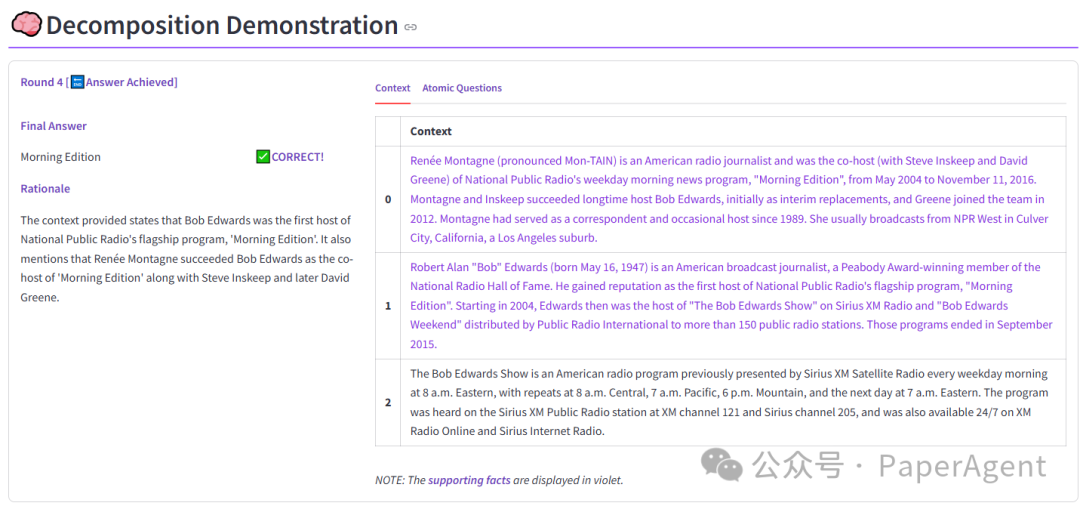
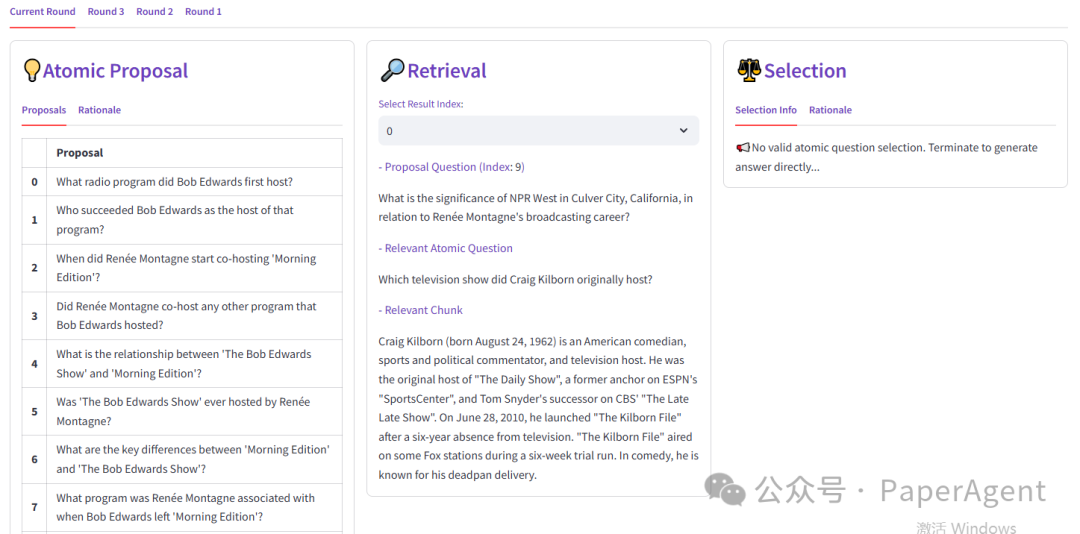
继GraphRAG之后,微软又发布PIKE-RAG,主打在复杂企业场景中私域知识提取、推理和应用能力,PIKE-RAG 已在工业制造、采矿、制药等领域进行了测试,显著提升了问答准确率。报告、代码、demo均已开源(在文末)。
demo示例:多层次异构的知识库构建与检索+自我进化的领域知识学习
RAG系统在满足现实世界应用的复杂和多样化需求方面仍然面临挑战。仅依靠直接检索不足以从专业语料库中提取深度领域特定知识并进行逻辑推理。
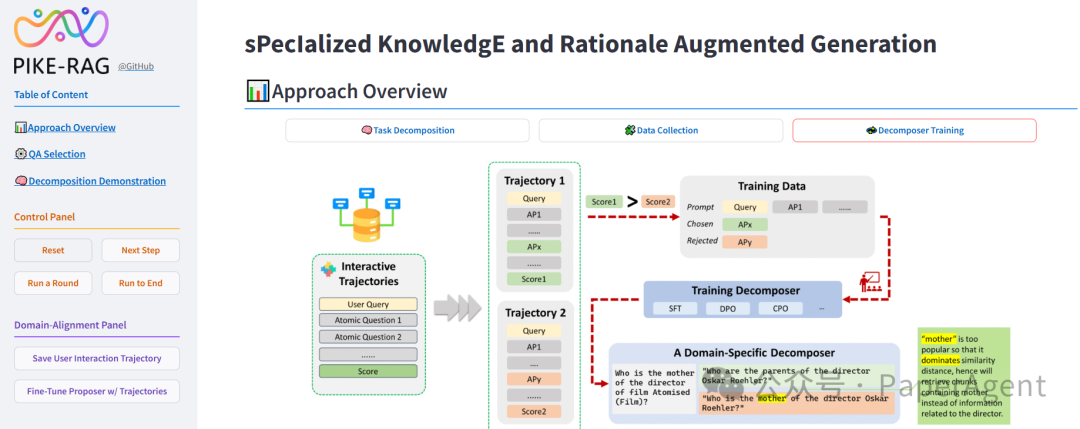
