
MLNLP社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。
总览
最近在研究和复现 DeepSeek-R1(671B 参数 MoE,激活 37B 参数,128K 上下文的深度思考模型)论文,于是画了三张图来把整个论文核心内容总结一下,欢迎大家讨论!核心是三组模型:
-
一是纯强化学习(后文简称 RL)方案训的 DeepSeek-R1-Zero 验证技术方案可行,Reasoning 能力提升;
-
二是 80w 有监督微调(后文简称 SFT)+ 类似刚才 RL 方案训练的 DeepSeek-R1,能力对标 OpenAI o1;
-
三是直接拿刚才 80w 对 Qwen/Llama 系列模型 SFT 蒸馏出来的小模型,能力对标 OpenAI o1-mini。
先上图!

图一:DeepSeek-R1-Zero 训练

图二:DeepSeek-R1 训练

图三:DeepSeek-R1-Distill 系列小模型蒸馏
分别展开三张图
图一:DeepSeek-R1-Zero 训练

图一:DeepSeek-R1-Zero 训练
先说意义:DeepSeek-R1-Zero 首次通过纯 RL 而不用任何 SFT 激发 LLM 的推理能力,让模型自己探索解决复杂问题的 CoT,生成能自我验证(self-verification)、反思(reflection)的 long-CoT。
再看动机:RL在推理任务中已被证明具有显著的效果,然而之前的工作严重依赖于监督数据,收集耗时费力。所以能不能让 LLM 通过纯 RL 进行自我进化嘞?于是有了这一部分的工作。
训练策略及优化目标:采用了 DeepSeek 自家提出来的 GRPO 算法(Group Relative Policy Optimization)。GRPO 放弃了与策略模型大小相同的 Critic Model 来节省 RL 训练成本。具体地,对于每个问 ,GRPO 从旧策略模型 中采样一组输出 {},然后通过最大化以下目标函数来优化策略模型 (表示待优化的参数):
 简单来说,就是针对分布 P(Q) 中采样的一个问题 q,通过计算这一组 G 个输出结果的奖励得分的期望(即对所有问题的平均)来获得整个目标函数的期望值。其中,优势函数 用来计算当前策略相比旧策略的优势,表示当前策略在该状态下的表现是否好于旧策略。而使用KL散度(Kullback-Leibler divergence)度量当前策略()与一个参考策略()之间的差异,是为了从而约束策略的更新,避免策略的过大变化。具体可以去自行研究一下 GRPO 的论文,这里就不再展开太细。
简单来说,就是针对分布 P(Q) 中采样的一个问题 q,通过计算这一组 G 个输出结果的奖励得分的期望(即对所有问题的平均)来获得整个目标函数的期望值。其中,优势函数 用来计算当前策略相比旧策略的优势,表示当前策略在该状态下的表现是否好于旧策略。而使用KL散度(Kullback-Leibler divergence)度量当前策略()与一个参考策略()之间的差异,是为了从而约束策略的更新,避免策略的过大变化。具体可以去自行研究一下 GRPO 的论文,这里就不再展开太细。
奖励建模:并没有用 Reward Model(发现存在 reward hacking),因此用的基于规则的奖励,包括两方面:
-
准确性奖励:准确性 RM 模型评估答案是否正确。例如,数学问题结果是确定的,所以可以让模型最后把答案包在 \box 里以便基于规则验证正确性。对于 LeetCode 问题,可以使用通过执行测试用例来判断对不对。
-
格式奖励:要求模型将思考过程放在 <think> 和 </think> 标签之间。
训练模版:因为是从预训练的 base 模型开始训,所以并没有用 chat templete,而是如图模版,直接拼上各种 prompt 让模型往后续写输出结果,纯纯根据奖励来自我优化:
 实验观察到模型自我进化:随着 test-time computation(也就是生成 token 数)的增加,DeepSeek-R1-Zero 涌现出复杂的行为,例如反思,以及探索解决问题的替代方法,还观察到有趣的”顿悟时刻“(aha moment)。这些行为并非人类明确引导的结果,而是模型与强化学习环境互动的自发结果。这种自发性显著增强了 DeepSeek-R1-Zero 的推理能力,使其能够以更高的效率和准确性处理更具挑战性的任务,验证了RL的方案可行性。
