
今天是2025年02月28日,星期五,北京,天气晴。
今天是2025年的最后一天,过去1/6。
我们今天继续看RAG进展,看推理模型用于RAG的两个思路。
另一个看看将R1推理路径用于多模态模型的一个经典工作R1-Onevision,其中提供的图像文本化、形式化描述语言值得借鉴,实现范式也可以参考,挺好的。
专题化,体系化,会有更多深度思考。大家一起加油。
一、推理模型用于RAG的两个思路
关于这块,我们来看两个有趣的话题。
1、在法律领域用deepseek+RAG的一个实验
博客https://blog.skypilot.co/deepseek-rag/,使用pile-of-law数据集的一个子集,专注于法律建议。使用ChromaDB作为向量存储,Qwen2嵌入进行检索,DeepSeek R1进行最终答案生成。这个场景的意义是,法律领域对准确性和可追溯性要求高,RAG系统能够提供高相关性的文档检索和丰富的文本生成。
其提到的三个建议。
不要用DeepSeek R1进行检索,DeepSeek R1在生成嵌入方面表现不佳,不如专门的嵌入模型(如Alibaba-NLP/gte-Qwen2-7B-instruct),这个底层逻辑是因为DeepSeek-R1大而发散,一个是速度慢,另一个是幻觉过多导致离题,无法与向量数据库中的内容匹配。这个的确是,但有些任务却需要这种发散。
但是可以用DeepSeek R1进行生成,DeepSeek R1在生成方面表现出色,具有强大的推理能力,能够减少幻觉并清晰引用相关段落。
其三,需要精心设计的提示来鼓励文档引用、防止幻觉,并以用户友好的方式组织答案,所以这块,面向业务做prompt优化其实很必要。
2、Think过程用于RAG重的检索
另一个是,《Rank1: Test-Time Compute for Reranking in Information Retrieval》,https://arxiv.org/pdf/2502.18418,代码放在https://github.com/orionw/rank1,提出利用测试时计算的推理重排序模型RANK1,以提高小型模型的性能,通过从大型推理模型的推理链中进行蒸馏。
具体看几个点:
在数据方面,使用MS MARCO数据集生成超过635,000个R1推理链的示例。具体的,收集了超过600,000个R1推理轨迹的例子,这些例子来自MS MARCO查询和段落.
蒸馏的prompt如下:

蒸馏的数据样例如下:

然后,使用kluster.ai API服务从R1中生成数据,包括MS MARCO的正例、Tevatron2的负例、mT5-13B的排名1-5的硬负例和排名5-10的硬负例。
在数据配比方面,进行数据混合和质量过滤,通过对数据进行多次筛选和过滤,最终得到高质量的训练集,包含386,336个样本。
下面这个分布图有意思,由R1生成的推理链的词长度分布。它略微右偏,但总体呈正态分布。请注意,在预测为相关与不相关的段落之间,分布没有明显差异。
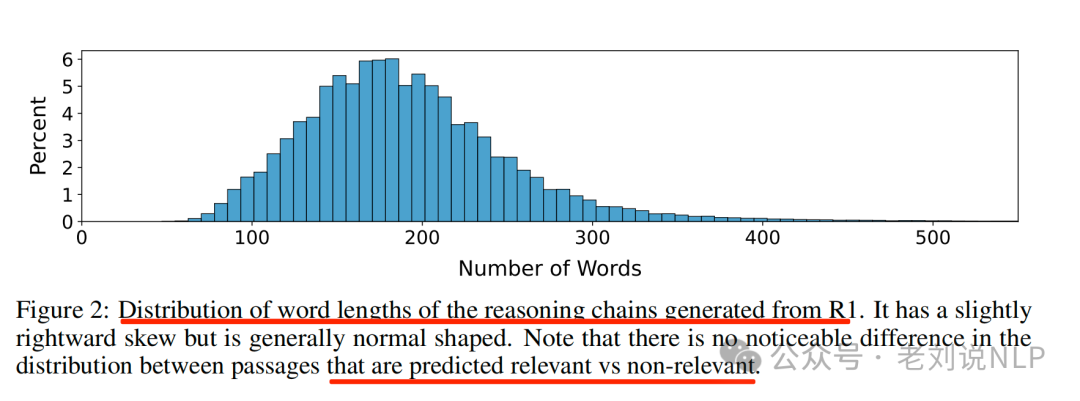
