

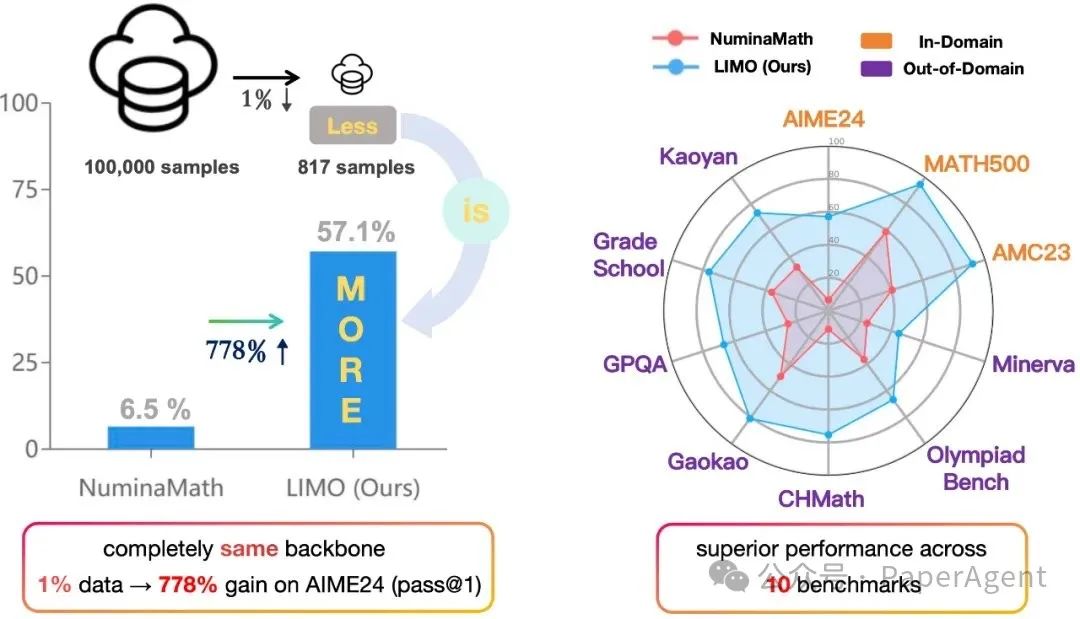
复杂推理能力一直是大型语言模型(LLM)面临的挑战之一。LIMO(代码数据模型已全开源)提出了一种新的假设:“Less-Is-More Reasoning Hypothesis”(LIMO假设),即在预训练阶段已经全面编码了领域知识的基础模型中,复杂的推理能力可以通过最少但精心策划的认知过程演示来激发。
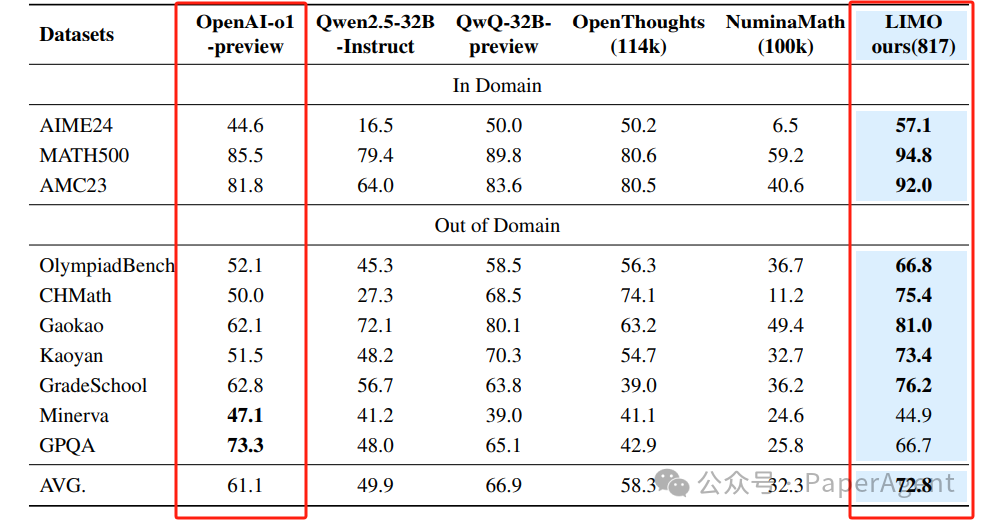
