

BEWO团队 投稿
量子位 | 公众号 QbitAI
兔子通过两只耳朵可以准确感知捕食者的一举一动,造就了不同品种广泛分布在世界各地的生命奇迹;同样人也需要通过双耳沉浸式享受电影视听盛宴、判断驾驶环境和感知周围活动状态。
那应用火爆的diffusion生成模型是否可以做到直接生成符合物理世界规律的空间音频呢?
此前,经典的Text2Audio的工作可以通过文本抽象的语义生成较为准确的单通道音频。
但是这忽略了人类与生俱来的感知双通道音频的能力。应用角度来说,通过文本控制生成多通道音频在影视娱乐、AR/VR等领域拥有重要应用。
在这个趋势的背景下,为了增强文本对于多通道音频生成的控制,港科大北邮团队首次从数据、模型和评价标准角度都创新性的将控制声源方向纳入到生成范围内。
什么是空间音频生成?
什么是空间音频?
似乎能够通过声音判断事物方向和状态是自然人与生俱来的能力。生物声学 (Bioacoustics)是早在20世纪便进行了深入的探索。人能感知声音的方位,主要来自以下三个方面:
-
ITD (主要不同):Interaural Time Difference-耳间时间差。即由于双耳耳间距离导致声音到达两只耳朵的时间不一样。这一点是双通道的主要差异。
-
ILD:Interaural Level Difference-耳间声强差。即由于双耳耳间距离导致声音到达两只耳朵的强度和衰减不一样。这一点是辅助方式,在实际生成中发现这点较难度量,基本能量一致。
-
耳蜗、耳道和头骨等生理结构:由于人的感知系统非常复杂,并且涉及物理及生理研究,是一门非常深的学问。在Bioacoustic领域,很多人用深度学习方法构建合理的的HRTF (Head-related transfer function),才能够很好的模拟生理结构。但是鉴于本文为先期探索工作,文中不考虑这点的影响。

实现空间音频生成相关的技术路线?
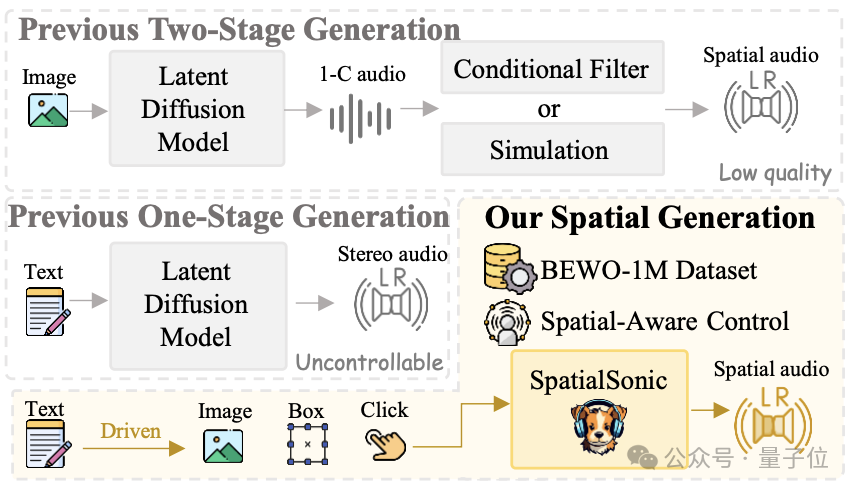
1、双阶段方案:首先通过普通text2audio的模型生成单通道音频,然后通过仿真或者可学习的滤波器进行串联。使得最终能够获得多通道的空间音频。这种系统显然不够鲁棒并且无法适应复杂场景的生成任务。
2、此前的单阶段方案:虽然这类系统能够生成stereo音频,但是远远不具备生成spatial音频的控制能力。
3、该研究方案:提出了从数据集、方法和评估指标的一条龙解决方案,较好的提升了对于spatial音频的控制。
数据构造:让机器“耳听八方”的数据工厂
在本项研究中,数据构造是整个系统的基石!
