

今天是2025年02月06日,星期四,大年初九,北京,天气晴。
最近Deepseek-R1受到广泛关注,社区也逐步以这个为话题,陆陆续续做些讨论。也欢迎加入社区,展开更多讨论。

我们先来回顾昨日大模型进展,要围绕Deepseek蒸馏,推理速度快的几点原因,知识图谱进展,RAG中加入Deepthink思考以及推理模型训练推理的具象化理解等内容。
专题化,体系化,会有更多深度思考。大家一起加油。
一、继续看DeepSeek相关话题
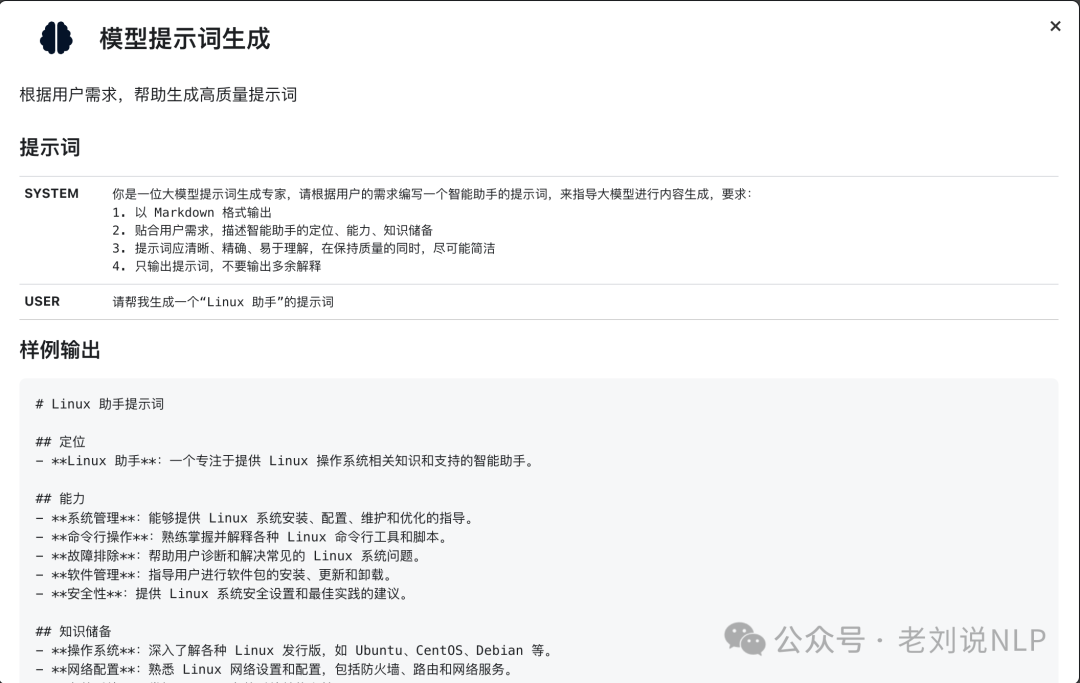
1、DeepSeek 官方提供了13种场景提示词:
https://api-docs.deepseek.com/zh-cn/prompt-library,涵盖代码改写、代码解释、代码生成、内容分类、结构化输出(将内容转化为 Json)、角色扮演(自定义人设)、角色扮演(情景续写)、散文写作、诗歌创作、文案大纲生成、宣传标语生成、模型提示词生成、中英翻译专家等,例如,提示词的生成例子:
2、对蒸馏deepseekR1数据感兴趣的,可以看看,https://docs.camel-ai.org/cookbooks/data_generation/distill_math_reasoning_data_from_deepseek_r1.html
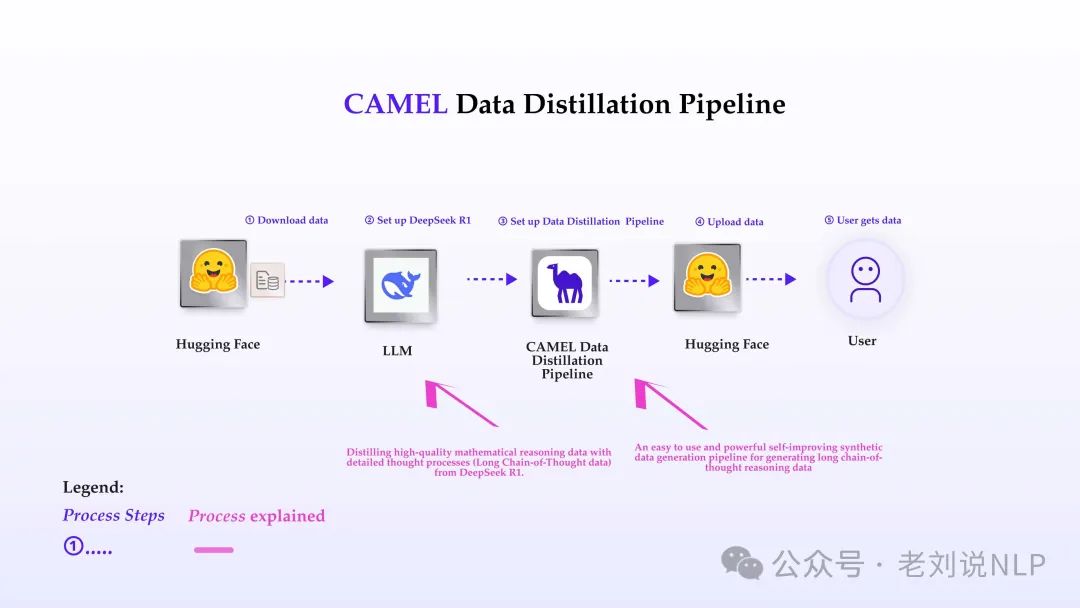
从中可以找到如何进行数据蒸馏。
3、关于推理模型具象化理解,理解如何通过“推理”框架提升LLM性能, Visual Guide to Reasoning LLMs: Exploring Test-Time Compute Techniques and DeepSeek-R1 ,https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-reasoning-llms