基于此,微软亚洲研究院提出了 PIKE-RAG (sPecalized KnowledgE and Rationale Augmented Generation) 方法,该方法专注于提取、理解和应用领域特定知识,同时构建连贯的推理逻辑,以逐步引导 LLM 获得准确的响应。
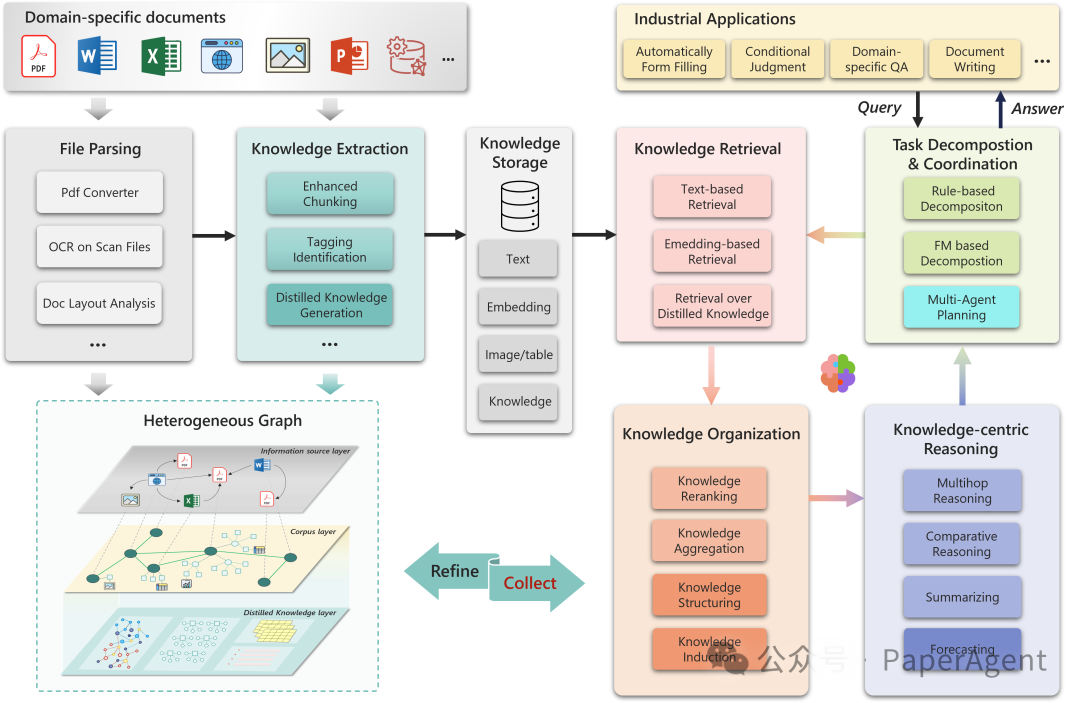
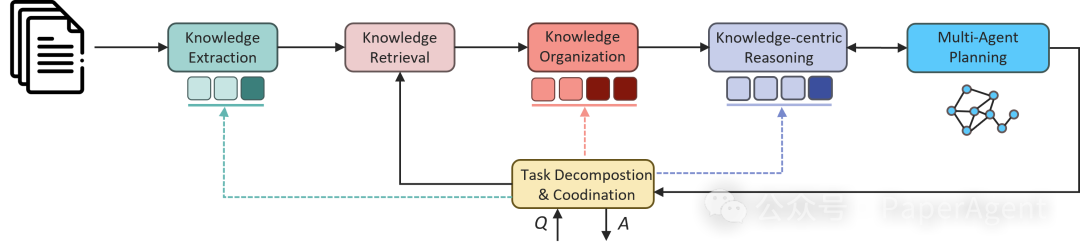
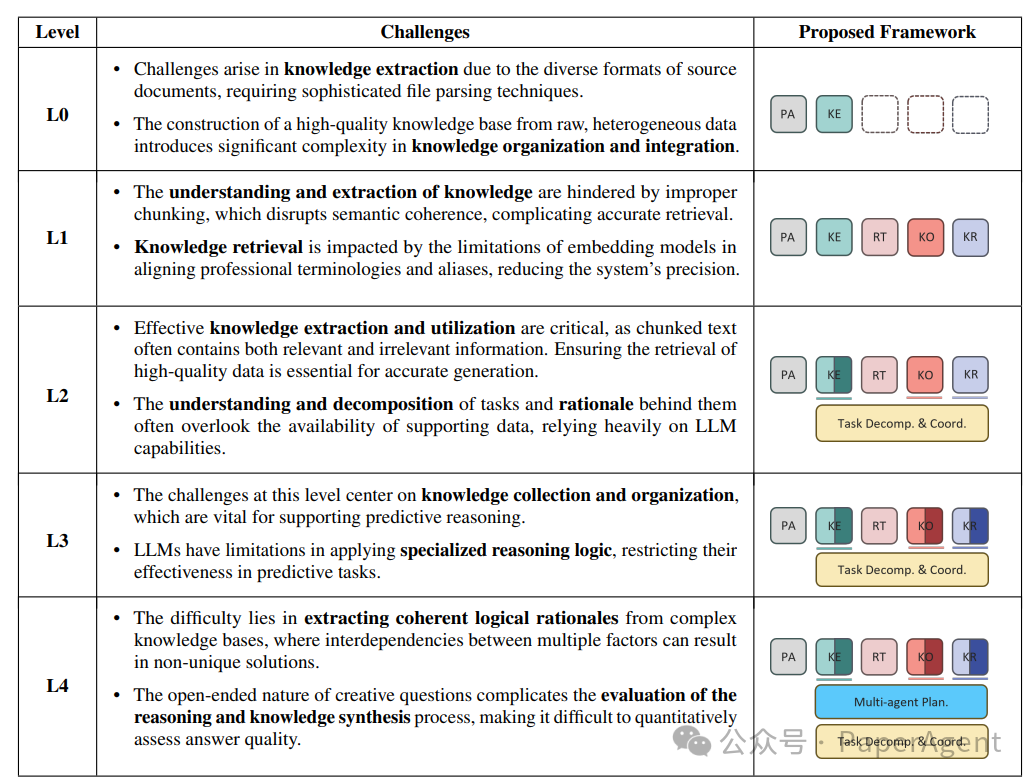
PIKE-RAG框架主要由几个基本模块组成,包括文档解析、知识抽取、知识存储、知识检索、知识组织、以知识为中心的推理以及任务分解与协调。通过调整主模块内的子模块,可以实现侧重不同能力的RAG系统,以满足现实场景的多样化需求。
例如,在患者历史病历搜索中,侧重于事实信息检索能力。主要挑战在于:
-
知识的理解和提取常常受到不恰当的知识切分的阻碍,破坏语义连贯性,导致检索过程复杂而低效;