想要生成各个方向上的音频,就必须让生成模型理解方向上的区别。比如想要让系统生成摩托自左向右行进,就需要提供摩托在左、在右、自左向右和自右向左的音频让系统明白区别。这样音频收集的成本显然是非常巨大的,为什么不做一个高效的“数据工厂”呢?
接下来,带大家揭秘BEWO-1M(Both Ears Wide Open 1M)数据集的“生产流水线”。
为什么需要BEWO-1M?
现如今一般的音频-文字数据集都缺乏明确的空间信息描述,比如即便有双通道音频,配套的文字描述也只是“汽车驶过”,而没有具体方位信息(比如“汽车从右前方驶向左前方”)。这对于生成具有方向感的空间音频完全不够用!
所以,需要一个超大规模的、带有丰富空间描述的双通道音频数据集,而 BEWO-1M 应运而生。它包含超过100万条音频-文本对,并且支持动态声源、多声源等复杂场景。
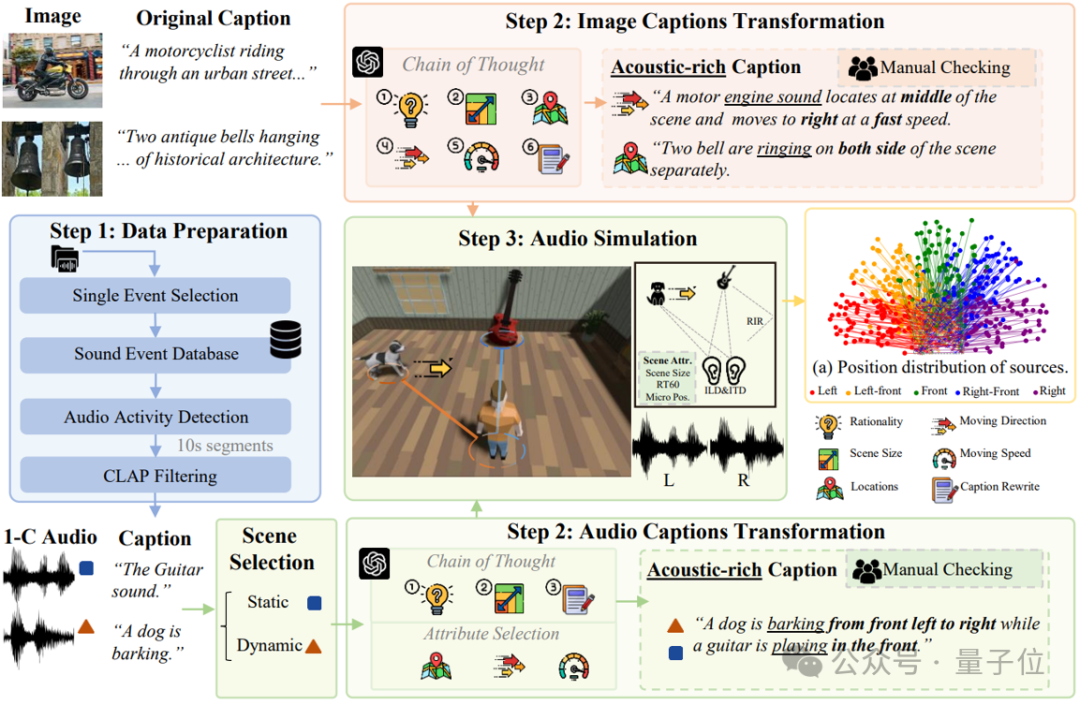
借助近些年的热门的GPT-4和严谨的仿真实验,最终通过思维链(Chain of Thought)构造了一个包含100万条、共计约2800小时音频的大规模数据集,其中包括:
-
单声源静态音频子集(Single Stationary):比如“猫在左边叫”。
-
单声源动态音频子集(Single Dynamic):比如“直升机从左飞到右”。
-
多声源音频子集(Double, Mixed):比如“左侧有雷声,右侧有狗叫”。
-
真实世界音频子集(Real World):还手动标注了少部分真实录制的双通道音频,确保测试集的真实性。
数据多样性一览:

BEWO-1M是目前首个包含方向描述的大规模双通道音频数据集,它不仅适用于空间音频生成,还可以扩展到空间音频字幕生成(Appendix.G.5)、音频-文本检索(Appendix.G.6)等其他任务。在实验中,发现它能够显著提升生成模型的空间控制能力,让机器真正做到“耳听八方”。
生成方法简述
感谢Stability AI的研究者们,他们开发了用于生成双通道的模型。但是这里生成模型存在比较显然的音频生成问题。比如:在Stable Audio中输入prompt “A piano sound exists on the left side”, 最终生成的钢琴声音的方向是不可控的。这是由于他们的双通道音频完全由真实数据训练得到,方向上并不具有足够的多样性。所以可控方向的音频生成模型迫在眉睫。
有了BEWO-1M直接finetune行不行?行!直接使用带有方位自然语言的prompt,直接进行finetune就能够让模型获取最基本的生成指定方向音频的能力。对此作者提供了一个通过自然语言控制的Gradio Demo.