LIMO(817 个样本)的表现优于o1-preview、QwQ-32B-Preview
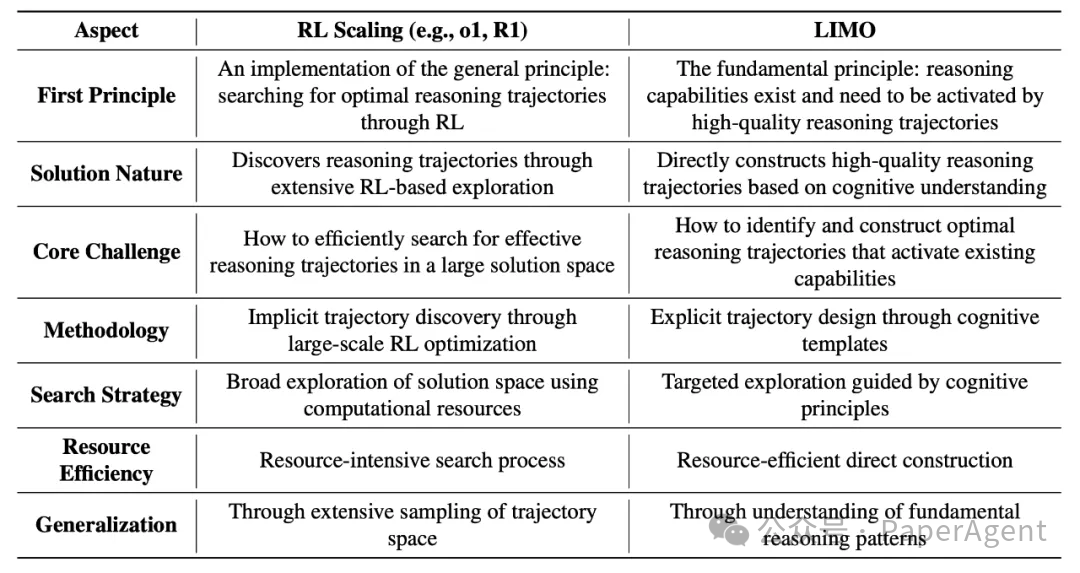
LIMO vs RL Scaling:如果LLM本身已经具备推理能力,LIMO只是在激活它们的推理能力;强化学习扩展(DeepSeek R1/OpenAI o1)则通过大规模的搜索和优化来发现推理路径。
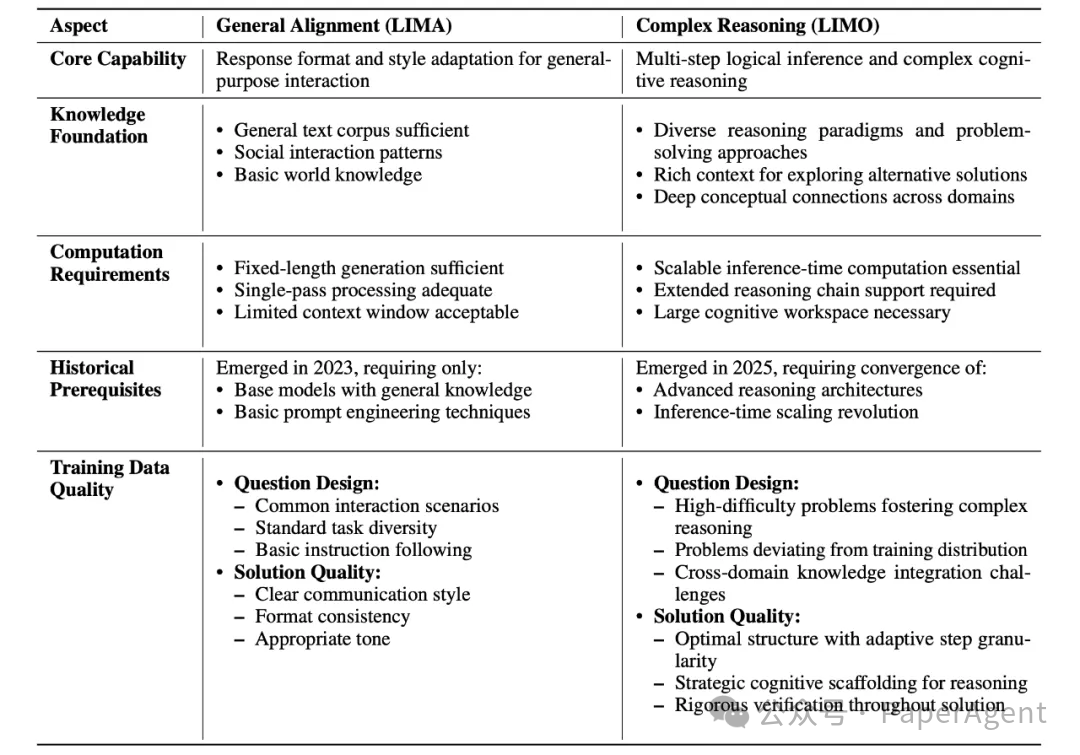
从LIMA到LIMO:Less is More的原则扩展到了数学领域!