-
常用的基于嵌入的知识检索受到嵌入模型对齐专业术语和别名的能力的限制,降低了系统准确率。
利用 PIKE-RAG,可以在知识提取过程中使用上下文感知切分技术、自动术语标签对齐技术和多粒度知识提取方法来提高知识提取和检索的准确率,从而增强事实信息检索能力,流程:

对于像为患者制定合理的治疗方案和应对措施建议这样的复杂任务,需要更高级的能力:
-
需要强大的领域特定知识才能准确理解任务并有时合理地分解任务;
-
还需要高级数据检索、处理和组织技术来预测潜在趋势;
而多智能体规划也将有助于兼顾创造力和可靠性。在这种情况下,可以初始化下面更丰富的管道来实现这一点。
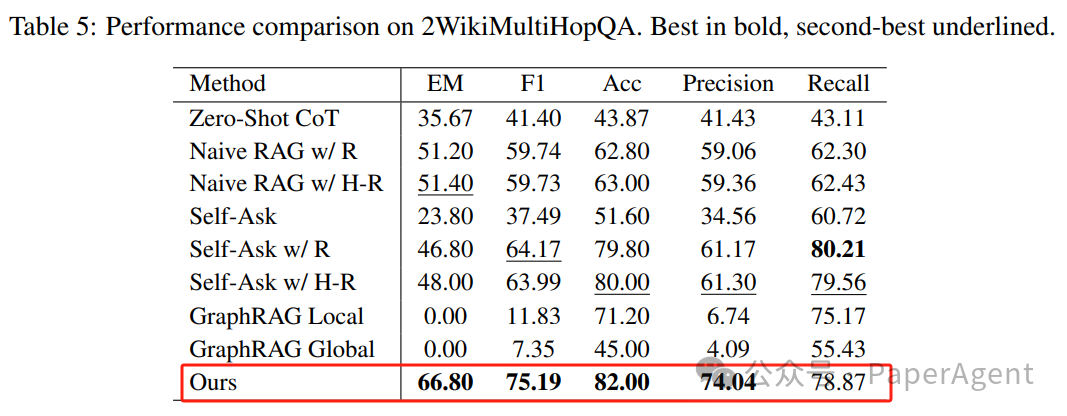
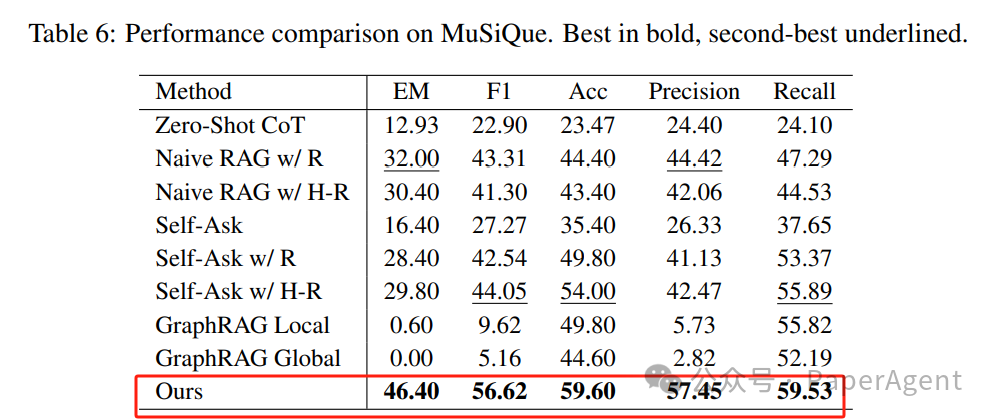
与Zero-Shot CoT、Naive RAG、Self-Ask、GraphRAG Local、GraphRAG Global相比,PIKE-RAG 在准确率、F1 分数等指标上均表现出色,PIKE-RAG 在处理复杂推理任务方面具有显著优势,特别是在需要整合多源信息、进行多步骤推理的场景中。
首次提出了5级RAG系统能力与挑战,针对不同系统层级的技术挑战,PIKE-RAG框架都有针对性策略。以下缩写被使用:“PA”代表文件解析,“KE”代表知识抽取,“RT”代表知识检索,“KO”代表知识组织,“KR”代表以知识为中心的推理。
https://arxiv.org/abs/2501.11551https://github.com/microsoft/PIKE-RAGPIKE-RAG: sPecIalized KnowledgE and Rationale Augmented Generation
(文:PaperAgent)