但是涉及到方向自然语言理解的时候存在非常多样化的表达。这些多样化的表达对文本的encoder带来了极大的挑战。对于T5这个非常经典的编码模型来说,更长的文本长度会带来更长的编码和更大的理解难度。
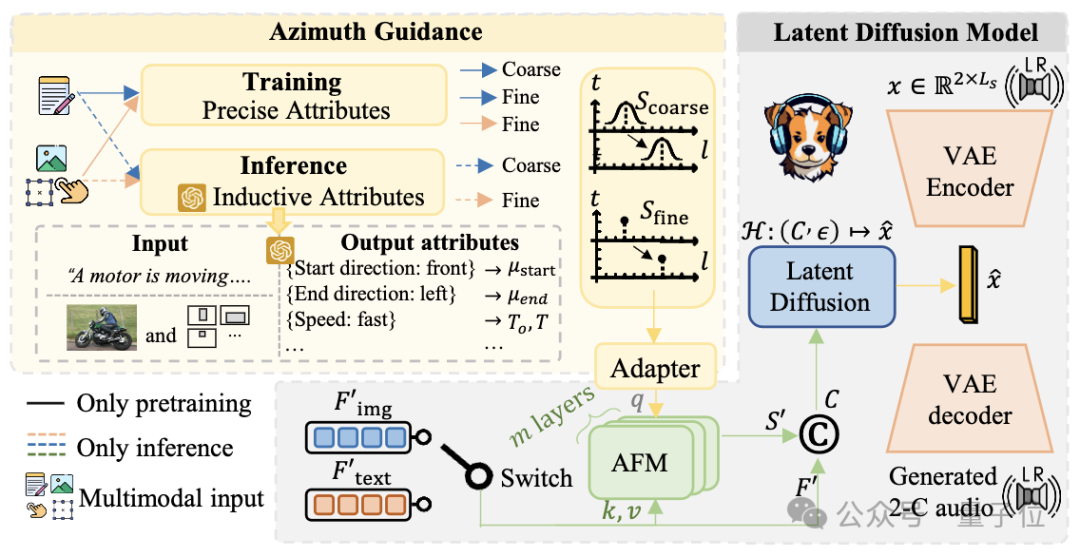
那更进一步地,为了应对这样的挑战有两个非常自然的想法。(1)将空间控制和文本控制解耦;(2)利用大模型对于文本的理解能力。
将空间控制和文本控制解耦.就意味着增加空间控制的引导!空间控制的实现主要来自仿真的训练数据,作者有极为准确的仿真建模,所以在训练时的角度是精确到小数点后4位的。那么在训练的时候使用这个角度是非常自然的。对此作者提供了一个通过精确方位信息控制的Gradio Demo.