两个关键点:LLM已经在海量数学数据上进行了训练。推理链的质量比训练数据的数量更重要。
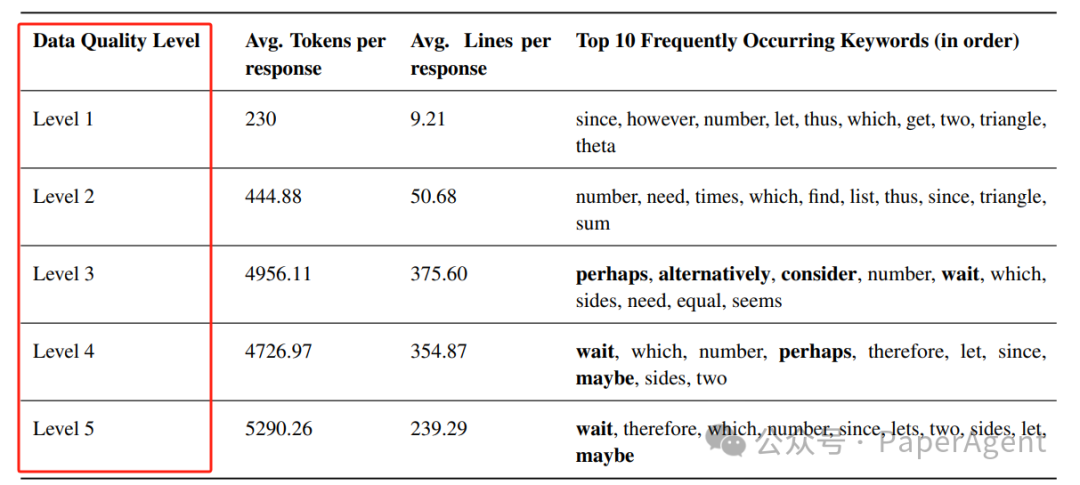
不同数据质量下训练的模型的统计分析
在数学上比较 Qwen2.5、DeepSeek-R1 和 LIMO:LIMO 凭借深度自我反思和更长的推理链脱颖而出,为复杂方程式分配了额外的计算。

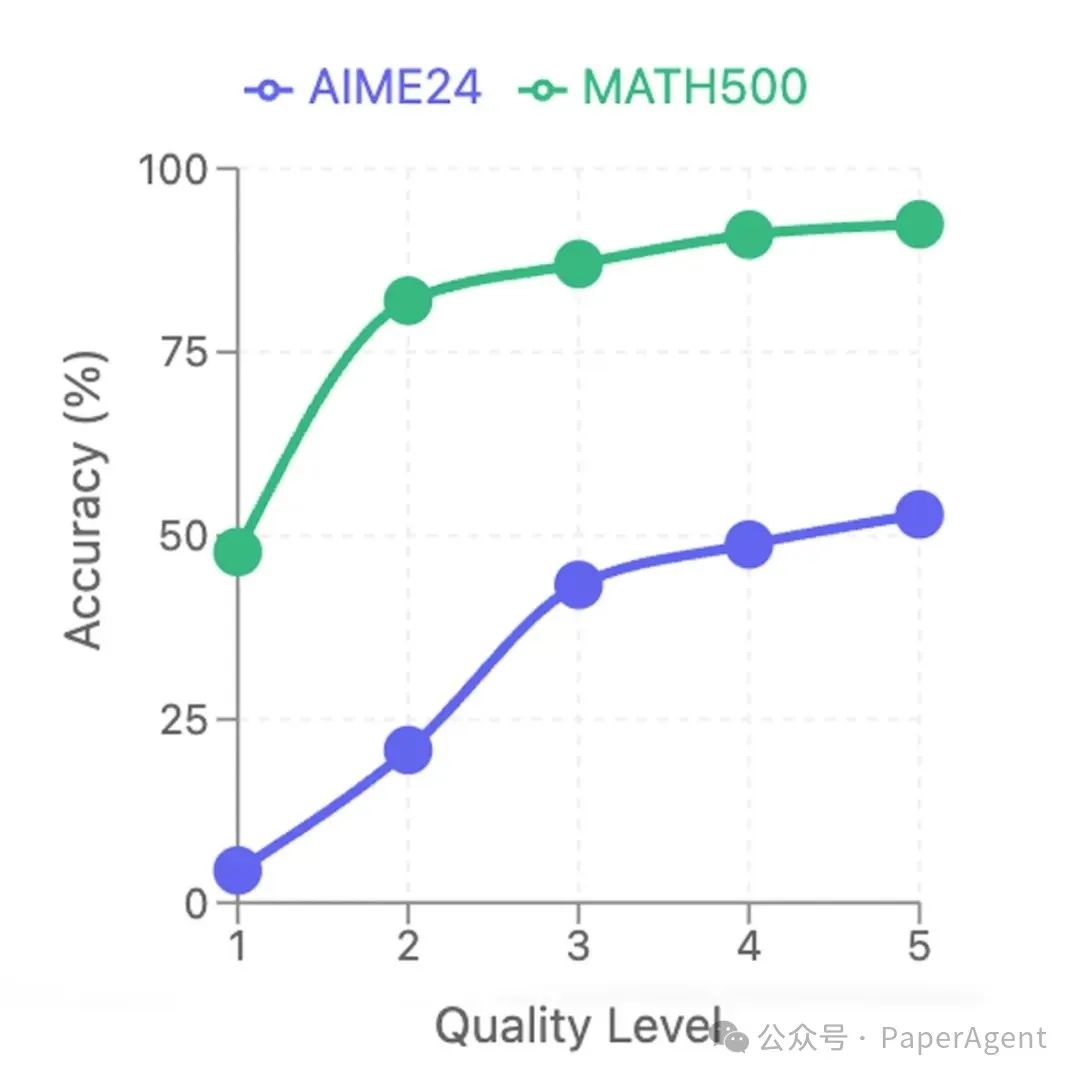
推理链质量的影响
