

当DeepSeek R1携600万美金训练成本震撼AI界之时,Hugging Face吹响开源集结号,发起Open-R1项目。这不仅是对首个开源推理模型DeepSeek R1技术路径的成功复现,更是对大模型推理训练范式的深刻变革。Open-R1项目分两阶段进行:第一阶段复现DeepSeek-R1-Distill模型(数据蒸馏),发布了22万数学推理数据集OpenR1-Math-220k;第二阶段复现DeepSeek-R1-Zero的纯RL训练流程。项目探索了GRPO优化新范式,实现了小样本推理的重大突破。本文将深度解析这场开源推理革命背后的技术细节与发展趋势,带你领略小数据如何撬动大模型的无限潜能。
一、DeepSeek R1:开源推理模型的里程碑
2025年初,DeepSeek团队发布了DeepSeek-R1模型,其强大的推理能力在业界引发轰动。DeepSeek-R1不仅在多项推理任务上超越了众多现有模型,甚至能与OpenAI的o1模型一较高下。更重要的是,DeepSeek-R1是首个开源的、性能可媲美o1的推理模型,这在推理模型发展史上具有里程碑式的意义。
1.1 推理模型的崛起:从规则到学习
在DeepSeek-R1之前,AI领域已经对推理模型进行了多年的探索。早期的推理系统主要基于规则和逻辑,例如专家系统。这些系统需要人工编写大量的规则,难以处理复杂的、不确定的问题。
随着机器学习的发展,特别是深度学习的兴起,研究人员开始尝试用数据驱动的方法来构建推理模型。早期的尝试包括使用循环神经网络(RNN)和长短期记忆网络(LSTM)来处理序列数据,进行自然语言推理。
近年来,Transformer架构的出现彻底改变了自然语言处理领域。基于Transformer的大型语言模型(LLM)在各种NLP任务上取得了惊人的成果,包括文本生成、机器翻译、问答等。研究人员发现,LLM在经过大规模预训练后,展现出了一定的推理能力,可以通过思维链(Chain-of-Thought, CoT) 等技术进一步增强。
OpenAI的o1模型是闭源推理模型的一个代表,它通过增加推理时间(test-time computation)来提升模型性能。然而,o1模型的具体技术细节并未公开。
DeepSeek-R1的出现打破了这一局面,它不仅性能强大,而且开源了模型权重,为开源社区研究和开发推理模型提供了宝贵的资源。
1.2 纯RL的魔力:GRPO与可验证奖励
DeepSeek-R1的核心技术是 Group Relative Policy Optimization (GRPO) 和 Verifiable Reward。
-
• GRPO: 传统的强化学习算法需要与环境进行大量交互,而GRPO通过比较不同策略在同一组任务上的表现,加速了学习过程。这种方法就像是让多个学生同时解答同一套试题,然后相互比较答案和解题思路,从而更快地找到最优解法。GRPO的关键在于相对比较,它不直接评估每个策略的绝对好坏,而是比较不同策略之间的相对优劣,这样可以减少评估噪声,提高学习效率。
-
• Verifiable Reward: 传统的强化学习奖励信号往往比较模糊,例如“生成文本的流畅度”,而Verifiable Reward则提供了更明确的反馈,它不仅判断最终答案是否正确,还检查推理过程是否符合逻辑。这就像是考试不仅要看最终答案,还要看解题步骤是否完整、正确,每一个步骤都会得到相应的评分。Verifiable Reward 的关键在于可验证性,它要求奖励信号是可以被客观验证的,而不是主观的、模糊的。