具体过滤步骤包括:使用所有数据进行初步平衡,但发现效果不佳->基于最确定的标签(如MS MARCO(m https://huggingface.co/datasets/Tevatron/msmarco-passage-aug)的正例和Tevatron的负例)进行过滤->使用一个模型对数据进行自过滤,去除约10%的噪声数据。最终保留了所有MS MARCO正例和自过滤后的负例,形成386,336个高质量的训练样本。
在模型训练方面,使用Qwen 2.5系列的三个模型(7B、14B和32B参数模型)进行训练。采用LoRA进行微调,得到重排模型包括Rank1-7B、Rank1-14B和Rank1-32B。使用的框架是LLaMA-Factory。
这里有个发现,基础模型(非指令调优版本)的表现优于指令调优版本,因此从基础版本开始训练。
但是,这种工作其实很慢,不一定能用,但是呢,也点出一个点。就是,使用测试时计算需要花费比非测试时计算模型更多的计算资源这一事实无法改变。尽管有额外的计算使用,但是,在用户场景侧,用户愿意为了高质量的搜索结果等待更长时间,正如谷歌和OpenAI的Deep Research产品的流行。
这一点,昨日看到一个文章,说的很好,来自:https://mp.weixin.qq.com/s/-pPhHDi2nz8hp5R3Lm_mww:
这种“推理时计算”理念,以及专注于推理的模型,都在引导用户接受一种“延迟满足”的观念:用更长的等待时间,换取更高质量、更具实用性的结果。 就像著名的斯坦福棉花糖实验,那些能够抵制立即吃掉一个棉花糖的诱惑,从而获得稍后两个棉花糖的孩子,往往能取得更好的长期成就。Deepseek-r1 进一步巩固了这种用户体验,无论你是否喜欢,大多数用户都已经默默接受了这一点。这标志着与传统搜索需求的重大背离。过去,如果你的解决方案无法在 200 毫秒内给出响应,那几乎等同于失败。但在 2025 年,经验丰富的搜索开发者和 RAG 工程师们,将 top-1 精确率和召回率置于延迟之前。用户已经习惯了更长的处理时间:只要他们能看到系统在努力<thinking>。
所以,这个外围其实也在改变,不单单是技术层面。
二、多模态R1的一个典型工作R1-Onevision
我们继续来看一个比较有有代表性的工作,将R1这种策略用在多模态上, 《R1-Onevision:Open-Source Multimodal Large Language Model with Reasoning Ability》这个工作,还是做的R1系列用于多模态范畴。

地址在:https://github.com/Fancy-MLLM/R1-Onevision,https://huggingface.co/datasets/Fancy-MLLM/R1-Onevision,https://huggingface.co/datasets/Fancy-MLLM/R1-OneVision-Bench,https://huggingface.co/Fancy-MLLM/R1-OneVision-7B,https://huggingface.co/spaces/Fancy-MLLM/R1-OneVision,https://paperswithcode.com/dataset/r1-onevision