实验观察到模型自我进化:随着 test-time computation(也就是生成 token 数)的增加,DeepSeek-R1-Zero 涌现出复杂的行为,例如反思,以及探索解决问题的替代方法,还观察到有趣的”顿悟时刻“(aha moment)。这些行为并非人类明确引导的结果,而是模型与强化学习环境互动的自发结果。这种自发性显著增强了 DeepSeek-R1-Zero 的推理能力,使其能够以更高的效率和准确性处理更具挑战性的任务,验证了RL的方案可行性。
 缺点:纯 RL 训出来的 DeepSeek-R1-Zero 虽然推理能力提升,但可读性不太好(比如没有 markdown 格式导致看起来不是很顺眼),而且容易出现语种混杂(尤其是对于非中英语种的 prompt)。所以此时的模型并不能作为一个合格的类 o1 模型发布给用户使用,于是有了接下来图二的 DeepSeek-R1 训练。
缺点:纯 RL 训出来的 DeepSeek-R1-Zero 虽然推理能力提升,但可读性不太好(比如没有 markdown 格式导致看起来不是很顺眼),而且容易出现语种混杂(尤其是对于非中英语种的 prompt)。所以此时的模型并不能作为一个合格的类 o1 模型发布给用户使用,于是有了接下来图二的 DeepSeek-R1 训练。
图二:DeepSeek-R1 训练
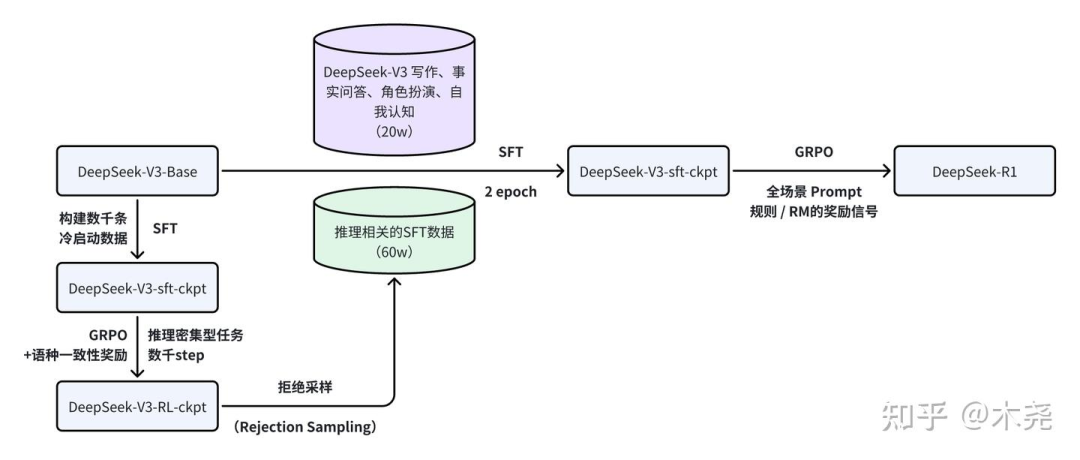 训练过程:主要包含四个大步骤,冷启动sft、推理任务强化学习、拒绝采样与sft、全场景强化学习。
与 DeepSeek-R1-Zero 不同,为了避免预训练 base 直接 RL 早期不稳定,于是构建几千条 long CoT 数据来微调模型作为 RL 的初始化 actor。设计了可读性高的 pattern,定义输出格式为 |special token|<思考过程>|special token|<答案总结>。探索了几种方法来构建数据:
训练过程:主要包含四个大步骤,冷启动sft、推理任务强化学习、拒绝采样与sft、全场景强化学习。
与 DeepSeek-R1-Zero 不同,为了避免预训练 base 直接 RL 早期不稳定,于是构建几千条 long CoT 数据来微调模型作为 RL 的初始化 actor。设计了可读性高的 pattern,定义输出格式为 |special token|<思考过程>|special token|<答案总结>。探索了几种方法来构建数据:
-
使用 long CoT 作为 example 的 few-shot 提示
-
通过 prompt 让模型生成包含反思(reflection)和验证(verification)的详细答案
-
收集 DeepSeek-R1-Zero 的可读格式输出,并通过人工标注后处理来完善结果
在使用冷启动数据对 DeepSeek-V3-Base 进行微调后,使用与DeepSeek-R1-Zero 相同的 RL 策略进行训练直到收敛。这一阶段专注于提升模型在推理密集型任务(如编码、数学、科学和逻辑推理)中的推理能力,这些任务涉及定义明确的问题和清晰的解决方案。
奖励建模的 trick:在训练过程中,观察到 CoT 经常出现语言混用,特别是 prompt 涉及多种语言时。为了缓解语言混用问题,我们在强化学习训练中引入了语言一致性奖励,该奖励计算为链式推理中目标语言单词的比例。尽管消融实验表明,这种对齐会导致模型性能略有下降,但该奖励与人类偏好一致,使模型输出更具可读性。训练的时候将推理任务的准确性奖励与语言一致性奖励直接相加,形成最终奖励。
拿上一步RL收敛的ckpt用于生成sft数据。与冷启动主要关注推理任务不同,这一阶段纳入了其他领域的数据,以增强模型在写作、角色扮演等通用任务中的能力。具体来说,按照以下方式生成数据并微调模型。
-
推理数据:通过 reasoning prompts 用拒绝采样生成推理轨迹。在前一阶段,仅纳入了可以通过基于规则的奖励进行评估的数据。然而,在这一阶段,通过纳入额外的数据扩展了数据集,其中一些数据使用生成式奖励模型,将真实结果和模型预测输入 DeepSeek-V3 进行判断。此外,由于模型输出有时混乱且难以阅读,于是过滤掉了语言混用、长段落和代码块的链式推理。每个提示采样多个回答,并仅保留正确的回答。总共收集了约 60万条推理相关的训练样本。
-
非推理数据:对于非推理数据,如写作、事实问答、自我认知和翻译,重用 DeepSeek-V3 的部分监督微调数据集,通过提示 DeepSeek-V3 生成 CoT 然后回答问题。对于更简单的问题,如“你好”,不会在回答中提供 CoT。最终收集了大约20万条与推理无关的训练样本。