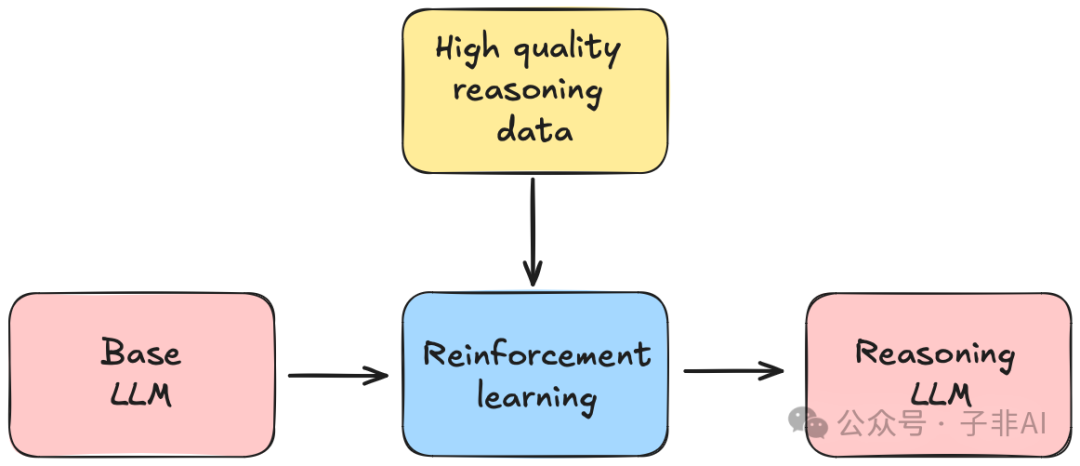
图:DeepSeek-R1的训练流程,纯强化学习是其核心
然而,DeepSeek-R1并未完全开源,其训练数据和代码仍然是未解之谜,这给开源社区复现和进一步研究带来了挑战。
1.3 Hugging Face的挑战:Open-R1项目启动
为了填补DeepSeek-R1的开源空白,Hugging Face发起了Open-R1项目,旨在完全复现DeepSeek-R1的训练流程和数据。Open-R1项目不仅要复现DeepSeek-R1,更要探索推理模型的新范式,推动开源AI社区的发展。
Open-R1项目的目标可以概括为:
-
• 数据复现: 构建与DeepSeek-R1训练数据类似的高质量开源数据集。
-
• 流程复现: 复现DeepSeek-R1的训练流程,包括纯强化学习(RL)训练和知识蒸馏等。
-
• 技术探索: 探索更高效、更先进的推理模型训练方法,例如小样本学习、隐空间推理等。
二、Open-R1项目:两阶段复现DeepSeek-R1
Open-R1项目采用了两阶段的策略来复现DeepSeek-R1:
2.1 第一阶段:复现DeepSeek-R1-Distill模型(数据蒸馏)
DeepSeek团队首先通过知识蒸馏技术,将DeepSeek-R1的推理能力迁移到了较小的模型上,得到了DeepSeek-R1-Distill模型。Open-R1项目的第一阶段就是复现这一过程。
2.1.1 开源的数学大脑:OpenR1-Math-220k数据集
Open-R1项目的第一阶段成果是OpenR1-Math-220k数据集,这是一个包含22万道数学题解析的大规模数据集,为开源社区训练数学推理模型提供了宝贵的资源。
数据生成:512张H100的工业化生产
OpenR1-Math-220k数据集的生成采用了工业级策略,充分利用了Hugging Face的计算资源:
-
• 双答案机制: 每道题生成2-4种解法,为后续的数据过滤和模型优化提供更多的选择。这样做的好处是可以增加数据的多样性,提高模型的泛化能力。
-
• vLLM+SGLang加速: 采用vLLM和SGLang两种高效的推理引擎,将推理速度从15次/小时提升至25次/小时,效率提升67%。vLLM和SGLang都针对大模型推理进行了优化,可以有效利用GPU资源,提高推理吞吐量。
-
• 16k上下文窗口: 为了处理更复杂的数学问题,将模型的上下文窗口设置为16k,覆盖75%的常规题和25%的复杂题的解题需求。更长的上下文窗口可以让模型“看到”更完整的题目信息和解题过程,有助于生成更准确、更连贯的答案。
通过这些策略,Open-R1团队实现了单日生成30万道题解的惊人效率。为了方便社区使用,项目组还特别开源了数据生成脚本,展示了如何在Slurm集群管理系统下实现分布式推理。
数据过滤:规则引擎与LLM的双重保障
为了保证数据集的质量,Open-R1团队设计了双重验证系统,对生成的数据进行严格的筛选:
-
