

在视频大模型领域,可灵(快手)、即梦(字节)已经对Sora形成了遥遥领先之势。
也许有人问了,腾讯去哪里了?
腾讯搞了个开源的混元视频大模型,其效果一点也不比Sora差。
但为什么名气不大呢?
其实主要是因为开源的视频大模型对机器配置要求过高导致的,像我的12G的3060,跑几秒钟视频要一个小时以上。
大部分爱好者没有那么强悍的显卡。
腾讯在开源频领域的成就,是独一档的。某种意义上讲,不亚于DeepSeek在生成式AI领域的地位。
今天给大家介绍一个腾讯和浙大合作的数字人技术:Sonic。
可以用一张照片+一段视频,生成可以动的数字人。
先放官方示例:
我们可以看到,视频能够很好的匹配口型。
其实在匹配口型方面,腾讯一年前就发布相关开源工具了,这次的Sonic操作更简便。
如今,有人适配了ComfyUI,我把节点做一下介绍。
一、插件地址
https://github.com/smthemex/ComfyUI_Sonic
二、模型安装
1、sonic模型(文末打包下载)及对应路径
— ComfyUI/models/sonic/
|– audio2bucket.pth
|– audio2token.pth
|– unet.pth
|– yoloface_v5m.pt
|– whisper-tiny/
|–config.json
|–model.safetensors
|–preprocessor_config.json
|– RIFE/
|–flownet.pkl
2、svd模型(文末打包下载)及对应路径
— ComfyUI/models/checkpoints
├──svd_xt_1_1.safetensors
三、工作流简介
需要注意的是,该插件需要transformers==4.43.2,如果高于或者低于该版本,有可能会出现无法正常运行的情况。
如果无法正常使用,可修改requirements.txt,将transformers==4.43.2前的“#”去掉,然后重启启动器。
ComfyUI\custom_nodes\ComfyUI_Sonic\requirements.txt
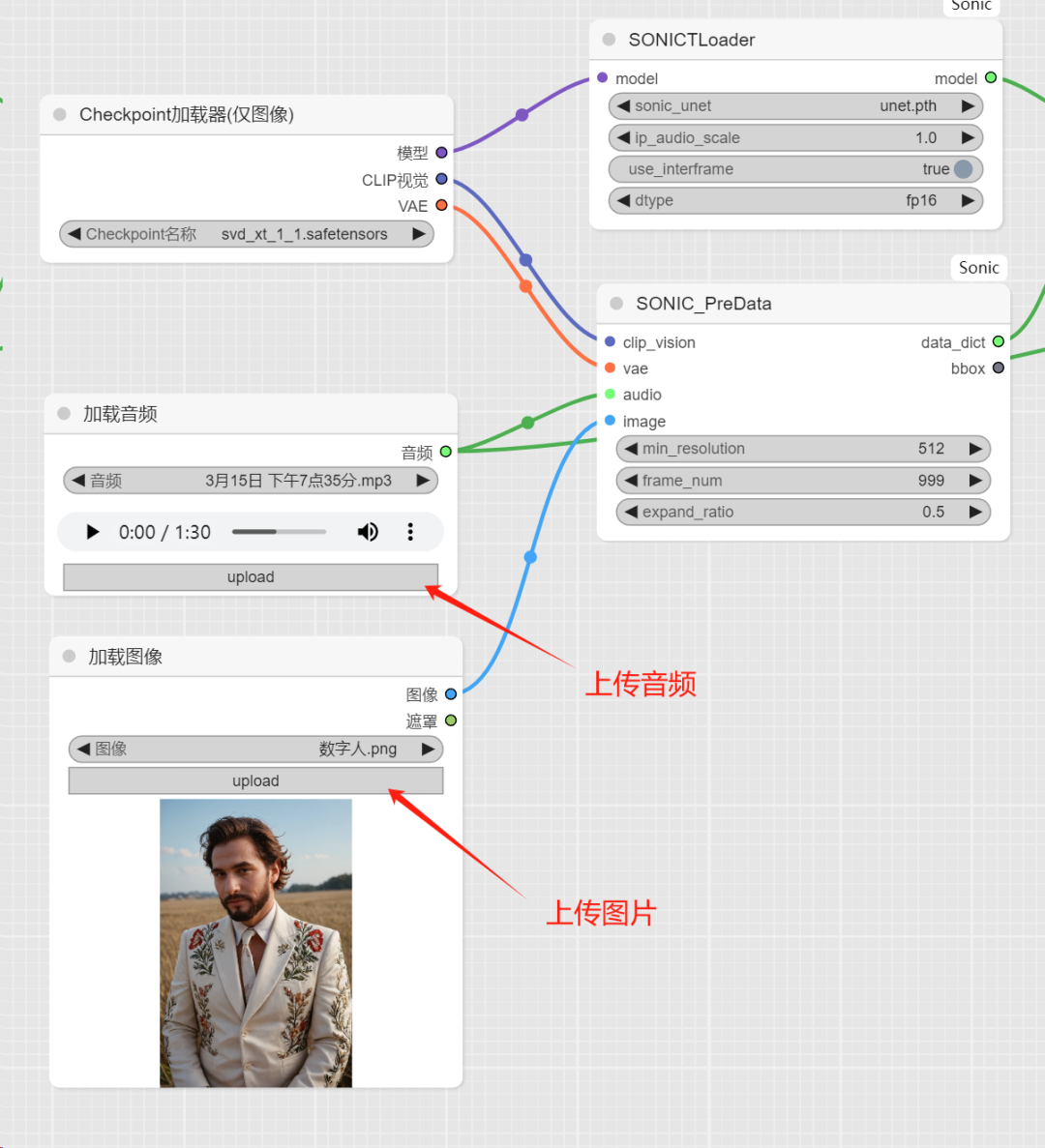
checkpoint加载器,加载svd_xt_1_1.safetensors
加载音频和加载图像,分别上传用来做数字人的声音和图片,图片建议背景干净的大头照。
SONICTLoader节点,加载unet.pth模型。
SONIC_PreData节点,其中frame_num为声音的长度,越长越耗时。
其余参数建议保持默认。
(小于16G显存的就尽量不要生成过长视频了,生成几秒钟意思意思得了。)
网盘下载:
https://pan.quark.cn/s/323447a53ead
(文:路过银河AI)