
今天是2025年02月10日,星期一,北京,天气晴。
我们这周还是来跟进下如何增强大模型推理能力这个话题,从数据、复现等几个角度出发。
首先,我们先看其几种范式,然后,进一步看,现在直接使用蒸馏微调地方式进行实现推理能增强,包括现有的一些数据集以及工具。
专题化,体系化,会有更多深度思考。大家一起加油。
一、先看增强模型推理能力的四种范式
目前,增强大模型推理能力有四种基本范式,包括推理时间扩展、纯强化学习(RL)、监督微调(SFT)加上RL等,关于这块,可以进一步看:https://magazine.sebastianraschka.com/p/understanding-reasoning-llms。
1、推理时间扩展 ,一种无需训练或以其他方式修改底层模型即可提高推理能力的技术。推理时间扩展不需要额外的训练,但会增加推理成本,随着用户数量或查询量的增加,大规模部署的成本会更高。不过,对于已经很强大的模型来说,提高性能仍然是明智之举。o1可能利用了推理时间扩展,这有助于解释为什么与DeepSeek-R1相比,它在每token基础上的成本更高。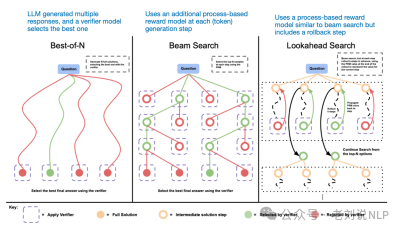
2、纯强化学习(RL) ,如DeepSeek-R1-Zero,它表明推理可以作为一种学习行为出现,而无需监督微调。纯RL对于研究目的来说很有趣,因为它提供了对推理作为一种新兴行为的洞察。然而,在实际模型开发中,RL+SFT是首选方法,因为它可以产生更强大的推理模型。可能o1也是使用RL+SFT进行训练的,即o1从比DeepSeek-R1更弱、更小的基础模型开始,但通过RL+SFT和推理时间缩放进行了补偿。
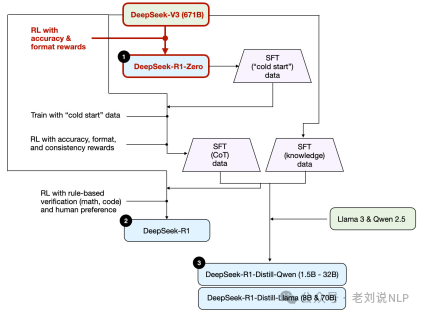
3、监督微调(SFT)加上RL,这产生了DeepSeek的旗舰推理模型DeepSeek-R1。RL+SFT是构建高性能推理模型的关键方法。DeepSeek-R1是一个很好的案例,展示了如何做到这一点。
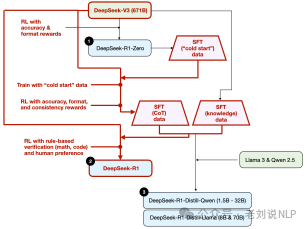
4、蒸馏(distillation) ,一种很捷径的方法,尤其是用于创建更小、更高效的模型。然而,蒸馏的局限性在于它不会推动创新或产生下一代推理模型。例如,蒸馏总是依赖于现有的、更强大的模型来生成监督微调(SFT)数据。
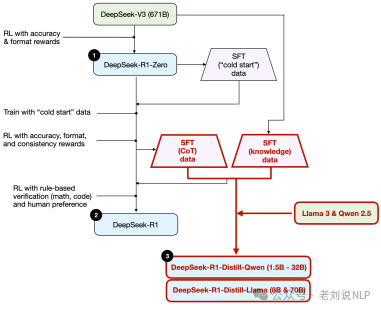
所以可以看到,最简单的方式其实是推理时间扩展或者蒸馏,但是这个其实的成功率,其实还是依赖于基座模型本身。
例如,小模型直接进行RL未必奏效,将DeepSeek-R1-Zero中相同的纯RL方法直接应用于Qwen-32B,测试纯RL是否可以在比DeepSeek-R1-Zero小得多的模型中诱导推理能力。结果表明,对于较小的模型,蒸馏比纯强化学习更有效。
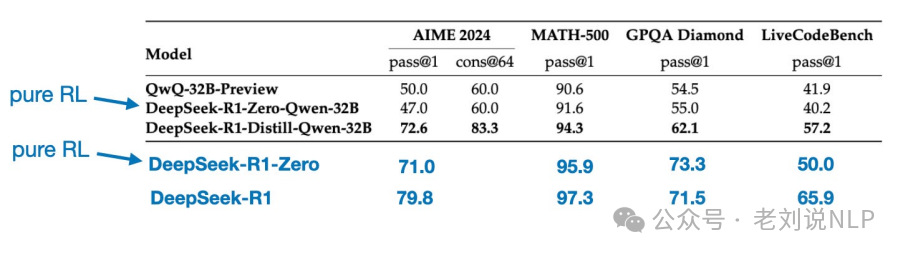
