
这个那个

DeepSeek开源周的最后一天,迎来的是支撑其V3/R1模型全生命周期数据访问需求的核心基础设施 — Fire-Flyer File System(3FS) 和构建于其上的Smallpond数据处理框架。
📥 3FS
https://github.com/deepseek-ai/3FS
3FS是一种充分利用现代SSD和RDMA网络全带宽的并行文件系统,在180节点集群上实现了6.6 TiB/s的聚合读取吞吐量,在25节点集群的GraySort基准测试中达到3.66 TiB/分钟的吞吐量,并且在KVCache查找中每个客户端节点可达40+ GiB/s的峰值吞吐量。
⛲ Smallpond
https://github.com/deepseek-ai/smallpond
Smallpond则是建立在3FS之上的轻量级数据处理框架,具有高性能、可扩展性和易用性特点。
3FS的关键特性与优势
Fire-Flyer文件系统(3FS)专为解决AI训练和推理工作负载的挑战而设计,具有以下关键特性:
性能与可用性
-
• 分离式架构(Disaggregated Architecture):结合了数千个SSD和数百个存储节点的网络带宽,使应用程序可以不受位置限制地访问存储资源 -
• 强一致性(Strong Consistency):实现了链式复制与分配查询(CRAQ)协议,确保数据的强一致性,简化应用程序开发 -
• 文件接口(File Interfaces):提供基于事务性键值存储(如FoundationDB)支持的无状态元数据服务,使用通用的文件接口,无需学习新的存储API
多样化工作负载支持
-
• 数据准备:高效组织数据分析管道的输出和管理大量中间结果 -
• 数据加载:支持计算节点间的训练样本随机访问,消除预取或打乱数据集的需求 -
• 检查点保存:支持大规模训练的高吞吐并行检查点保存 -
• 推理KVCache:提供比基于内存缓存更具成本效益的替代方案,同时提供高吞吐量和更大容量
3FS的性能表现
1. 峰值吞吐量
在一个由180个存储节点组成的大型3FS集群上,每个节点配备2×200Gbps InfiniBand网卡和16个14TiB NVMe SSD,使用约500+客户端节点进行读取压力测试(每个客户端有1x200Gbps InfiniBand网卡),最终聚合读取吞吐量达到约6.6 TiB/s,并且这一性能在有训练作业的背景流量下仍然保持稳定。
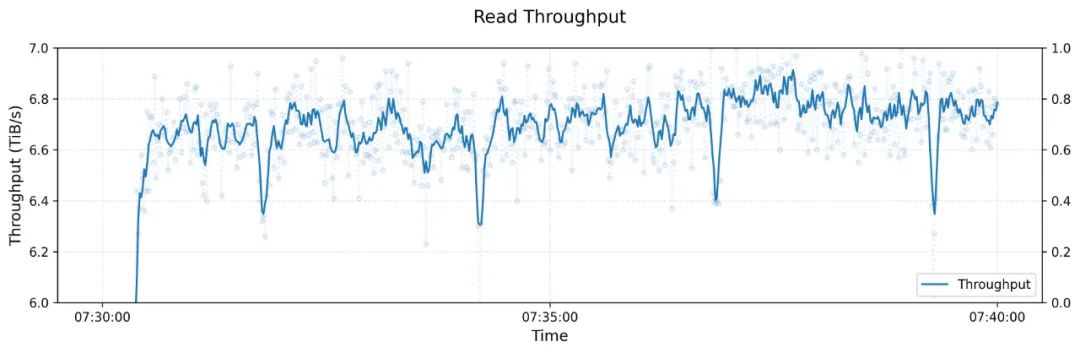
2. GraySort基准测试
DeepSeek使用基于3FS的Smallpond进行GraySort基准测试,这是衡量大规模数据排序性能的标准测试。其实现采用两阶段方法:
-
1. 通过键的前缀位进行shuffle实现数据分区 -
2. 在分区内部进行排序
测试集群由25个存储节点(每节点2个NUMA域/节点,每NUMA 1个存储服务,2×400Gbps网卡)和50个计算节点(每节点2个NUMA域,192个物理核心,2.2 TiB RAM,1×200Gbps网卡)组成。对110.5 TiB数据进行8,192个分区的排序在30分14秒内完成,平均吞吐量达到3.66 TiB/分钟。


