

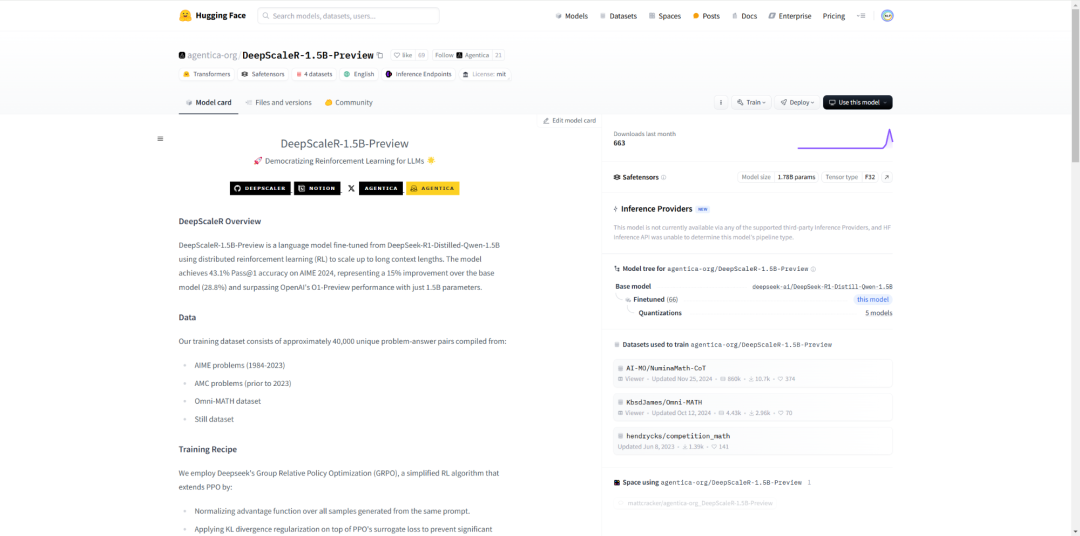
来自UC伯克利的研究团队基于Deepseek-R1-Distilled-Qwen-1.5B,通过简单的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview。
在AIME2024基准中,模型的Pass@1准确率达高达43.1% ——不仅比基础模型提高了14.3%,而且在只有1.5B参数的情况下超越了OpenAI o1-preview。
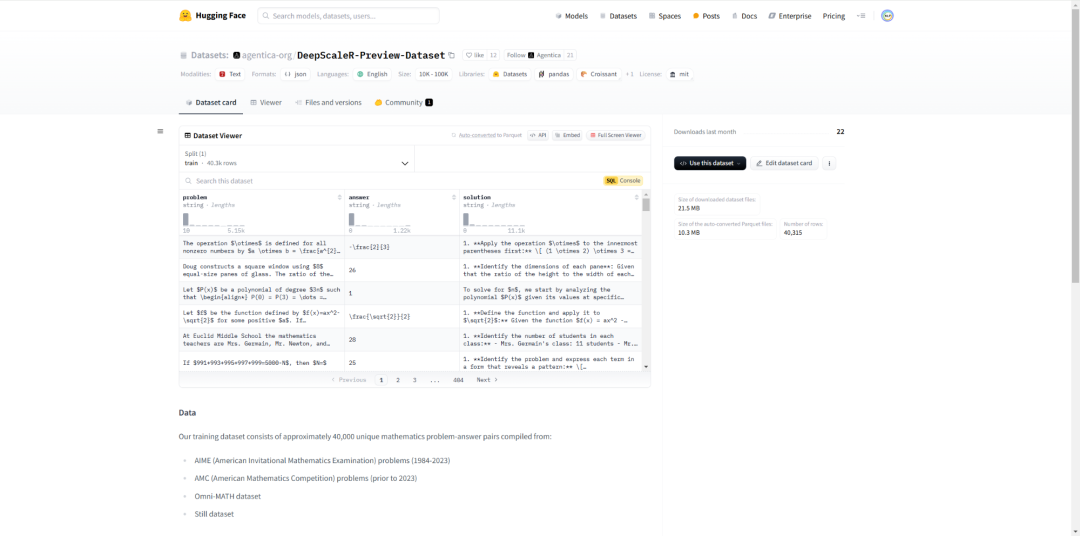
目前,研究团队已开源数据集、代码和训练日志。只用不到5000美元的预算,团队就复现了DeepSeek的成功。至此,开源又赢下一局。
参考文献:
[1] 4500美元复刻DeepSeek神话,1.5B战胜o1-preview只用RL:https://mp.weixin.qq.com/s/g2PfdI8N1oU7RWU0owh75Q
[2] https://huggingface.co/agentica-org/DeepScaleR-1.5B-Preview
[3] https://github.com/agentica-project/deepscaler
[4] https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2
[5] https://x.com/Agentica_/status/1889006266661617779
[6] https://huggingface.co/agentica-org
[7] https://huggingface.co/bartowski/agentica-org_DeepScaleR-1.5B-Preview-GGUF
(文:NLP工程化)