

当下的 AI 大模型,在特定场景中表现卓越,却往往囿于定制化的藩篱,难以跨越环境鸿沟。尤其在强调自主决策的强化学习领域,AI Agent 一旦脱离预设环境便“水土不服”。
通用性,成为横亘在强化学习通往 AGI 征途上的关键瓶颈。
文章将深入解析 OmniRL 的创新技术细节与实验结果,阐述其如何通过上下文强化学习方法和大规模元训练策略,探索让 AI 从“环境适应”走向“能力泛化”的可行路径。
作者 | AIRS
长期以来,强化学习模型在面对不同环境时的泛化能力一直是研究者们关注的焦点。如何让 AI 智能体摆脱对特定环境的依赖,像人类一样快速适应新情境,是实现通用人工智能的关键挑战之一。
为了解决这一难题,香港中文大学 AIRS(深圳市人工智能与机器人研究院)相关团队近期预公开了强化学习基座模型 OmniRL。
该团队创新性地提出了一种离散随机环境的规模化生成方法,能够生成百万级别的马尔可夫决策链任务,并用于合成数百亿时间步的泛强化学习过程数据,进行模型的训练。更进一步,他们还提出了一种在上下文中整合强化学习和模仿学习的数据合成方法和模型结构。
令人惊喜的是,利用这种随机世界训练出的 OmniRL 模型,无需梯度微调,即可直接用于解决前所未见的 Gymnasium 环境。
OmniRL 创新性地提出了上下文强化学习范式,旨在构建具备通用学习能力的基座模型。它能否真正让 AI 学会“自学成才”,告别传统强化学习的局限?让我们深入了解 OmniRL,探究其背后的奥秘。
开源代码: https://github.com/airs-cuhk/airsoul/tree/main/projects/OmniRL

预训练和元训练:授模型以鱼和授模型以渔
传统预训练模型,如同让学生死记硬背知识点,虽然也能应付考试 (特定任务),但缺乏真正的泛化能力。预训练最早以教会模型完成多种多样的任务为出发点,在大规模预训练中,模型除了记住这些训练任务本身,涌现出的最重要的能力就是上下文学习(In-Context Learning),这种能力能够帮助大模型通过提示信息来构建完成新任务的能力。
OmniRL 提出大规模元训练,和预训练不同之处在于,OmniRL 目标不是记忆训练任务的技能本身,而是学习如何进行强化学习的过程。元学习,又叫学习学习的方法(Learning To Learn),早在 80 年代被提出。但 OmniRL 论文认为,缺乏大规模任务和长序列支撑的元学习,容易实际陷入“任务识别”的模式:模型只是记住了训练的环境,在推理时通过识别处于哪一个环境“激活”对应的技能。这种模式不具备对未见任务和分布外任务的泛化性。


首次利用上下文学习统一多强化学习和模仿学习
OmniRL 提出同时利用先验信息和后验奖励(Feedback)进行上下文学习,使得该模型可以自己在不同学习模式间根据需求切换。
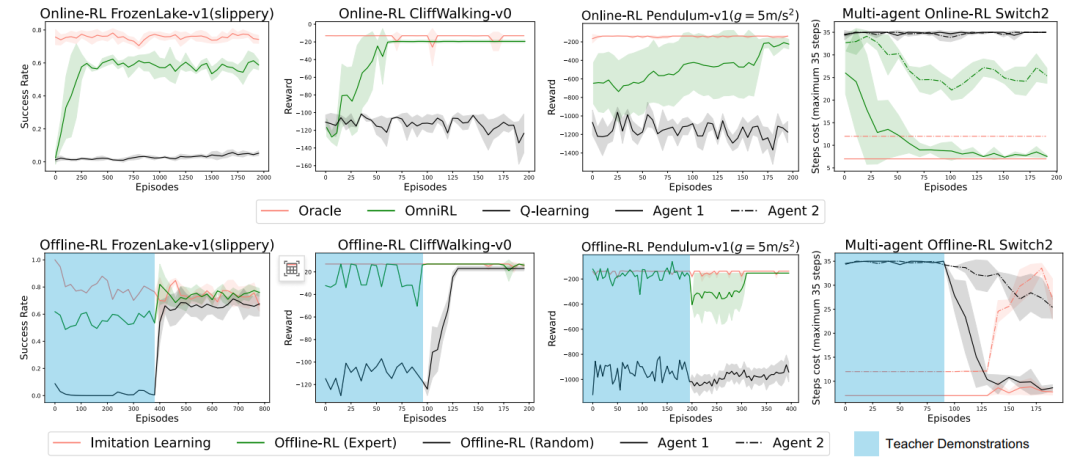
图 2 展示了在随机世界中训练的 OmniRL 模型,仅通过上下文学习,不依赖于任何梯度优化,在冷启动,或者预先给定一段演示轨迹(包括专家演示,以及较差的演示),能通过在线强化学习(Online-RL),离线强化学习(Offline-RL),模仿学习(IL)的自主切换,达到较好表现,证明上下文学习有巨大的灵活性。进一步,还能在演示的基础上,进一步通过自主探索持续提升自身能力。

