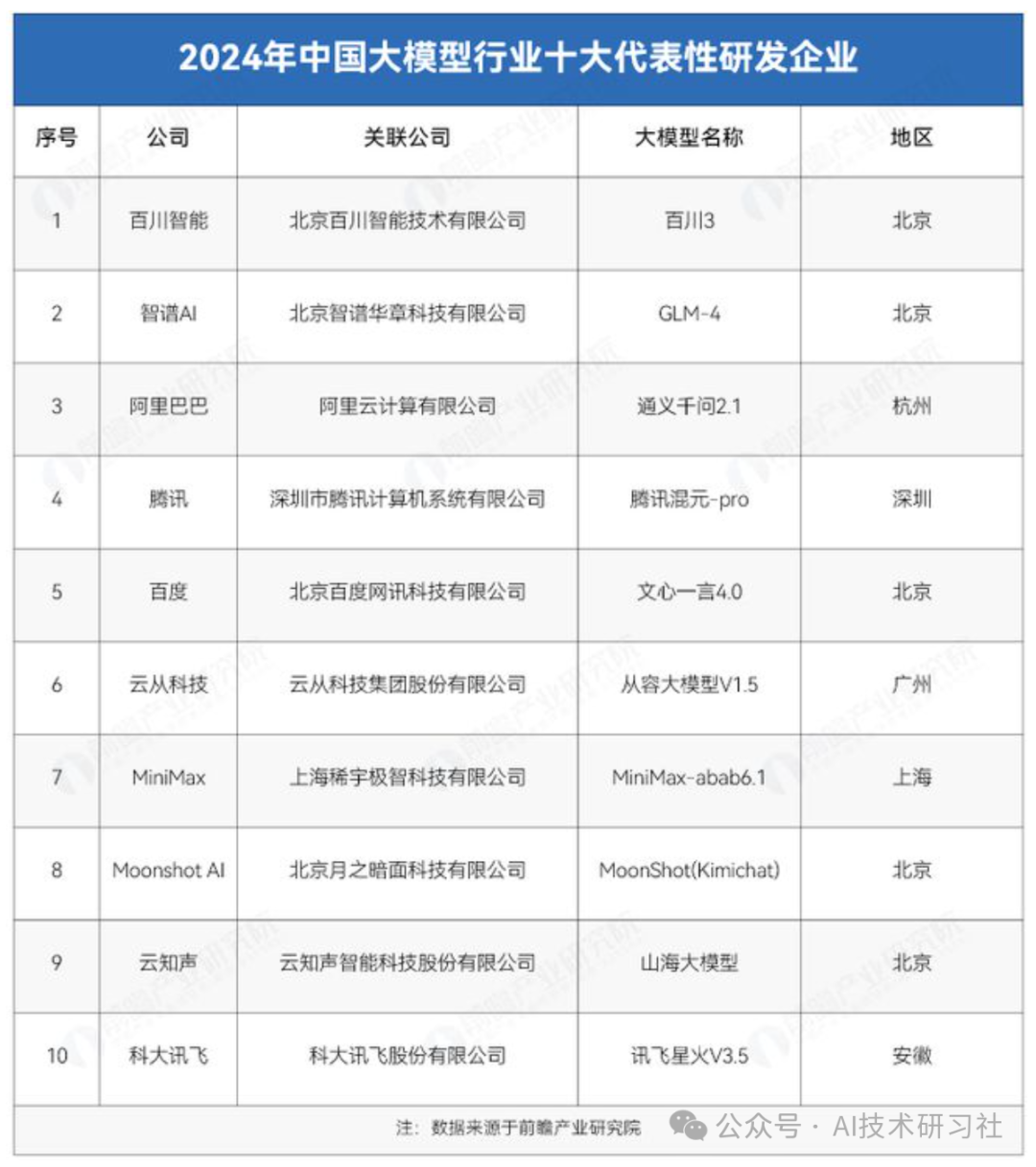
此外,根据SuperCLUE最新发布的大语言模型排行榜,国内大模型主要供应商如下:
下面回答一个最近用户提问比较多的问题,为什么国内外有这么多大模型了,DeepSeek还能这么火爆呢?
DeepSeek 之所以能在短时间内火爆出圈,主要得益于以下几点优势:
-
硬件优化创新:DeepSeek 针对国产 GPU 进行了优化,使得推理速度更快,成本更低。
-
高效的训练架构:采用创新的 MoE(Mixture of Experts)架构,在保证计算效率的同时,提高了模型的智能化水平。
-
针对中文的优化:相较于 GPT-4、Claude,DeepSeek 在中文 NLP 任务(如阅读理解、代码生成)上表现更优。
-
开放性与易部署:DeepSeek 提供了 Hugging Face 权重支持,并优化了量化技术,使得普通用户也能尝试本地部署。
AI 时代,我们的思维方式也需要改变。很多人还习惯于传统搜索,但真正的智能时代,应该是与AI 交谈,不断优化问题,直到得到最佳答案。
正如爱因斯坦所说:“我们不能用制造问题时的思维方式来解决问题。”
比如,很多人直接问 AI:❌ “帮我写个市场分析报告。”
但如果优化成:✅ “作为市场经理,我需要对 2024 年 Q4 中国新能源汽车市场做一个简要分析。请结合销量数据、用户评价趋势和政策影响,输出一篇 800 字报告。”
这样,AI 生成的内容不仅更精准,还能真正解决你的需求。
但是,当下很多用户在尝试使用DeepSeek的时候面临一个问题,许多用户反馈,在某些场景下,DeepSeek 访问不稳定,DeepSeek依然未能从服务崩溃中彻底走出来。