利用大模型对于文本的理解能力可以在推理的时候用推理和上下文学习获取可靠的方向信息(详见论文),这个方向在人工验证中正确率高达90%。

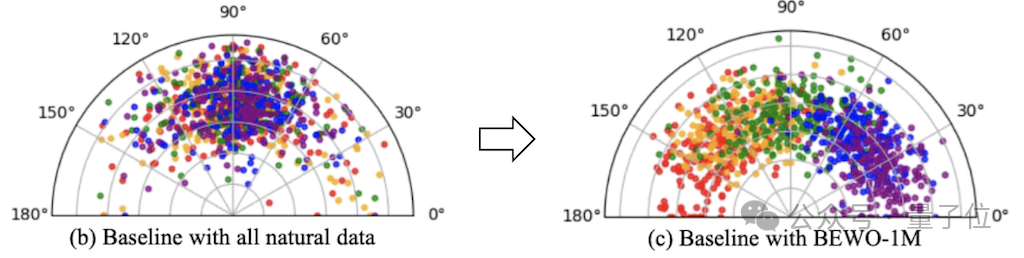
通过对空间控制和文本解耦实现了如上图可视化的更精准的音频方向的控制。其控制性能相比直接finetune有了精准性的提升。
实验过程中,作者发现如果使用极为准确的角度建模方式可以生成方向较为准确的音频,但是生成的音频语义多样化欠佳。所以同时开发了coarse建模方式可以获得更多样化的音频生成,但是会出现方向控制不准确的情况。
“多样性 or 控制” 这个生成千古难题依然在这里是个trade off。
有了基于大量文本音频对的数据得到的文本控制的模型?那么如何迁移到其他模态上呢。而且文本编码用的是T5编码。
众所周知,T5作为encoder+decoder的model在大模型的现今已经淘汰了。研究团队简单借助前人的VL-T5接着做了简单的对齐实现了简单的image到spatial audio的生成,这仅仅是给社区提供一个简单粗糙的图像引导的音频生成的baseline。
评价和结果
为了和其他模型比较,研究团队开发了多种语义和声源方向上的评估算法。
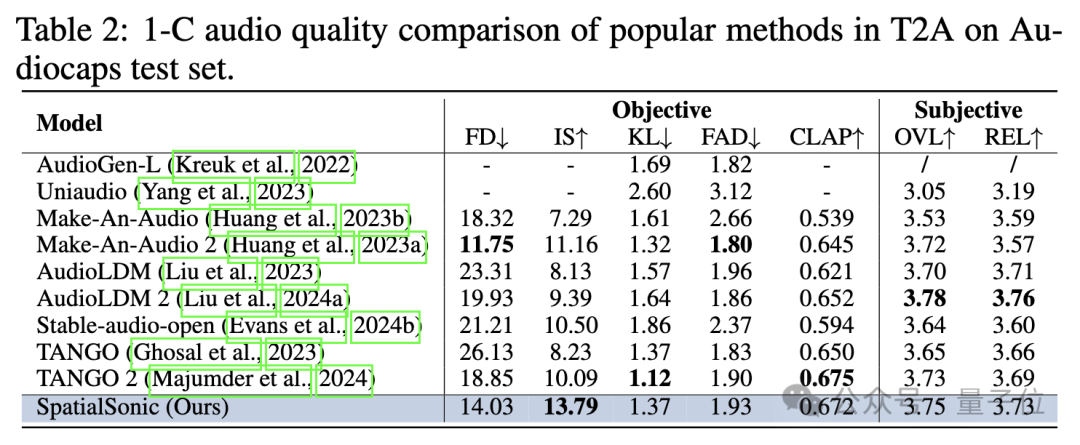
语义层面,此前Text2Audio的生成的评估算法依然有效。作者直接声道平均后评测语义层面上的相似程度。下表展示了以单通道模型的评估标准评估SpatialSonic模型依然具有一定的先进性。
声源方向层面,研究团队创新性地首次提出通过ITD求出方位误差。根据背景所述,人主要通过ITD来判断物体的大致方位,同样也采用ITD作为评估方法。
此前ITD的评估一般由2种方法而来:
-
传统信号方法:代表为GCC-Phat
-
深度学习方法:代表为StereoCRW
本文利用这两种ITD评估方法,开发了对两段音频的ITD进行不同程度的评估算法(GCC MSE、CRW MSE和FSAD)。通过这些指标很好地展示了模型在文本引导的空间音频生成上的优越性。
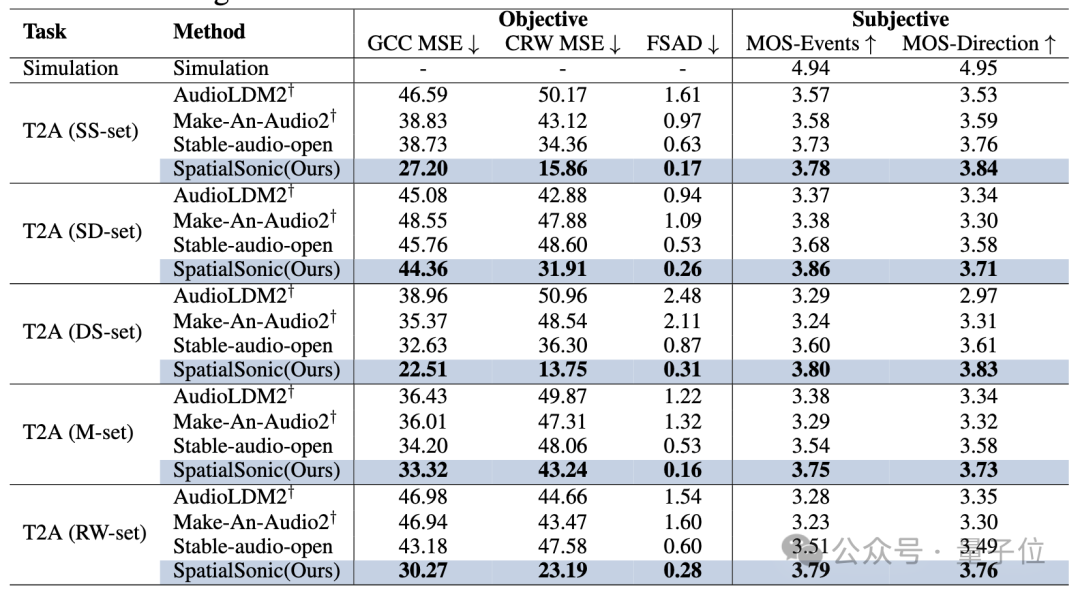