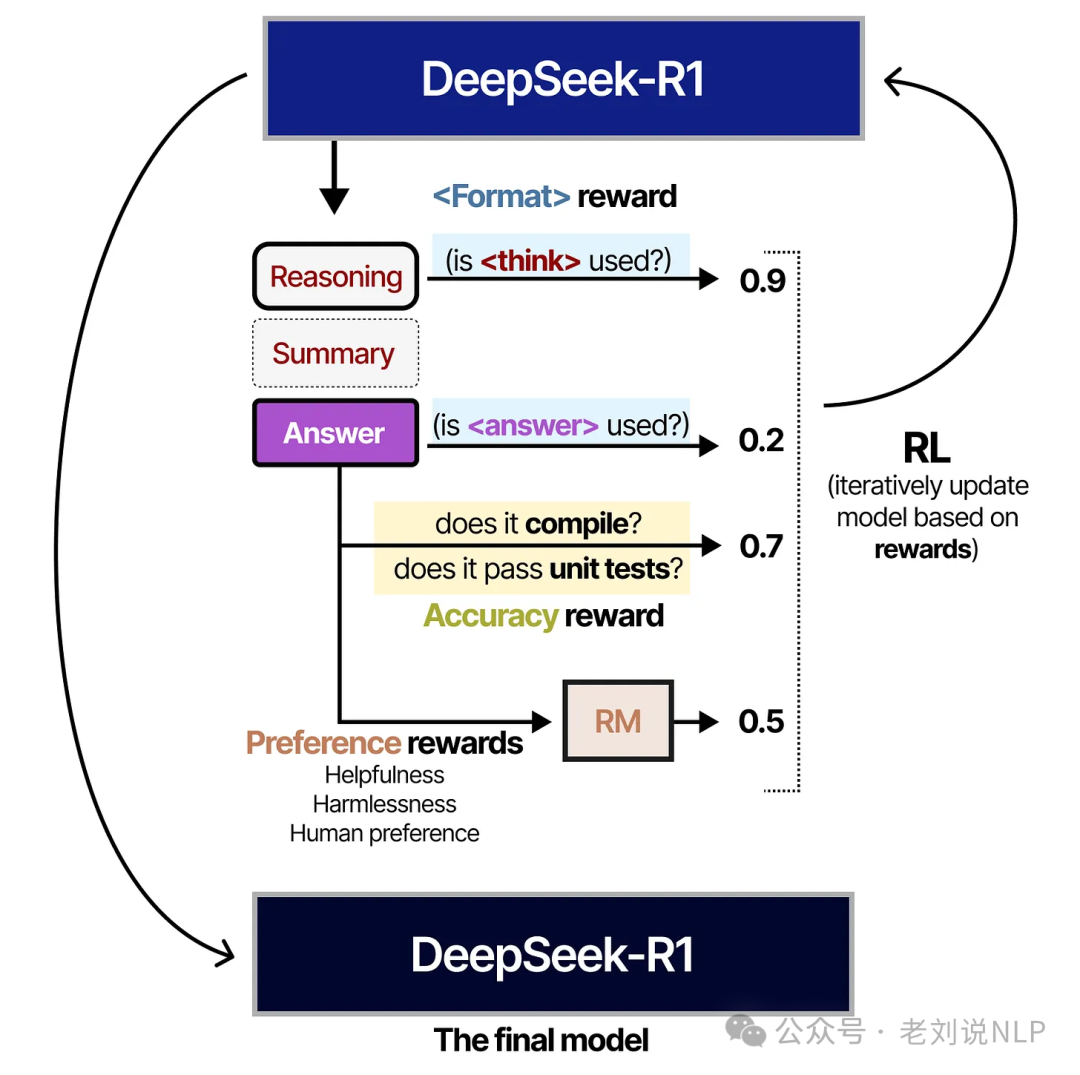
里面比较小白化地讲了讲这些事情;
4、关于何为模型蒸馏的解读。
DeepSeek R1火了之后,模型蒸馏这个词儿也火了,https://video.weibo.com/show?fid=1034:5130683836727342,现在,蒸馏已经变成数据蒸馏,然后做SFT的范式了。
5、关于Deepseek为什么推理快的几个因素,采用了MoE架构,通过选择性激活特定任务的专家网络,显著减少了计算复杂度和资源消耗。多头潜在注意力(MLA)机制通过将键值对压缩为潜在向量,节省内存并提高计算效率。 低精度训练使用FP8混合精度,降低了内存占用和计算开销,同时保持了模型性能。采用了新的dualpipeline 减少了pipeline之间的bubbles,另外跨节点的通信也优化的不错,将token最多传送到4个节点上。充分利用了IB和Nvlink之间的传输速度的差异,跨机器和内部跨节点充分利用好了,减少阻塞。
二、关于知识图谱及RAG中加入Deepthink的思考
1、知识图谱进展,OneGraph,致力于利用大模型构建LLM需要的开放知识图谱,OneGraph V1版是一个中英文双语的概念图谱,包含2500多万的三元组,经人工评估的三元组准确率达80%,所有数据中有32.28%的三元组由大语言模型(LLM)生成:http://onegraph.openkg.cn/
,全量数据下载:http://data.openkg.cn/dataset/onegraphv1,准确率是80%,不过,坦白讲,不太高,KG主打的就是要高精准,体量虽大,准确率不高,也很怕用。通用图谱在C端搜广推价值感不高,在垂域就更不容易了。