• Math-Verify规则引擎: Math-Verify是一个基于规则的数学表达式验证工具,可以自动判断模型生成的答案是否正确。Open-R1团队对Math-Verify进行了升级,0.5.2版本新增了5项关键改进,包括纯文本答案解析、多答案识别、有序元组支持、关系运算符和区间解析等,大大提高了其准确性和适用范围。
-
• Llama3.3-70B-Instruct裁判: 对于Math-Verify无法判断的样本,Open-R1团队引入了Llama3.3-70B-Instruct模型作为“裁判”,通过特定的prompt模板,让模型判断生成的答案与参考答案是否等价。通过这种方式,Open-R1团队从被Math-Verify拒绝的样本中回收了28,000条有效数据。
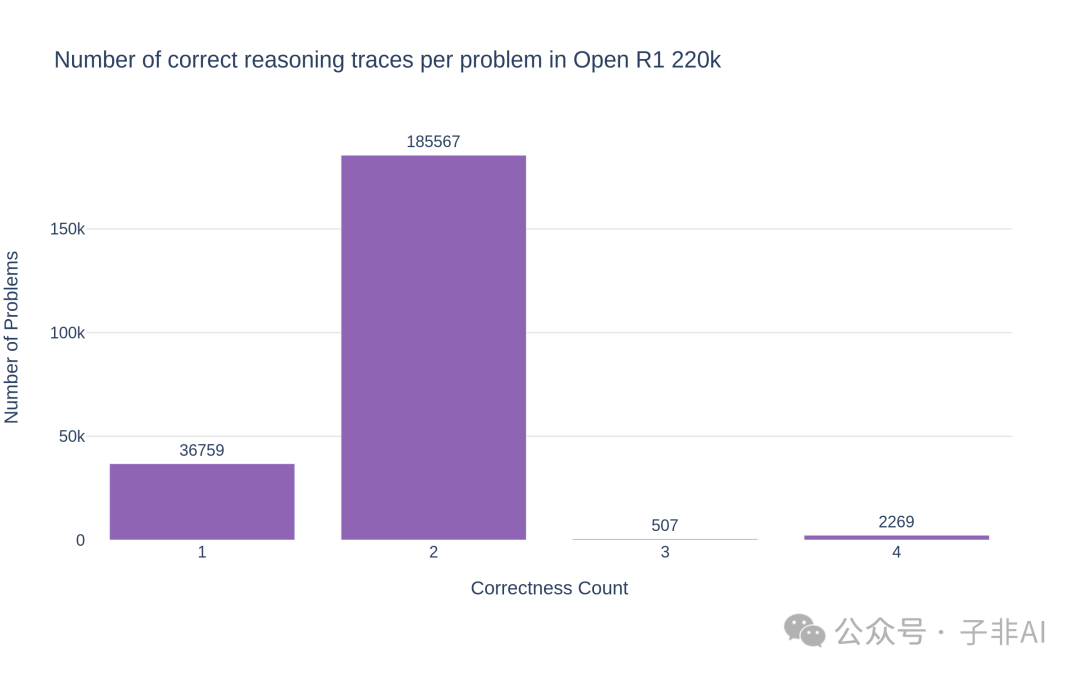
图:数据过滤系统的双重验证机制,确保数据集的高质量
性能实测:7B模型媲美官方模型
为了验证OpenR1-Math-220k数据集的有效性,Open-R1团队使用该数据集对Qwen-7B-Math-Instruct模型进行了微调,并将微调后的模型(OpenR1-Qwen-7B)与DeepSeek官方的DeepSeek-Distill-Qwen-7B模型以及OpenThinker-7B模型进行了对比:
| 模型 | MATH-500 | AIME24 | AIME25 |
| DeepSeek-Distill-Qwen-7B | 91.6 | 43.3 | 40 |
| OpenR1-Qwen-7B | 90.6 | 36.7 | 40 |
| OpenThinker-7B | 89.6 | 30.0 | 33.3 |
从结果可以看出,OpenR1-Qwen-7B的性能与DeepSeek-Distill-Qwen-7B相当,这充分证明了OpenR1-Math-220k数据集的质量和有效性。
2.2 第二阶段:复现DeepSeek-R1-Zero的纯RL训练流程
Open-R1项目的第二阶段目标是复现DeepSeek-R1-Zero的纯RL训练流程。DeepSeek-R1-Zero模型完全依赖于强化学习,没有使用任何人工标注数据或人类反馈,这使得它成为一个理想的研究对象。
2.2.1 GRPO的探索与应用
Open-R1项目的第二阶段将重点关注GRPO算法的复现和应用。GRPO算法是DeepSeek-R1的核心技术之一,它通过比较不同策略在同一组任务上的表现来加速强化学习过程。
Open-R1团队计划进行一系列实验,探索GRPO算法在不同任务、不同模型上的表现,并尝试对其进行改进。具体来说,团队将探索:
-
• 不同的GRPO变体: GRPO算法有多种变体,例如基于排序的GRPO、基于概率的GRPO等。Open-R1团队将尝试不同的变体,并比较它们的性能。
-
• 不同的超参数: GRPO算法的性能受多个超参数的影响,例如学习率、折扣因子、熵正则化系数等。Open-R1团队将进行系统的超参数调优,找到最佳的超参数组合。
-
• 不同的模型架构: Open-R1团队将尝试将GRPO算法应用于不同的模型架构,例如Transformer、LSTM等,探索GRPO算法的通用性。
2.2.2 奖励函数的设计