所以,单靠强化学习可能不足以在这种规模的模型中产生强大的推理能力,而使用高质量推理数据进行SFT在使用小模型时可能是一种更有效的策略。https://arxiv.org/abs/2501.12948
当然,我们也可以进一步看接下来的方向:将RL+SFT(方法3)与推理时间扩展(方法1)相结合。这很可能是OpenAIo1正在做的事情,只不过它可能基于比DeepSeek-R1更弱的基础模型,这解释了为什么DeepSeek-R1表现如此出色,同时在推理时间上保持相对便宜。
二、再看直接通过模型蒸馏微调方式提升推理能力
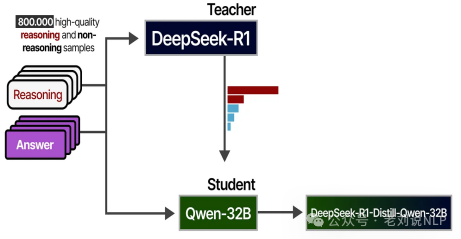
关于模型蒸馏,例如使用DeepSeek-R1为金融数据集生成推理轨迹(例如,股票价格预测、风险分析),并将这些知识蒸馏成一个金融领域知识较小模型finance-LLM,这块可以参考rehttps://medium.com/@prabhudev.guntur/how-to-distill-deepseek-r1-a-comprehensive-guide-c8ba04e2c28c
那么,蒸馏有几种方法,每种方法都有各自的优点:
一种是数据蒸馏,在数据蒸馏中,教师模型生成合成数据或伪标签,然后用于训练学生模型。这种方法可以应用于广泛的任务,即使是那些 logits 信息量较少的任务(例如开放式推理任务)。
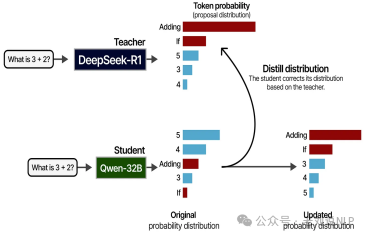
一种是Logits蒸馏,Logits 是应用 softmax 函数之前神经网络的原始输出分数。在 logits蒸馏中,学生模型经过训练以匹配教师的 logits,而不仅仅是最终预测。这种方法保留了更多关于教师信心水平和决策过程的信息。
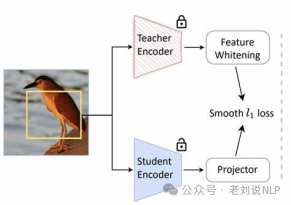
一种是特征蒸馏,特征蒸馏将知识从教师模型的中间层转移到学生。通过对齐两个模型的隐藏表示,学生可以学习更丰富、更抽象的特征。
而蒸馏数据方面,这个必定是要回答的,目前已经有许多数据集,可以看一个具体的数据样例,来自dolphin-r1中用deepseek合成数据集。

目前开源的数据主要有如下:
1、Magpie-Reasoning-V2数据集,其中包含DeepSeek-R1生成的250K思路链推理样本,这些示例涵盖了数学推理、编码和一般问题解决等各种任务。https://huggingface.co/datasets/Magpie-Align/Magpie-Reasoning-V2-250K-CoT-Deepseek-R1-Llama-70B
2、Dolphin-R1,包含80万个样本的数据集,其中的数据来自DeepSeek-R1和Geminiflash的生成结果,同时还有来自Dolphinchat的20万个样本。https://huggingface.co/datasets/cognitivecomputations/dolphin-r1,https://modelscope.cn/datasets/AI-ModelScope/dolphin-r1

