

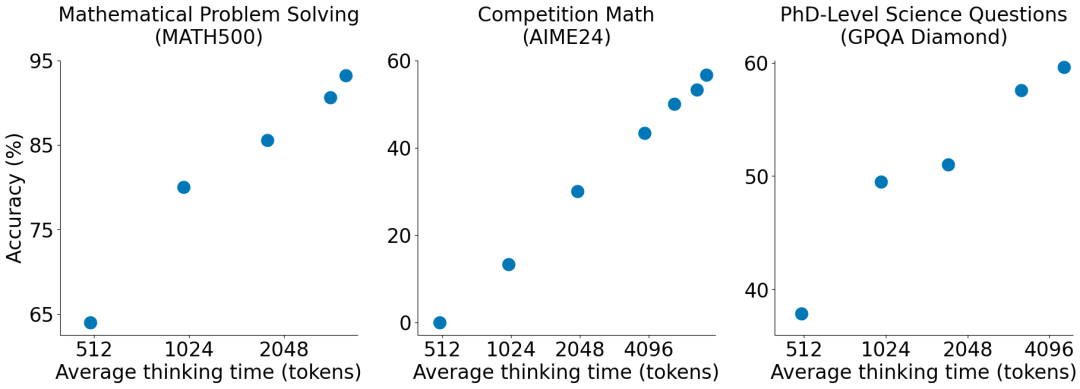
S1 这个模型用 6 美元成本,大概一千条数据获得了跟 o1-preview 相似的结果,而且观测到了跟 O1 和 R1 类似的 scaling 表现。
可能揭示了 o3-mini-low 和 o3-mini-high 是如何从 O3 蒸馏出来的,他们的方式是当 LLM 尝试用 “” 停止思考时,他们会强迫它继续思考,将其替换为 “Wait” 。
为了缩短或延长思考时间。它会开始质疑和反复核对答案。o3-mini-low 对比 o3-mini-high 可能也是用了这个方法蒸馏的 O3。他们可能训练了 3 个模型,每个模型有不同的平均思考时间。最终,这种行为训练到模型权重中,S1这个底模用的是Qwen2.5-32B-Instruct。

参考文献:
[1] 论文地址:https://arxiv.org/abs/2501.19393
[2] https://github.com/simplescaling/s1
[3] https://huggingface.co/simplescaling/s1-32B
(文:NLP工程化)