使用这 80w 数据集直接对预训练模型 DeepSeek-V3-Base 进行 2 epoch 的微调。
为了进一步使模型与人类偏好对齐,这里再进行强化学习,旨在提升模型的有用性和无害性,同时优化其推理能力。具体使用了组合的奖励信号和多样化的提示分布来训练模型。
-
对于推理数据,遵循 DeepSeek-R1-Zero 中概述的方法,利用基于规则的奖励来指导数学、编码和逻辑推理领域的学习过程。
-
对于通用数据,采用奖励模型来捕捉复杂且微妙场景中的人类偏好。
数据方面,基于 DeepSeek-V3 的流程,并采用类似的偏好对和训练集的 prompt 分布。
-
有用性方面,专注于最终总结,确保评估强调响应对用户的实用性和相关性,同时尽量减少对底层推理过程的干扰。
-
无害性方面,评估模型的整个答案,包括推理过程和最终答案总结,以识别和减轻在生成过程中可能出现的任何潜在风险、偏见或有害内容。
最终通过组合奖励和多样化的数据分布,训练出在推理方面表现出色的、优先考虑有用性和无害性的、震惊了一把整个AI圈子的、性能比肩 OpenAI o1 的 DeepSeek-R1。
失败尝试:早期其实也尝试过 o1 发布那会儿盛传的过程奖励模型(PRM)和 蒙特卡洛树搜索(MCTS)方案,但效果并没达到预期。可能是因为:
-
PRM 不太好定义细粒度步骤、每一步正确与否也不好判断、PRM的引入可能导致 reward hacking 而且还得费资源重新训奖励模型;
-
MCTS 对于 next token prediction 任务,并不想下象棋那样有明确的搜索空间,token 生成的搜索空间那可是呈指数增长的;如果给每个节点设置最大扩展限制,可能导致模型陷入局部最优。
图三:DeepSeek-R1-Distill 系列小模型蒸馏
 图三:DeepSeek-R1-Distill 系列小模型蒸馏
训练方式:直接用刚才训 DeepSeek-R1 的 80w 数据对 qwen 和 llama 做 sft,包括 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B和Llama-3.3-70B-Instruct。对于蒸馏模型,仅应用监督微调(SFT),并未包括强化学习阶段(尽管加入强化学习可以显著提升模型性能)。这里的主要目标是展示蒸馏技术的有效性,将强化学习阶段的探索留给更广泛的学术界。
图三:DeepSeek-R1-Distill 系列小模型蒸馏
训练方式:直接用刚才训 DeepSeek-R1 的 80w 数据对 qwen 和 llama 做 sft,包括 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B和Llama-3.3-70B-Instruct。对于蒸馏模型,仅应用监督微调(SFT),并未包括强化学习阶段(尽管加入强化学习可以显著提升模型性能)。这里的主要目标是展示蒸馏技术的有效性,将强化学习阶段的探索留给更广泛的学术界。
-
将更强大的模型蒸馏到小型模型中可以取得优异的结果,而小模型仅依赖本文讨论的大规模强化学习可能需要巨大的计算资源,且可能无法达到蒸馏的性能。
-
尽管蒸馏策略既经济又有效,但要超越智能边界,可能仍需要更强大的基础模型和更大规模的强化学习。
总结
本文用三张图介绍了 DeepSeek-R1 论文的三个核心内容(纯RL的方案可行性、DeepSeek-R1修炼手册、蒸馏小模型的潜力)。未来会聚焦通用能力提升(函数调用、多轮对话、复杂角色扮演以及 json 输出等任务上的表现不如 DeepSeek-V3)、语言混用问题解决(尤其是针对非中英prompt)、prompt engineering(比如 DeepSeek-R1 对 prompt 较为敏感,few-shot 会降低性能)、软件工程任务上的改进等。
最后,放一张论文中的评测图和 lmarena.ai 的排行,祝国产大模型越来越好!

 lmarena 排行(2025.01.28 除夕凌晨)
lmarena 排行(2025.01.28 除夕凌晨)
参考资料
论文:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
模型:https://huggingface.co/deepseek-ai/DeepSeek-R1
排行:https://lmarena.ai
(文:机器学习算法与自然语言处理)