这也引出了一个关键问题:当 DeepSeek 不可用时,如何保证你的 AI 工作流不受影响?
解决方案 1:使用其他大模型
如果 DeepSeek 无法访问,可以切换到其他国内外大模型:
-
国内替代:Qwen、Baichuan、Yi-34B 等。
-
国外替代:GPT-4、Claude 2、Gemini 1.5(需要科学上网)。
解决方案 2:自己部署大模型
如果你想长期稳定地使用大模型,并希望掌握更大的自由度,可以考虑自部署。
自己部署大模型需要什么资源?
部署大模型的核心资源是 GPU,不同规模的模型对算力的需求不同,以下是大致的硬件和成本估算:

几种大模型部署方案
1. 本地部署(学习/实验)
如果你只是想体验大模型,学习 RAG(检索增强生成),可以尝试在 笔记本/台式机 上运行小型模型。
示例:
-
下载 Qwen 1.5B(Hugging Face)
-
使用
transformers加载模型 -
运行本地推理
2. 单机 3080/3090 运行 7B 级别模型
如果你有一块 24GB 显存的 3080/3090,可以运行 DeepSeek 7B、Llama 3-7B 级别的模型。
工具推荐:
-
llama.cpp(高效量化推理) -
AutoGPTQ(低显存推理优化)
3. 服务器部署 30B-70B 级别大模型(企业级方案)
如果需要更强的计算能力,建议使用 A100 / H100 服务器 进行部署。
应用场景:
-
自建 AI 助理
-
企业级 RAG(检索增强生成)
-
批量数据处理
接下来,我提供一个示例,利用DeepSeek 和 Qdrant 构建一个中文新闻 AI!

尤其是因为,尽管LLMs其规模和复杂性越来越大,但在构建英语之外的准确有效的语言 AI 仍然存在一系列挑战。在这种情况下,DeepSeek LLM 开始了一个长期的项目,以克服语言应用程序中的不准确之处。DeepSeek LLM 在中文方面表现出色,在这里,我们将了解它在从中文新闻数据集中获取新闻时的表现。
我们将利用 LlamaIndex、Qdrant 的 FastEmbed 和 Qdrant Vector Store 来开发一个应用程序,让我们可以通过强大的 RAG 来理解中文新闻。