奖励函数的设计是强化学习的关键环节。DeepSeek-R1使用了Verifiable Reward,即基于答案正确性和推理过程结构的可验证奖励。Open-R1团队将复现Verifiable Reward,并探索其他可能的奖励函数设计。
-
• Verifiable Reward的改进: Open-R1团队将尝试对Verifiable Reward进行改进,例如引入更细粒度的奖励信号,对推理过程的不同步骤进行 আলাদা奖励。
-
• 探索新的奖励函数: Open-R1团队还将探索其他类型的奖励函数,例如:
-
• 基于模型生成文本的流畅度和多样性的奖励: 这类奖励可以鼓励模型生成更自然、更多样的推理过程。
-
• 基于模型内部状态的奖励: 这类奖励可以利用模型内部的信息,例如注意力权重、隐藏层状态等,来指导模型的学习。
-
• 基于人类反馈的奖励: 尽管DeepSeek-R1-Zero没有使用人类反馈,但Open-R1团队可以探索如何将少量的人类反馈融入到奖励函数中,以进一步提高模型的性能。
2.2.3 训练流程的优化
Open-R1团队还将探索如何优化纯RL训练流程,例如使用更高效的采样策略、更稳定的训练算法等。
-
• 更高效的采样策略: 强化学习的训练效率很大程度上取决于采样策略。Open-R1团队将尝试不同的采样策略,例如重要性采样、轨迹采样等,以提高训练效率。
-
• 更稳定的训练算法: 强化学习的训练过程往往不稳定,容易出现震荡或崩溃。Open-R1团队将尝试不同的训练算法,例如TRPO、PPO等,并探索如何提高训练的稳定性。
-
• 结合监督学习和强化学习: Open-R1团队还将探索如何将监督学习和强化学习结合起来,例如使用监督学习来预训练模型,然后使用强化学习来进行微调。
-
三、社区的探索:小数据撬动大模型
当Open-R1团队专注于构建大规模数据集和复现DeepSeek-R1的训练流程时,开源社区的开发者们正在探索另一个方向:如何用少量数据激发大模型的推理潜能。
3.1 GRPO优化:小模型的逆袭
-
• Qwen2.5-0.5B基模型:nrelhiew的实验表明,直接将GRPO应用于Qwen2.5-0.5B基模型,就可以在GSM8k基准测试上获得51%的准确率,比Qwen2.5-0.5B-Instruct模型提高了10个百分点。这一结果表明,即使是参数量较小的模型,也能通过GRPO获得显著的推理能力提升。这为资源有限的研究者和开发者提供了一条可行的路径。
-
• Unsloth框架:Unsloth团队通过优化技术,实现了在15GB显存下训练15B模型的壮举,让GRPO训练不再是“贵族专属”。Unsloth框架通过一系列技术手段,例如Flash Attention、量化等,降低了GRPO训练的显存占用,使得普通开发者也能参与到GRPO的研究中来。这大大降低了强化学习的门槛,推动了相关技术的普及和发展。
-
• Axolotl团队:Axolotl团队发现,DoRA(Weight-Decomposed Low-Rank Adaptation)在收敛速度上优于LoRA和全参数微调,为推理模型训练提供了新的优化思路。DoRA通过将模型权重分解为幅度和方向两部分,并只对方向部分进行低秩更新,从而减少了需要更新的参数量,加快了训练速度。这一发现对于加速模型迭代和降低训练成本具有重要意义。
