
LLaMA-Factory Day0 支持了 GLM-4.1V-Thinking 模型的微调和推理
LLaMA-Factory Day0发布支持GLM-4.1V-Thinking模型微调和推理的代码更新及视频教程
LLaMA-Factory Day0发布支持GLM-4.1V-Thinking模型微调和推理的代码更新及视频教程

文章介绍了6个Python项目及其简介,包括olmOCR、AstrBot、vision-agent、fastrtc、DiffSynth-Studio和LLaMA-Factory,涵盖了PDF处理、聊天机器人、视觉任务生成、实时通信、视频图像合成等多个领域。

文章介绍了增强大模型推理能力的四种范式,并探讨了使用蒸馏微调方式进行数据集和工具的选择。强调了监督微调(SFT)加上强化学习(RL)的重要性,同时提到了不同蒸馏方法及其应用。
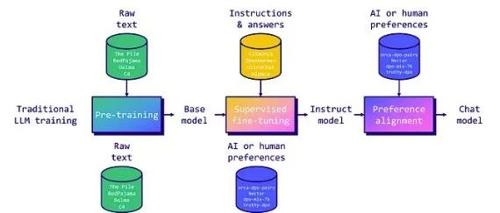
文章介绍了在现有预训练模型基础上进行微调的方法,包括监督式微调、偏好对齐方法(如基于人类反馈的强化学习和直接偏好优化)、单体偏好优化等,强调了其在提升模型实用性和适应特定任务中的优势。