推理链的质量对模型性能有显著影响。从基础(L1)到专家(L5)级别的解决方案测试表明,推理链的质量可能比想象的更为关键。
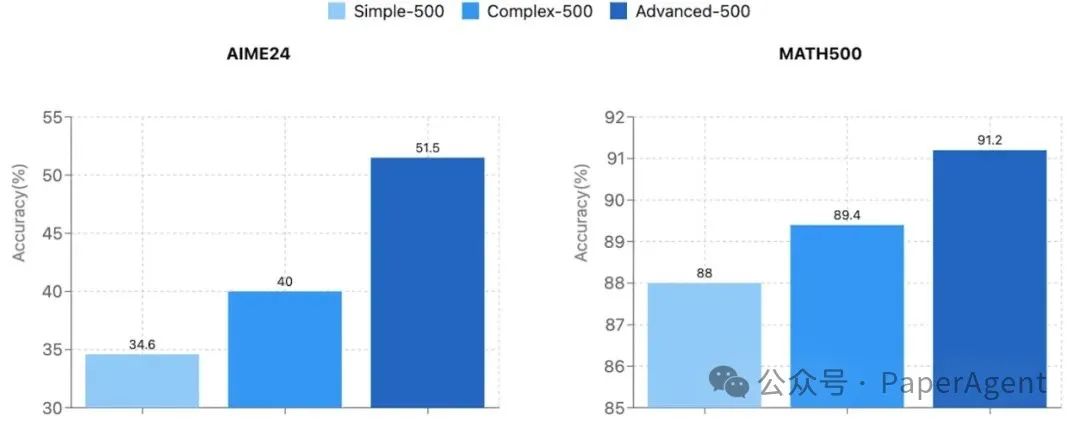
问题质量的影响
在MATH/AIME基准测试中,使用500个高级问题进行训练的表现优于使用500个简单问题。问题的选择质量也很重要!
https://arxiv.org/pdf/2502.03387LIMO: Less is More for Reasoninghttps://github.com/GAIR-NLP/LIMO
(文:PaperAgent)