由于音频本身具有的耦合性,研究团队坚信这并不是生成音频ITD相似度的评估算法的最终形态。团队会不断在GitHub上更新更优质的算法。更多的实验结果请参考论文。
如果你好奇如下几个问题,请向论文中寻求答案!
1、方向的参与程度是否会影响音频的生成质量?(Appendix.G.9)
是的。作者发现加入方向距离中间偏差越大,生成音频质量会逐渐下降。比如,质量上,纯左<左前<正中。
2、由于方向的加入,必然导致caption长度的增加,这是否会影响音频的生成质量?(Appendix.G.10)
是的。作者发现caption长度越长,生成质量会下降。
3、不同类别的控制方向能力是否相同?是否存在一些类别声音控制方向能力较强,一些较弱的Bias?(Appendix.G.11)
确实不同。作者发现对于个别类控制能力较强,其他类控制能力稍弱。推测这与数据分布和GPT induction都存在关联。
未来展望
未来在以下多方面存在改进空间:
引入HRTF模拟耳道等真实感知。
当前Visual由于使用Coco数据集存在较强的in domain问题。OOD(Out of Distribution)或者OV (Open Vocabulary)会有非常大的进步空间。
Interactive的实现依赖于SAM的性能,实现依然不是非常优雅且存在错误累积。
VL-T5早已落后时代,或许作为初步探索足够,但是未来必然会有更优雅的方式。
项目主页: https://peiwensun2000.github.io/bewo/
Gradio Demo (自然语言控制): http://143.89.224.6:2436/
Gradio Demo(滑条控制控制): http://143.89.224.6:2437/
Github代码: https://github.com/PeiwenSun2000/Both-Ears-Wide-Open
Arxiv论文: https://arxiv.org/abs/2410.10676
数据集: https://github.com/PeiwenSun2000/Both-Ears-Wide-Open/tree/main/datasets
投稿请工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)