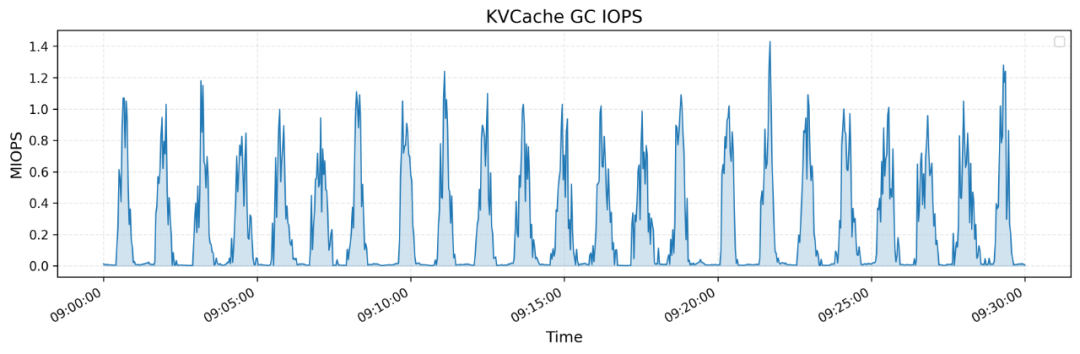
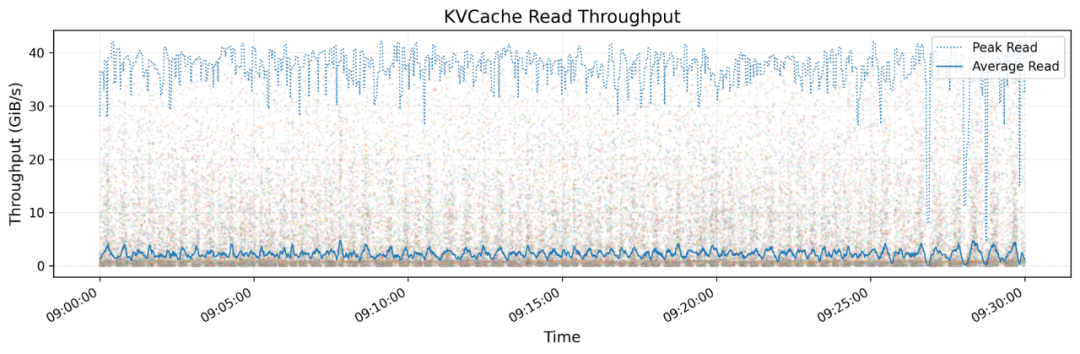
3. KVCache性能
KVCache是优化LLM推理过程的技术,通过缓存解码器层中之前token的键值向量避免重复计算。3FS的KVCache实现提供了显著的性能优势:
-
• 所有KVCache客户端的读取吞吐量峰值可达40 GiB/s -
• 高效的垃圾回收机制,支持大规模并发操作
使用3FS
获取源代码
# 从GitHub克隆3FS仓库
git clone https://github.com/deepseek-ai/3fs
# 初始化子模块
cd 3fs
git submodule update --init --recursive
./patches/apply.sh安装依赖
# Ubuntu 20.04
apt install cmake libuv1-dev liblz4-dev liblzma-dev libdouble-conversion-dev libprocps-dev libdwarf-dev libunwind-dev \
libaio-dev libgflags-dev libgoogle-glog-dev libgtest-dev libgmock-dev clang-format-14 clang-14 clang-tidy-14 lld-14 \
libgoogle-perftools-dev google-perftools libssl-dev ccache libclang-rt-14-dev gcc-10 g++-10 libboost1.71-all-dev
# Ubuntu 22.04
apt install cmake libuv1-dev liblz4-dev liblzma-dev libdouble-conversion-dev libprocps-dev libdwarf-dev libunwind-dev \
libaio-dev libgflags-dev libgoogle-glog-dev libgtest-dev libgmock-dev clang-format-14 clang-14 clang-tidy-14 lld-14 \
libgoogle-perftools-dev google-perftools libssl-dev ccache gcc-12 g++-12 libboost-all-dev还需要安装其他构建前提条件:
-
• libfuse3.16.1或更新版本 -
• FoundationDB 7.1或更新版本 -
• Rust工具链
构建3FS
cmake -S . -B build -DCMAKE_CXX_COMPILER=clang++-14 -DCMAKE_C_COMPILER=clang-14 -DCMAKE_BUILD_TYPE=RelWithDebInfo -DCMAKE_EXPORT_COMPILE_COMMANDS=ON
cmake --build build -j 32可以按照设置指南的说明运行测试集群。
Smallpond数据处理框架
Smallpond是一个构建在DuckDB和3FS之上的轻量级数据处理框架,具有以下特点:
-
• 🚀 由DuckDB提供支持的高性能数据处理 -
• 🌍 可扩展到处理PB级数据集 -
• 🛠️ 简单操作,无需长期运行的服务
安装Smallpond
Smallpond支持Python 3.8到3.12:
pip install smallpond快速入门示例
首先下载示例数据:
# 下载示例数据
wget https://duckdb.org/data/prices.parquet然后可以使用以下Python代码处理数据:
import smallpond
# 初始化会话
sp = smallpond.init()
# 加载数据
df = sp.read_parquet("prices.parquet")
# 处理数据
df = df.repartition(3, hash_by="ticker")
df = sp.partial_sql("SELECT ticker, min(price), max(price) FROM {0} GROUP BY ticker", df)
# 保存结果
df.write_parquet("output/")
# 显示结果
print(df.to_pandas())Smallpond已在GraySort基准测试中进行了评估,在由50个计算节点和25个存储节点组成的3FS集群上,成功在30分14秒内对110.5TiB数据进行排序,平均吞吐量达3.66TiB/分钟。
回顾
回顾本周发布,DeepSeek已经构建了一个完整的大模型技术栈:
-
• Day 1 – FlashMLA:高效的MLA解码内核,优化了变长序列处理 -
• Day 2 – DeepEP:首个开源专家并行通信库,支持MoE模型训练和推理 -
• Day 3 – DeepGEMM:支持密集和MoE计算的FP8 GEMM库 -
• Day 4 – 并行计算策略:包括DualPipe双向流水线并行算法和EPLB专家并行负载均衡器 -
• Day 5 – 3FS与Smallpond:高性能数据存储和处理基础设施
对此,张涛老哥表示“够造超算的了”

(文:赛博禅心)