

今天是2025年02月12日,星期三,北京,天气晴,大家元宵节快乐。
昨日,社区顺利完成老刘说NLP技术社区第三十八讲《Deepseek R1的卡顿、部署及知识库搭建》,这是社区R1类推理大模型技术分享三部曲建设的第二阶段。
另一个是,KG+Agent+推理大模型+RAG结合进行深度研究的思路,重点看看知识图谱在里面的用处,也不错。
专题化,体系化,会有更多深度思考。大家一起加油。
一、KG+Agent+推理+RAG结合进行深度研究
我们继续来看一个工作,《Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research》(https://arxiv.org/pdf/2502.04644),其思想在于用知识图谱组织推理逻辑,并结合推理大模型用在深度搜索研究上的一个思路,在Agentic Reasoning框架中引入了Mind Map代理,构建结构化的知识图以跟踪逻辑关系,提高演绎推理能力。

模型在推理过程中动态地与外部工具交互,检索结构化记忆,并生成逻辑推理链和最终答案。
有几个点比较有意思。
一个是Mind Map代理,其通过将原始推理链转换为结构化知识图谱来存储和结构化和时推理上下文。它的存在合理性在于,为外部工具提供上下文推理支持,当推理模型对其主张不确定或在推理过程中失去线索时,可以查询Mind Map以获取相关信息,并继续基于检索到的答案进行推理。
看两个思维导图发挥作用的例子。
一个是逻辑问题的解决。思维导图有助于正确回答经常愚弄大型语言模型的棘手逻辑问题。一个著名的例子是一个改编过的谜语:“外科医生是男孩的父亲,他说‘我不能给这个孩子做手术,他是我的儿子!’谁是男孩的外科医生?”
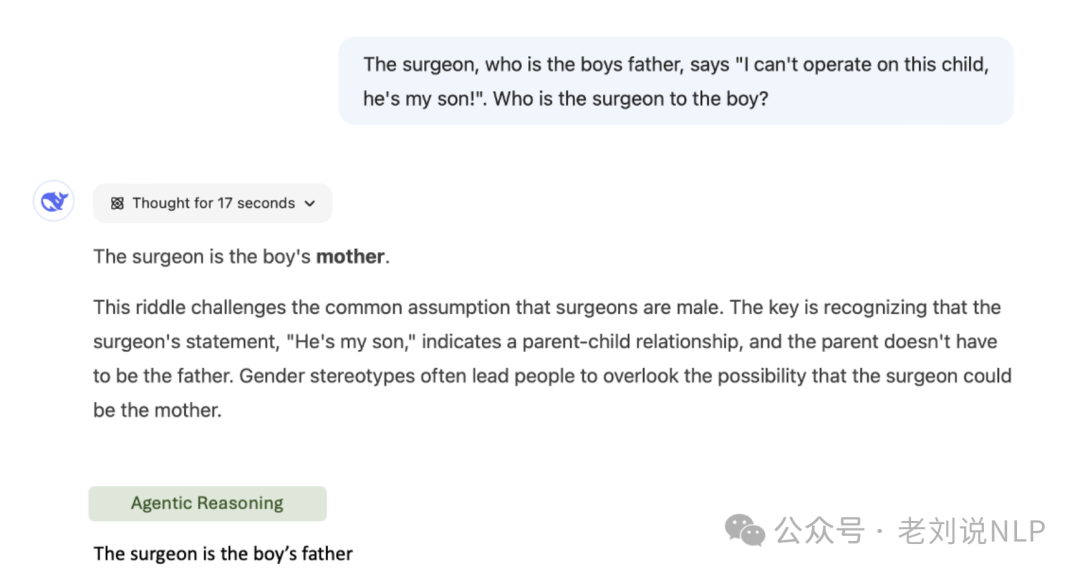
DeepSeek-R1处理这个问题用了17秒,但仍然给出了错误的答案,GPT系列和双子座系列的模型中也观察到了同样的失败,都未能识别出显而易见的逻辑结构。在我们的代理推理框架中,使用思维导图让模型能够明确分析实体[外科医生]、[男孩]和[父亲]之间的逻辑关系,从而得出正确答案。
一个是增强了策略游戏中的演绎推理能力。在《狼人杀》这款经典的社会推理游戏进行测试,玩家扮演村民或狼人的隐藏角色。村民们试图识别狼人,而狼人在不被发现的情况下欺骗团队并消除玩家。游戏在“夜晚”和“白天”之间交替进行,“夜晚”时狼人会秘密攻击,“白天”时玩家则讨论并对消除对象进行投票。