DeepSeek LLM 是一种高级语言模型,它开发了不同的模型,包括 Base 和 Chat。它是在包含 2 万亿个英文和中文令牌的数据集上从头开始训练的。就大小而言,DeepSeek LLM 模型有两种:一种包含 70 亿个参数,另一种包含 670 亿个参数。
7B 模型使用多头注意力,而 67B 模型使用分组查询注意力。这些变体在与 Llama 2 模型相同的架构上运行,后者是一个自回归 transformer 解码器模型。
DeepSeek LLM 是一个致力于从长远角度推进开源大型语言模型的项目。然而,DeepSeek LLM 67B 在推理、数学、编码和理解等各个领域都优于 Llama 2 70B。与包括 GPT 3.5 在内的其他模型相比,DeepSeek LLM 在中文熟练度方面表现出色。
Qdrant 是一个用 Rust 编写的开源向量数据库和向量相似性搜索引擎,旨在通过先进和高性能的向量相似性搜索技术为下一代 AI 应用程序提供支持。其主要功能包括多语言支持,可实现各种数据类型的多功能性,以及适用于各种应用程序的过滤器。

FastEmbed 是一个轻量级、快速且准确的 Python 库,专为嵌入生成而构建,由 Qdrant 监督维护。它通过利用量化模型权重和 ONNX 运行时来实现效率和速度,从而避免了 PyTorch 依赖项的必要性。

LlamaIndex 是一个强大的框架,非常适合构建检索增强生成 (RAG) 应用程序。它有助于用于检索和合成的块的解耦,这是一个关键特征,因为检索的最佳表示可能与合成的不同。随着文档量的增加,LlamaIndex 通过确保更精确的结果来支持结构化检索,尤其是当查询仅与文档子集相关时。

由于 DeepSeek LLM 在中文语言熟练度方面表现出色,让我们使用 Retrieval Augmented Generation 构建一个中文新闻 AI。
首先,让我们安装所有依赖项。
pip install -q llama-index transformers datasetspip install -q llama-cpp-pythonpip install -q qdrant-clientpip install -q llama_hubpip install -q fastembed
在这里,我使用了这个数据集;它是一个多语言的新闻数据集。我选择了中文。加载数据集并将其保存到您的目录中。我们将使用 LlamaIndex 通过 SimpleDirectoryReader 读取数据。
from datasets import load_datasetdataset = load_dataset("intfloat/multilingual_cc_news", languages=["zh"], split="train")dataset.save_to_disk("Notebooks/dataset")
使用 LlamaIndex,从保存数据集的目录中加载数据。
from llama_index import SimpleDirectoryReaderdocuments = SimpleDirectoryReader("Notebooks/dataset").load_data()
使用 SentenceSplitter 将文档拆分为小块。在这里,我们需要维护文档和源文档索引之间的关系,以便它有助于注入文档元数据。
from llama_index.node_parser.text import SentenceSplittertext_parser = SentenceSplitter(chunk_size=1024,)text_chunks = []doc_idxs = []for doc_idx, doc in enumerate(documents):cur_text_chunks = text_parser.split_text(doc.text)text_chunks.extend(cur_text_chunks)doc_idxs.extend([doc_idx] * len(cur_text_chunks))
然后,我们将手动从文本块构建节点。
from llama_index.schema import TextNodenodes = []for idx, text_chunk in enumerate(text_chunks):node = TextNode(text=text_chunk,)src_doc = documents[doc_idxs[idx]]= src_doc.metadatanodes.append(node)
对于每个节点,我们将使用 FastEmbed Embedding 模型生成嵌入。
from llama_index.embeddings import FastEmbedEmbeddingembed_model = FastEmbedEmbedding(model_name="BAAI/bge-small-en-v1.5")for node in nodes:node_embedding = embed_model.get_text_embedding(node.get_content(metadata_mode="all"))node.embedding = node_embedding
现在,是时候使用 LlamaIndex 中的 HuggingFaceLLM 加载 DeepSeekLLM。在这里,我使用了聊天模型。
from llama_index.llms import HuggingFaceLLMllm = HuggingFaceLLM(context_window=4096,max_new_tokens=256,generate_kwargs={"temperature": 0.7, "do_sample": False},tokenizer_name="deepseek-ai/deepseek-llm-7b-chat",model_name="deepseek-ai/deepseek-llm-7b-chat",device_map="auto",stopping_ids=[50278, 50279, 50277, 1, 0],tokenizer_kwargs={"max_length": 4096},model_kwargs={"torch_dtype": torch.float16})
然后,我们将定义 ServiceContext,它由嵌入模型和大型语言模型组成。
from llama_index import ServiceContextservice_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
之后,我们将使用 Qdrant 向量数据库创建一个向量存储集合,并使用向量存储集合创建一个存储上下文。
import qdrant_clientfrom llama_index.vector_stores.qdrant import QdrantVectorStoreclient = qdrant_client.QdrantClient(location=":memory:")from llama_index.storage.storage_context import StorageContextfrom llama_index import (VectorStoreIndex,ServiceContext,SimpleDirectoryReader,)vector_store = QdrantVectorStore(client=client, collection_name="my_collection")vector_store.add(nodes)storage_context = StorageContext.from_defaults(vector_store=vector_store)
我们将文档、存储上下文和服务上下文传递到 VectorStoreIndex 中。
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context, service_context=service_context)我们将使用查询字符串生成查询嵌入,以构建检索管道。
query_str = "Can you give me news around IPhone?"query_embedding = embed_model.get_query_embedding(query_str)
然后,我们将构造一个 Vector Store 查询并查询 vector 数据库。
from llama_index.vector_stores import VectorStoreQueryquery_mode = "default"vector_store_query = VectorStoreQuery(query_embedding=query_embedding, similarity_top_k=2, mode=query_mode)query_result = vector_store.query(vector_store_query)print(query_result.nodes[0].get_content())