我们来看看一些实现细节,可以看https://yangyi-vai.notion.site/r1-onevision,技术路线图如下: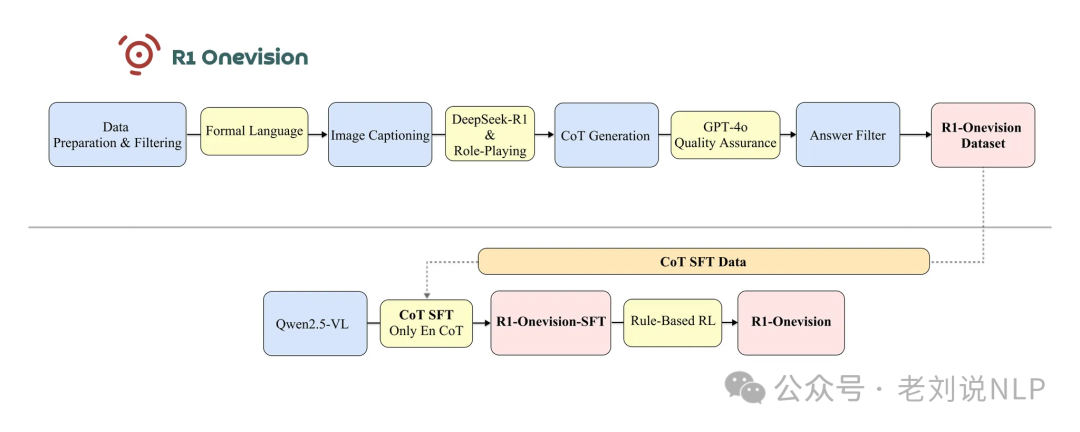
1、R1-Onevision数据集构建
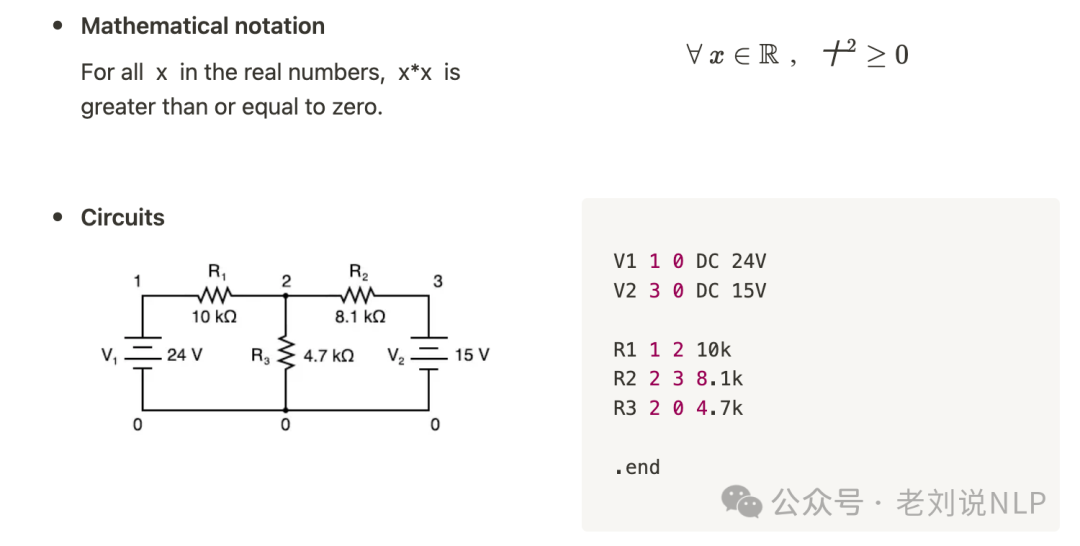
通过构建用于表达图像的形式语言来弥合视觉推理和文本推理之间的差距,核心就是表示图像,例如,表示数学公式和电路图:
又如表示乐谱:

所以呢,基于这个原则,可以建设数据集。
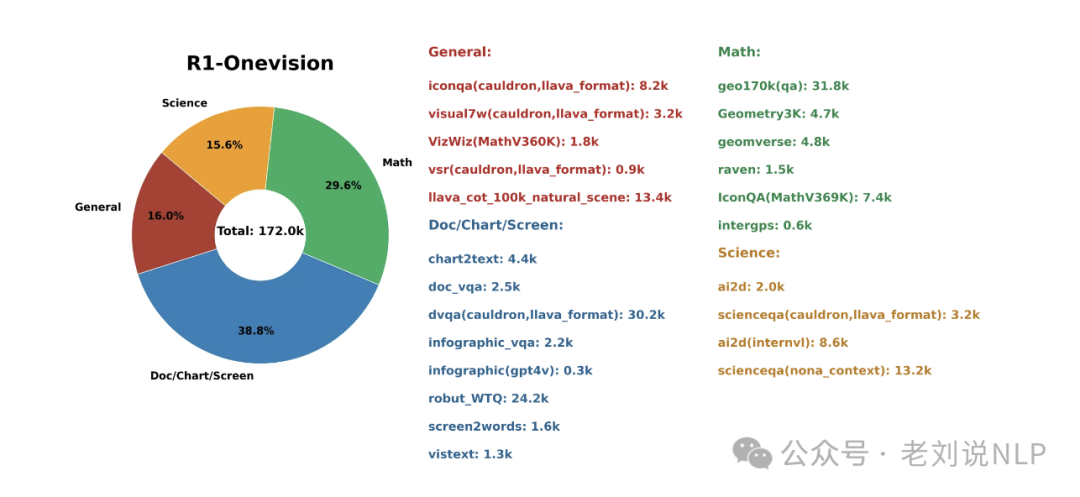
对于R1-Onevision数据集,整理了一个多样化的高质量数据集集合,涵盖了自然图像、光学字符识别(OCR)、图表、文本- 图像对、数学、科学以及逻辑推理等领域。具体实现上,没有依赖基本的对象识别,而是针对每个图像的具体情境使用专门的形式语言,以确保描述精确且结构化,有利于推理任务的开展。为了生成能够被处理和用于推理的密集描述,结合使用了GPT -4o、Grounding DINO和EasyOCR。
具体的,
对于图表与示意图,向GPT-4o提出请求,让其将视觉内容转化为能够以结构化方式解释该图表的代码或脚本。例如,使用SPICE来描述电路原理图,使用PlantUML或Mermaid.js来绘制流程图,使用HTML来描述用户界面布局,使用CSV或JSON来表示表格,使用Matplotlib来处理带有标题、注释文本和说明文字的图表。
对于自然图像,GPT-4o生成详细、描述性的描述,而GroundingDINO则提供边界框信息,以精准定位场景中的关键元素。
对于纯文本图像,也就是当处理包含印刷体或手写体文本的图像时,EasyOCR提取文本及其位置信息,同时GPT-4o恢复原始文档格式。这使不仅能够捕捉到原始格式的文本,还能保留文本的上下文和布局。
对于包含文本内容的图像,也就是包含印刷体或手写体文本的图像,整合了GPT-4生成的详细文本说明、从GroundingDINO获取的边界框数据以及通过OCR(使用EasyOCR)提取的文本,以重建原始文档格式。这个过程确保了视觉元素和文本元素都能被准确表示和对齐,便于进行全面分析和解读。
对于数学图像,也就是对于包含数学内容的图像,利用GPT-4o将摘要说明、推理步骤和结果整合为密集、全面的内容,使其能够作为推理任务的相关背景信息。
ok,图像表示好了,开始进行思维链生成。在对图像添加完描述后,使用这些密集描述及相关问题作为生成思维链(CoT)的背景信息。DeepSeek-R1模型接收这些背景信息并启动推理过程,从而形成初始的思维链,这块是蒸馏。