请了七位经验丰富的狼人玩家(5年以上经验)与之对战,取得了72%胜率,显著超过了预期的统计胜率和实验中人类玩家的表现。这种思路在于,思维导图这种视觉结构帮助模型根据玩家口头论证追踪不同玩家之间的关系,使其能够更准确地识别欺骗策略、预测投票行为,并优化自身的伪装战术。
那么,具体如何做的,其实很简单。
实现步骤如下:
首先,实体提取和关系识别。使用图构建LLM从推理链中提取实体,并识别相关实体之间的语义关系。
其次,社区聚类,对知识图谱应用社区聚类算法,将推理上下文分组,并使用LLM为每个组生成简洁的摘要。
最后,知识查询。有了这个知识图谱,就可以通过特定问题进行查询,例如“Who was Jason’s maternal great-grandfather?”。通过标准的检索增强生成RAG,检索并返回相关信息。
初次之外,更重要的就是网络搜索代理了。网络搜索代理调用网络搜索代理从互联网检索相关信息,并将其整合到推理链中,确保信息的相干性和相关性。作者在文中说道,对于像“2024年美国的人口是多少?”这样的事实性查询。结果将是一个简单的数字答案。对于探索性推理,如寻找关于某个主题的新视角,搜索代理会提供一个总结的、详细的、细致的视角。对于假设验证,如评估对某一假设的支持证据,结果将包括在检索到的网页中找到的支持或矛盾程度。这种动态性的相关性其实并不好控制。
具体的,研究其实现逻辑,最佳的方式,就是看远吗,例如在https://kkgithub.com/theworldofagents/Agentic-Reasoning/blob/main/scripts/prompts.py中可以看到精华部分,整个项目地址在:https://github.com/theworldofagents/Agentic-Reasoning,大家也可以看看。
二、社区R1类推理大模型技术分享三部曲建设
社区R1类推理大模型技术分享三部曲建设已经展开,是个很有趣的事儿。
三部曲之一,老刘说NLP技术社区第37讲《Deepseek R1类推理大模型的习得过程、认知误区、场景机会及技术风险》 最先顺利结束,我们一起通读了Deeseek R1论文,回顾了推理大模型的习得过程以及一些认知上的误区,推理大模型的场景机会以及一些技术风险。
在2个半小时中,我们梳理出了很多有趣的东西,回放量也创新高(欢迎查看)。
三部曲之二,老刘说NLP技术社区第三十八讲《DeepseekR1的卡顿、部署及知识库搭建》也于昨日顺利结束。

这部曲,从实践应用角度进行分享,如DeepSeek的卡顿问题、部署优化策略以及个人知识库的构建进行了深入探讨。
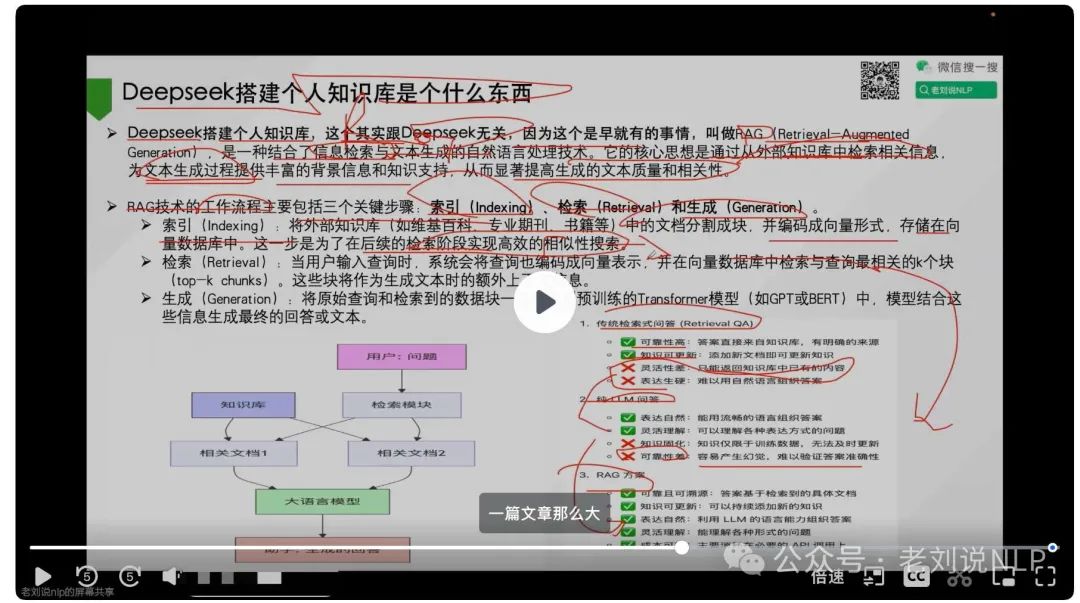
同时,也讨论了如何在实际应用中有效利用开源工具和服务,强调知识平权时代下开源工具的重要性。
数据工程一直都是如此,是整个的核心,鉴于RL的不稳定性和样本难构造,目前对于大家而言,最简便的方式,还是在原有的基础上,将<question,answer>对送入Deepseek R1类模型,使用拒绝采样的方式,整理出think部分,形成<question,think,answer>,然后再形成<question,think+answer>进行微调。试下来,效果还是不错的。
所以,社区进行三部曲之三分享,开展社区讲第39讲,从数据的角度,《DeepseekR1类推理模型的数据工程及开源复现》,看看R1的开源复现,读读源码,顺便把数据蒸馏部分,合成部分逻辑也顺一顺。

当我们看到一个新的技术动向时,最好的方式,其实是从技术基本逻辑、应用方式、数据细节三个角度出发,这样能够给我们更多启发。大家一起加油,也欢迎加入社区,一同抓住本质,做更多深入理解。
参考文献
1、https://arxiv.org/pdf/2502.04644
(文:老刘说NLP)