然后,我们将结果解析为一组节点。
from llama_index.schema import NodeWithScorefrom typing import Optionalnodes_with_scores = []for index, node in enumerate(query_result.nodes):score: Optional[float] = Noneif query_result.similarities is not None:score = query_result.similarities[index]nodes_with_scores.append(NodeWithScore(node=node, score=score))
现在,使用上述内容,我们将创建一个 retriever 类。
from llama_index import QueryBundlefrom llama_index.retrievers import BaseRetrieverfrom typing import Any, Listclass VectorDBRetriever(BaseRetriever):"""Retriever over a qdrant vector store."""def __init__(self,vector_store: QdrantVectorStore,embed_model: Any,query_mode: str = "default",similarity_top_k: int = 2) -> None:"""Init params."""self._vector_store = vector_storeself._embed_model = embed_modelself._query_mode = query_modeself._similarity_top_k = similarity_top_ksuper().__init__()def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:"""Retrieve."""query_embedding = embed_model.get_query_embedding(query_bundle.query_str)vector_store_query = VectorStoreQuery(query_embedding=query_embedding,similarity_top_k=self._similarity_top_k,mode=self._query_mode,)query_result = vector_store.query(vector_store_query)nodes_with_scores = []for index, node in enumerate(query_result.nodes):score: Optional[float] = Noneif query_result.similarities is not None:score = query_result.similarities[index]nodes_with_scores.append(NodeWithScore(node=node, score=score))return nodes_with_scoresretriever = VectorDBRetriever(vector_store, embed_model, query_mode="default", similarity_top_k=2)
然后,创建一个检索器查询引擎。
from llama_index.query_engine import RetrieverQueryEnginequery_engine = RetrieverQueryEngine.from_args(retriever, service_context=service_context)
最后,我们的检索器已准备好查询和聊天。让我们传递一个查询。
query_str = "世界有几大洲?"response = query_engine.query(query_str)print(str(response))
DeepSeek LLM 在回答问题方面表现得非常好,没有面临挑战。它的架构使其有别于其他模型,最令人印象深刻的方面是它利用直接偏好优化来增强模型的功能。它是一个中英文的微调和优化模型,我们从结果中观察到这种微调和优化的模型的性能如何。
结语:AI 时代,提问即生产力!
大模型正在重塑我们的学习和工作方式,不管你是选择使用 DeepSeek 还是自己部署大模型,最重要的是 学会与 AI 对话。
你的每一个问题,决定了 AI 给予你的答案。
那么,你是否尝试过自己部署大模型?你最想解决的 AI 应用场景是什么?欢迎在评论区交流你的想法!
(文:AI技术研习社)