首次揭示出数据多样性和序列长度重要性根源
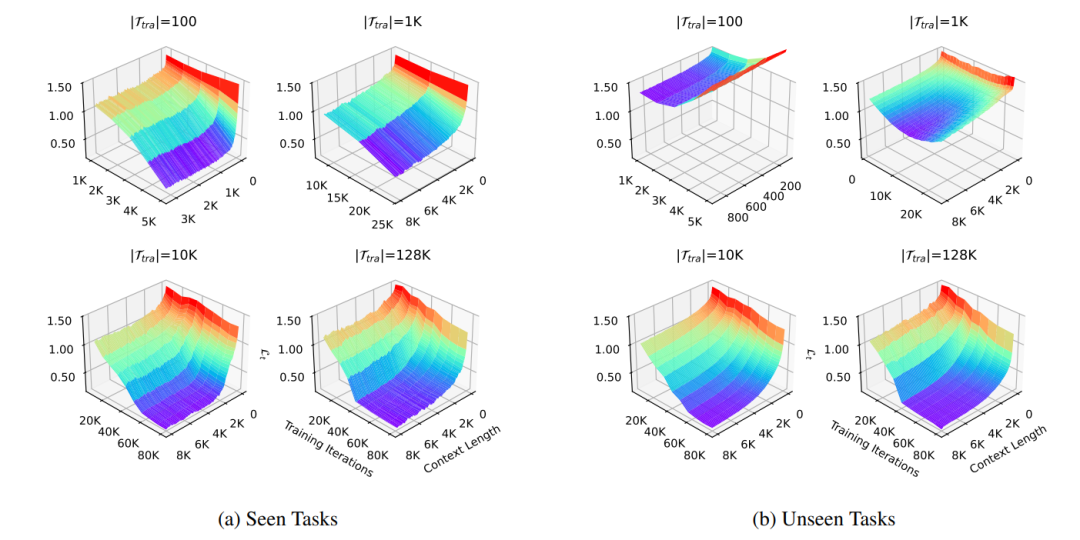
OmniRL 使用数千万参数的 Transformer 和高效线性注意力结构来进行建模。训练任务数超过 50 万个,时间步数超过一百万。OmniRL 在实验中对比相同数据量,但来自不同任务数量的效果,发现任务数量不够多时,模型会转向记忆 + 环境识别模式,即把所有训练的环境储存在参数记忆中,通过上下文进行快速的辨识。
这种模式下,智能体能否以更少的样本适应训练过程中见过的环境,但却不能泛化到未见环境。而任务数量充分时,才能激发通用上下文学习能力,这种能力可以有效泛化到未见任务,但对于所有任务都需要更长的上下文学习周期。
这个结论一定程度说明:
-
数据的完整性和多样性比数据的绝对准确性(absolute fidelity)更重要。即使采用失真的数据,通过提升上下文学习的泛化性,也有可能更好泛化到真实任务。
-
长序列建模和长时记忆是通用学习能力的自然选择。在训练任务数量增加时,模型在学习过程中自然选择不去记忆任务关联的知识,而是只记忆学习方法,从而导致对训练集中出现的任务也需要花费更长适应时间。这正是大规模元学习的特点。

面向下一代通用具身智能体的技术探索
OmniRL 的最终目标是实现对任意环境都能完全自主探索和学习的智能体。对于具身智能意义更加重大。大语言模型通过参数记忆捕捉了大量常识,百科和数理逻辑,构成了其零样本能力的基础。但具身智能面对多样的环境,任务以及复杂的本体异构性,常识很难成为解决具身问题的基础。OmniRL 相关团队认为,自主学习能力和长时记忆将是通用具身智能体的关键。
值得讨论的是上下文自主学习和记忆能力和当前大语言模型的长时序推理和思维链的异同点。OmniRL 团队认为,当前 OmniRL 更多侧重系统 1(直觉思维)的学习能力,后者侧重系统 2(逻辑思维和规划)本身。
诚然,直觉思维(系统 1)与逻辑思维(系统 2)能力的学习与提升对于通用人工智能而言,均至关重要。然而,当前主流的大语言模型在对这两种能力的深度探索上,仍存在显著不足。正是在这一背景下,OmniRL 的出现恰逢其时,有力地填补了这一关键空白,使其在具身智能等前沿应用领域,展现出传统强化学习方法难以企及的独特优势与潜力。

“AI 会取代程序员吗?”——这个问题如今愈发令人困扰。伴随着 Cursor 等 AI 编程助手爆火,面对日新月异的技术,不少开发者感到迷茫:未来的程序员究竟该何去何从?是被 AI 取代,还是与 AI 共舞?在这个充满变革与机遇的时代,我们需要重新思考软件开发的未来。为此,CSDN 特别策划推出了最新一期特刊:《新程序员 008:大模型驱动软件开发》。
读过《新程序员》的开发者曾这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。
(文:AI科技大本营)