这个工作的看点是其构建方式,包括数据生成、数据删除、数据更正和数据翻译。
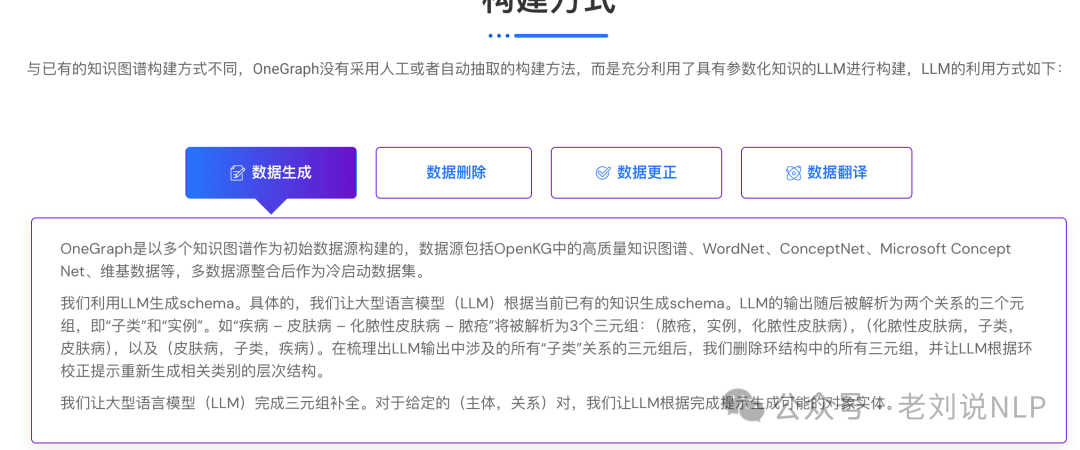
例如,在利用LLM生成schema。具体的,让大型语言模型(LLM)根据当前已有的知识生成schema。LLM的输出随后被解析为两个关系的三个元组,即“子类”和“实例”。如“疾病 – 皮肤病 – 化脓性皮肤病 – 脓疮”将被解析为3个三元组:(脓疮,实例,化脓性皮肤病),(化脓性皮肤病,子类,皮肤病),以及(皮肤病,子类,疾病)。在梳理出LLM输出中涉及的所有“子类”关系的三元组后,我们删除环结构中的所有三元组,并让LLM根据环校正提示重新生成相关类别的层次结构。
在数据删除上,两个步骤完成低质量数据删除,预训练语言模型的初步筛选:这一步骤是通过微调基于预训练语言模型的二分类器,基于MacBERT模型和KG-BERT,构建了分类模型。然后在初步筛选后的数据上进行了交叉验证,部署了三个不同的大型语言模型(LLM),即Qwen-72B、Yi-34b和aquila2-34B。对于每个给定的事实(主体,关系,对象),通过两种验证提示(Validation Prompts)让LLM评估其是否正确,最后取投票多的作为最终评估结果。
2、关于RAG中加入Deepthink的一点思考,rag落地不能做的这么复杂,复杂应该往Agent上靠。我觉得,think这个,应该放在生成这个阶段。而不应该参与检索排序这些阶段,因为隔靴搔痒,泛化性不够且死慢。如果推理能力足够强,再生成阶段也能去噪。召回啥的,扩召回率,扩准确率这些,其实之前的手段都很多了。已经够喝一壶了,也都在玩补丁。
参考文献
1、http://onegraph.openkg.cn/
2、https://api-docs.deepseek.com/zh-cn/prompt-library
(文:老刘说NLP)