
Vectara 公司近期发布了一份 AI 大语言模型幻觉评测榜单,对当前主流 AI 模型在文本摘要任务中产生幻觉的情况进行了系统评测。该榜单使用 Vectara 自研的 HHEM-2.1 评测模型,通过让 AI 模型对 831 篇短文进行摘要来测试其产生幻觉的概率。
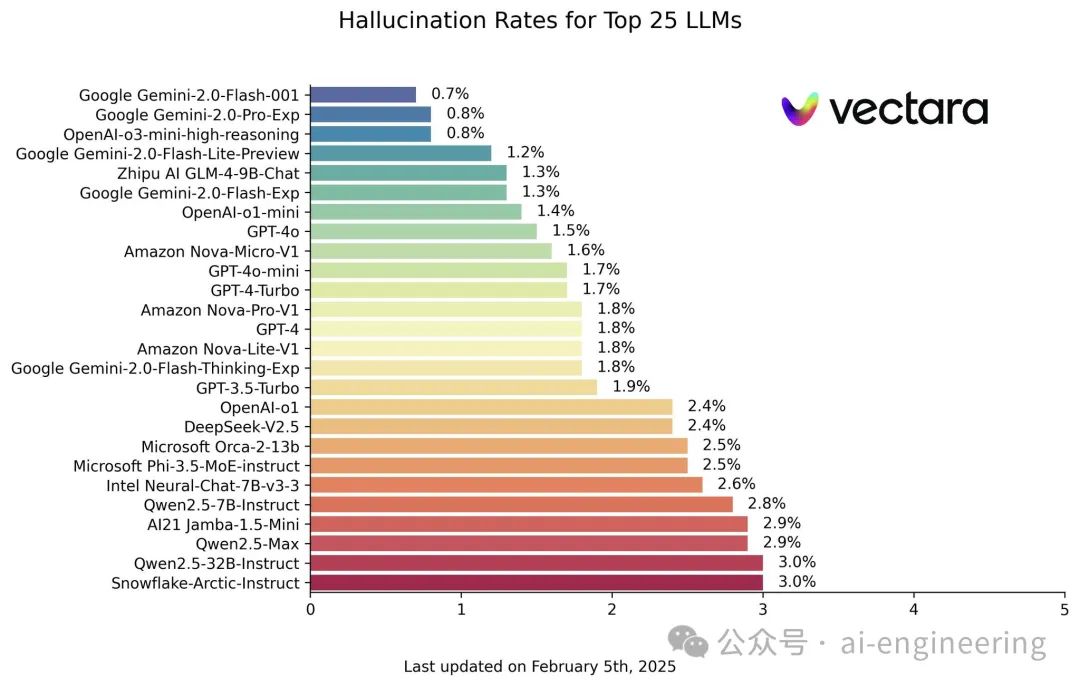
在最新榜单中,Google 的Gemini 2.0 Flash 以0.7%的幻觉率位居榜首,其次是 Gemini 2.0 Pro 和OpenAI 的o3-mini-high-reasoning 模型,幻觉率均为 0.8%。值得注意的是,GPT-4 系列模型表现也相当出色,幻觉率在 1.5%-1.7%之间。国产模型智谱glm-9b表现不错,幻觉率为1.3%,Qwen幻觉率较高,达到了2.8%-3.0%之间,deepseek 最新模型v3和r1的评测,后续可能会加入。
评测采用了严格的方法论:所有模型都使用温度参数为 0,确保输出的稳定性;同时设置了答案率和平均摘要长度等指标,避免模型通过简单复制或过短回答来取得高分。这份榜单将定期更新,为用户选择和评估 AI 模型提供了重要参考。
该评测的意义在于首次建立了一个可量化、可复现的 AI 模型幻觉评估标准。虽然仅限于文本摘要任务,但这种评估方法对于理解和改进 AI 模型的真实表现具有重要价值。
关注公众号发送消息“进群”入群讨论。
(文:AI工程化)
这次评测结果出来得太及时了!国产模型的表现让人眼前一亮,GPT系列幻觉率还不到两百分比?真是 finally hit the nail on the head!