3、R1-Distill-SFT,有17000个样本,目的是创建数据以支持Open-R1项目,https://huggingface.co/datasets/ServiceNow-AI/,https://modelscope.cn/datasets/ServiceNow-AI/R1-Distill-SFT
4、NuminaMath-TIR,工具类数据集。 https://www.modelscope.cn/datasets/AI-MO/NuminaMath-TIR,
5、NuminaMath-CoT,大约86万道数学题,每个解题过程都以“思维链”方式呈现。 https://www.modelscope.cn/datasets/AI-MO/NuminaMath-CoT
6、BAAI-TACO,代码生成的基准,包含26443个问题。 https://modelscope.cn/datasets/BAAI/TACO
7、OpenThoughts-114k,开放的合成推理数据集,包含11.4万个高质量样本,涵盖数学、科学、代码和谜题等领域。 https://modelscope.cn/datasets/open-thoughts/OpenThoughts-114k
8、Bespoke-Stratos-17k,对伯克利Sky-T1数据的复制,使用DeepSeek-R1创建了一个包含问题、推理过程和答案的数据集。 https://modelscope.cn/datasets/bespokelabs/Bespoke-Stratos-17k
9、clevr_cogen_a_train,R1蒸馏视觉推理数据集。 https://huggingface.co/datasets/leonardPKU/clevr_cogen_a_train)-AR1-distilledvisualreasoningdataset.
10、S1k,训练S1模型的数据集,https://huggingface.co/datasets/simplescaling/s1K
在训练方式上,直接可以使用swift或者llamafactory(https://llamafactory.readthedocs.io/zh-cn/latest/)这类工具进行微调。
对应的显存要求:
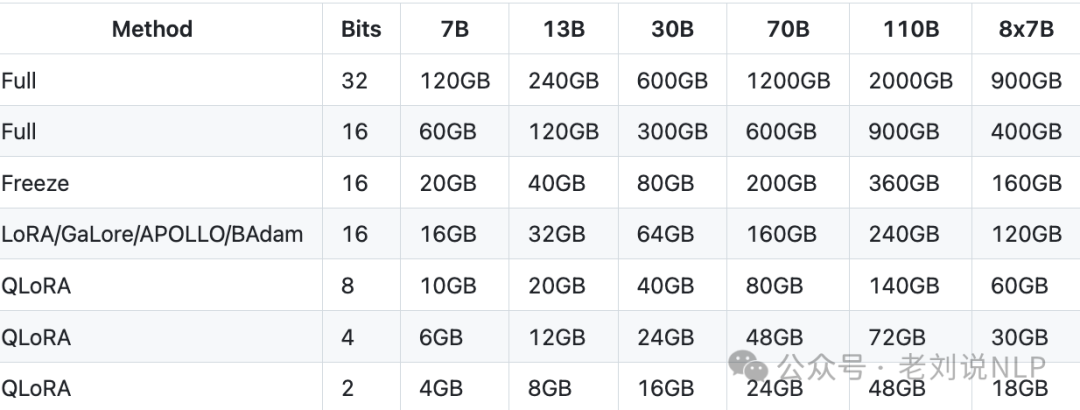
然后,在结果方面,就能看到效果,微调的一些结果如下:

总结
本文主要回顾了增强大模型推理能力的四种范式以及使用蒸馏微调方式进行推理能力蒸馏的数据集、工具以及一个例子。
趁热打铁,然后深入进去,能更好的理解技术本身。
参考文献
1、ref:https://medium.com/@prabhudev.guntur/how-to-distill-deepseek-r1-a-comprehensive-guide-c8ba04e2c28c
2、https://magazine.sebastianraschka.com/p/understanding-reasoning-llms。
3、https://github.com/hiyouga/LLaMA-Factory
(文:老刘说NLP)