这些发现暗示:基模型的预训练质量可能比微调数据规模更重要。正如SAIL实验室的发现,DeepSeek-R1论文中强调的”顿悟时刻”,可能更多源自基模型本身的能力。这意味着,我们应该更加重视基模型的预训练,而不是一味地追求微调数据的规模。
3.2 小样本奇迹:1k数据的力量
-
• s1K数据集: s1K数据集仅包含1000道精选数学题和来自Gemini Flash的推理轨迹,但使用s1K数据集微调的Qwen2.5-32B-Instruct模型,在竞赛数学基准测试上的表现超越了OpenAI的o1-preview模型27%。s1K数据集的成功表明,高质量的小数据集也能训练出高性能的模型。这颠覆了传统观念中“数据越多越好”的认知,为低资源场景下的模型训练提供了新的思路。
-
• LIMO数据集: LIMO数据集更加“极端”,仅包含817个训练样本,却在AIME和MATH基准测试上达到了SOTA(State-of-the-Art)性能。LIMO数据集的成功进一步证明了小样本学习的潜力。这表明,在某些情况下,精心挑选和设计的少量样本,比海量数据更能有效地提升模型性能。
图:小样本训练带来的性能跃升,s1K和LIMO数据集证明了小数据的潜力
这些实验结果验证了一个激进的假设:当基模型已经具备了足够的领域知识时,少量结构化、高质量的示例就足以解锁其高级推理能力。这为低资源环境下的模型优化提供了新的思路。这提示我们,未来的研究方向可能不再是单纯追求数据量的增长,而是更注重数据质量、多样性和针对性。
四、推理的进化:从文本到隐空间
传统的链式思考(Chain-of-Thought, CoT)方法虽然有效,但也面临着效率瓶颈:模型需要生成大量的中间推理步骤,这不仅消耗计算资源,也增加了生成无关或错误信息的风险。Open-R1社区正在探索更先进的推理方式,以突破CoT的限制。
4.1 预算强制与余弦奖励:精细化控制推理过程
-
• 预算强制(Budget Forcing): 这是一种在测试阶段控制模型推理时间的技术,通过添加“Wait”标记或终止符,可以动态调整模型的思考时长。实验表明,模型的思考时间越长,在数学基准测试上的准确率越高。预算强制的原理是,给予模型更多的时间来思考,可以使其更充分地利用已有的知识,从而得出更准确的答案。
-
• 余弦奖励(Cosine Reward): 这是一种新颖的奖励函数设计,鼓励模型生成简洁而正确的推理链(CoT),而对于错误的推理链,则鼓励其生成更长的CoT。此外,还引入了重复惩罚机制,防止模型通过重复内容来进行奖励攻击。余弦奖励的原理是,简洁而正确的推理链通常更具有逻辑性和可解释性,而冗长而错误的推理链则往往包含更多的噪声和无关信息。
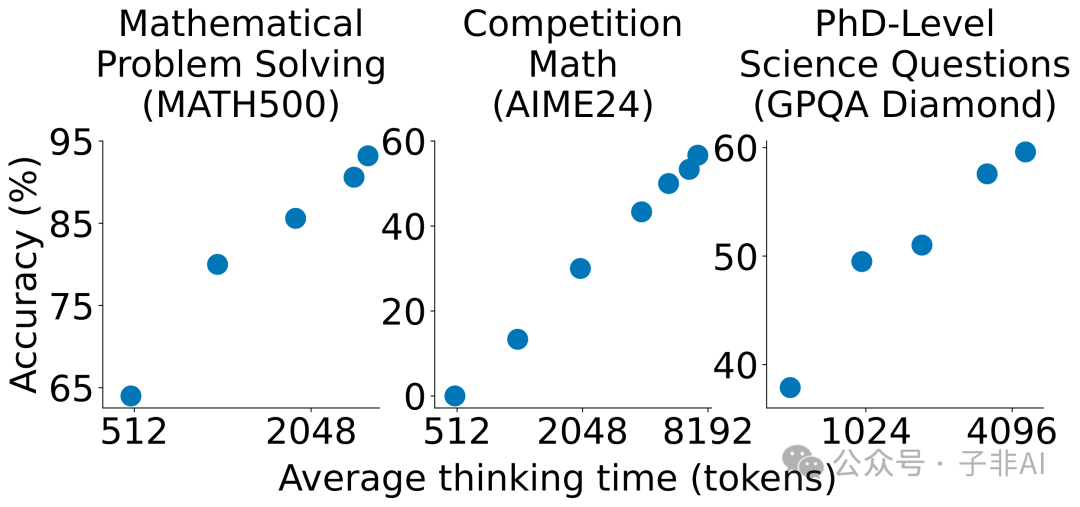
图:预算强制技术,通过控制推理时间来提高模型性能
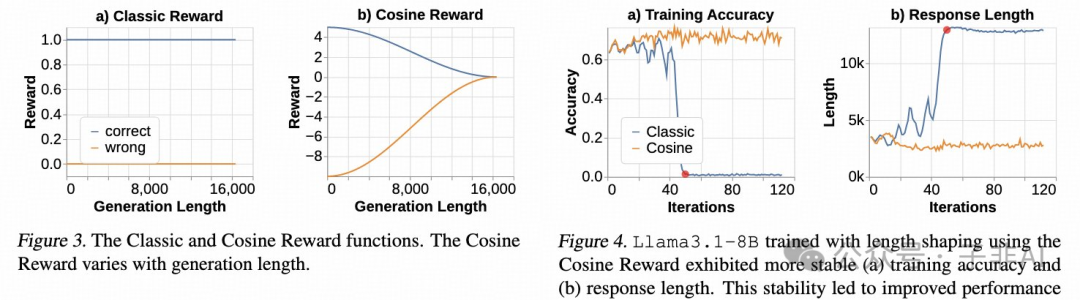
图:余弦奖励机制,鼓励模型生成更简洁、正确的推理链
这些技术使得模型能够在有限的上下文窗口内实现最优推理,为模型在终端设备上的部署提供了可能。
4.2 隐空间推理:下一代思考方式
-
• 循环语言模型架构: 一种新的研究思路是使用循环语言模型架构,在隐空间中完成多步推理,而不是在文本空间中生成中间步骤。循环语言模型可以将输入的文本序列编码成一个固定维度的向量,这个向量可以看作是文本在隐空间中的表示。模型可以在这个隐空间中进行推理,而无需生成冗长的文本。