有趣的是,但这一过程并未就此结束。虽然最初的思维链基于描述信息提供了清晰的推理路径,但它缺少一个至关重要的视觉要素——即“看到”图像本身的能力。为了弥补这一不足,引入了一种角色扮演的方法。具
体的,在这个过程中,推理过程被设计为模拟视觉理解。模型被引导反复查看图像(这里应该是看图像的描述),提取额外信息,对其进行思考并完善推理。这种方法使模型能够仿佛直接感知图像一般进行思考,从而得出更准确且富有情境信息的答案。
最后得到了数据:

2、基于规则的强化学习(RL)
通过引入明确的规则来强化推理过程,以确保准确性和结构化。 注意的,这个Deepseek-R1一样,先在R1-Onevision数据集上进行监督微调(SFT)的预训练模型,然后再利用基于规则的强化学习来生成更可靠的输出,着重强调结构化推理、逻辑推导,并通过准确性和格式检查来保持响应的完整性。
同样的,两个规则奖励:
一个是准确性规则,根据真实答案对模型的回答进行验证。它使用正则表达式提取最终结果,并通过数学验证与真实答案进行交叉核对。如果答案匹配,则模型得到奖励;否则,将施加惩罚。
一个是格式规则,通过检查推理内容和最终答案是否分别用<think>和<answer>标签括起来,并且顺序正确,来确保响应结构的正确性。正则表达式模式会验证此格式,对于每个放置正确的标签,模型都会得到奖励。
这部分的数据构成如下,主要来自logic和math两个任务,这个比较好理解。

在训练设置上,使用LLama-Factory,基础模型采用Qwen2.5-VL-Instruct,该模型有三种变体:30亿参数(3B)、70亿参数(7B)和720亿参数(72B)。
为提高效率,将图像输入的分辨率设置为518,以节省GPU内存。训练采用全模型监督微调(SFT)方法,学习率为1×10⁻⁵ ,训练轮数为1个epoch。
当然,这也有很多进一步的优化思路,例如,作者所言,
使用通用数据和多模态推理思维链(CoT)进行训练,通过纳入更多通用数据以及多模态推理思维链(CoT)数据来扩展训练数据集。这将使模型能够从更广泛的信息中受益,增强其在各个领域处理多样化推理任务的能力。
融入中文多模态推理CoT数据,将中文多模态推理CoT数据融入训练过程。通过添加这一特定语言的数据集,可以提高模型用中文执行推理任务的能力,扩展其多语言和多模态推理能力。
降低参数,例如一个更小、更高效的30亿参数(3B)模型,旨在在性能和资源效率之间取得平衡,提供强大的多模态推理能力,同时更适合资源有限的环境,具有更高的可访问性和优化性,是当前70亿参数(7B)模型的更紧凑替代方案。
总结
本文主要看推理模型用于RAG以及用于多模态模型的一些结合思路,正如我们近期观察到的,R1这类技术用于多模态,是一种趋势,大家可以夺关注。
参考文献
1、https://blog.skypilot.co/deepseek-rag
2、https://mp.weixin.qq.com/s/-pPhHDi2nz8hp5R3Lm_mww
3、https://yangyi-vai.notion.site/r1-onevision
(文:老刘说NLP)