-
• Meta Coconut项目: Meta的Coconut项目已经证明了潜在空间训练的有效性。Coconut项目表明,可以在隐空间中对语言模型进行训练,使其学习到文本的潜在结构和语义信息。
-
• 计算效率提升: 相比传统的CoT方法,隐空间推理可以减少90%的token消耗,大大提高了推理效率。
隐空间推理不仅可以节约计算资源,还为多模态推理提供了新的可能性。例如,一个数学公式的推导过程,可能以矩阵变换的形式在隐空间中完成,而无需生成冗长的文本描述。这意味着,未来的推理模型可能不再局限于文本,而是可以处理各种类型的数据,例如图像、音频、视频等。
五、开源推理革命的未来
Open-R1项目的推进揭示了AI发展的三个关键趋势:
-
1. 数据民主化: 从封闭的API生成转向本地化、透明化的数据生产。开源社区将不再依赖于少数大型科技公司提供的数据,而是可以自己动手,构建高质量的、符合自身需求的数据集。这将促进AI技术的普及和应用,降低AI开发的门槛。
-
2. 计算平民化: 通过算法优化实现资源消耗量级下降。即使是资源有限的个人或小型团队,也可以参与到最前沿的AI研究中来。这将打破大型科技公司在AI领域的垄断地位,促进AI技术的创新和发展。
-
3. 知识涌现化: 小数据激发大模型的“顿悟”现象挑战传统 scaling law。我们不再需要一味追求“大数据”,而是可以通过精心设计的小数据集,来激发模型的潜在能力。这将改变我们对模型训练的传统认知,为AI研究开辟新的方向。
Open-R1项目不仅仅是对DeepSeek R1的技术复现,更是一场开源推理革命的开端。它证明了开源社区的力量,也为AI的未来发展指明了方向。未来,我们有望看到更多基于开源技术的推理模型涌现,并在各个领域得到广泛应用。
推荐阅读
-
1. DeepSeek-R1技术报告 – 原始技术蓝图:https://github.com/deepseek-ai/DeepSeek-R1/tree/main
-
2. GRPO优化实战指南 – 15GB显存训练15B模型:https://unsloth.ai/blog/r1-reasoning
-
3. 潜在空间推理论文 – 隐空间计算的前沿探索:https://arxiv.org/abs/2502.05171
-
2024 年度 AI 报告(一):Menlo 解读企业级 AI 趋势,掘金 AI 时代的行动指南 2024年度AI报告(二):来自Translink的前瞻性趋势解读 – 投资人与创业者必看 2024年度AI报告(三):ARK 木头姐对人形机器人的深度洞察 2024年度AI报告(四):洞察未来科技趋势 – a16z 2025 技术展望 2024年度AI报告(五):中国信通院《人工智能发展报告(2024)》深度解读 2025 AI 展望 (一):LLM 之上是 Agent AI,探索多模态交互的未来视界 2025 AI 展望 (二):红杉资本展望2025——人工智能的基础与未来 2025 AI 展望(三):Snowflake 洞察 – AI 驱动的未来,机遇、挑战与变革 -
2025 AI 展望(四):OpenAI 的 AGI 经济学
(文:子非AI)