


极市导读
本文提出了一种名为SIDGaussian的基于三维高斯散射的稀疏输入方法,有效生成渲染图像中的细节并保持多视图一致性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
导读
在新视图合成领域中,3DGS一直表现不俗,但在稀疏输入视图的情形下,渲染质量常会显著下降并导致细节缺失,然而在一些特殊的条件下,稠密的输入不一定能够得到保证,因此如何让稀疏的场景也充满细节,是3DGS领域的主要挑战。
为应对这一问题,该研究提出了一种稀疏视图3DGS方法,通过预训练的DINO-ViT模型提取特征进行语义正则化,以确保多视图语义一致性,并加入局部深度正则化来提升对未见视角的泛化能力,经过该改进,该方法在LLFF数据集上的PSNR可较现有前沿方案最高提升0.4dB,明显减少失真并增强视觉细节,为新视图合成提供了更优的解决方案。
论文标题:See In Detail: Enhancing Sparse-view 3D Gaussian Splatting with Local Depth and Semantic Regularization
论文作者:Zongqi He, Zhe Xiao, Kin-Chung Chan, Yushen Zuo, Jun Xiao, Kin-Man Lam
论文地址:https://arxiv.org/abs/2501.11508

01 引入
该研究旨在通过从不同已知视点捕捉的一组图像,生成同一场景在未见过的视角下的逼真图像,同时保持多视图一致性。 新颖视图合成(NVS)技术对于理解三维世界至关重要,并在计算机视觉、图形学和机器人等实际应用中具有显著的工业价值。
基于神经辐射场(NeRF)的方法和基于三维高斯散射的方法是近年来表现出色的两种主要方法。然而,这两种方法通常需要来自密集视图的输入图像以生成高质量的未见视角图像,而在现实场景中往往难以满足这一条件。随着输入视图数量的减少,渲染质量不可避免地下降。目前,从稀疏输入生成新颖视图仍然是一个重大挑战。
近年来,已经提出了几种基于稀疏输入生成高质量三维场景的有前景的方法。例如,RegNeRF引入了一种深度平滑技术,以提高重建场景几何属性的准确性;DietNeRF通过鼓励由预训练的CLIP视觉变换器编码的视图在潜在空间中彼此靠近,从而增强语义一致性;SparseNeRF利用由预训练的密集预测变换器(DPT)估计的密集深度图,提取局部深度排序先验,促进空间连续性。尽管基于NeRF的方法在稀疏输入的新颖视图合成方面表现出色,但其较慢的推理速度和高计算需求限制了其在实时产品中的应用。最近,3DGS已被证明在实时高质量渲染三维场景方面有效,但其在稀疏输入新颖视图合成中的潜力尚未得到充分探索。
在本文中,提出了一种名为SIDGaussian的基于三维高斯散射的稀疏输入方法,有效生成渲染图像中的细节并保持多视图一致性。 由于基于稀疏输入生成高质量三维场景本质上是一个不适定问题,结合先验信息对于提升性能至关重要。为更好地解决这一问题,提出了一种语义正则化技术,通过最小化训练视图和侧视图渲染图像的语义特征在潜在空间中的距离,确保多视图语义一致性,这些特征由DINO-ViT提取。
稀疏输入的设置往往导致外观覆盖不足和几何信息有限,导致现有方法中的内容失真。为解决这一问题,进一步提出了一种局部深度正则化方法。该方法不是直接使用像DDPNeRF那样的密集深度图,而是对深度图进行局部归一化,并在局部区域内计算渲染深度与DPT深度图之间的皮尔逊相关系数。这种方法有效增强了场景的局部几何结构,并改善了生成输出的多视图一致性。
本文的主要贡献总结如下:
-
提出了一种名为SIDGaussian的三维高斯散射方法,用于基于稀疏输入的新颖视图合成,能够实现实时和高质量的三维场景渲染。
-
为确保多视图一致性,提出了一种语义正则化技术,保持渲染图像在不同视点之间的语义连贯性。此外,提出了局部深度正则化以减少失真并增强场景的细节几何结构。
-
实验表明,该方法显著优于最先进的新颖视图合成方法,在LLFF数据集上在PSNR方面提升了高达0.4dB。
该方法能够有效保持多视图一致性,并在最小失真的情况下生成视觉效果优越的结果。
02 具体方法与实现
该研究的方法流程如图2所示。具体而言,首先采用结构光法(Structure from Motion, SfM)构建稀疏点云,用于3DGS的初始化。 这一步骤利用SfM技术从输入的稀疏视图中提取相机参数和稀疏点云,确保初始的三维结构能够有效地反映场景的几何特征。随后,在训练过程中,针对每一个场景进行逐步优化。优化过程由三个主要部分共同监督:L0损失、提出的语义正则化以及局部深度正则化。
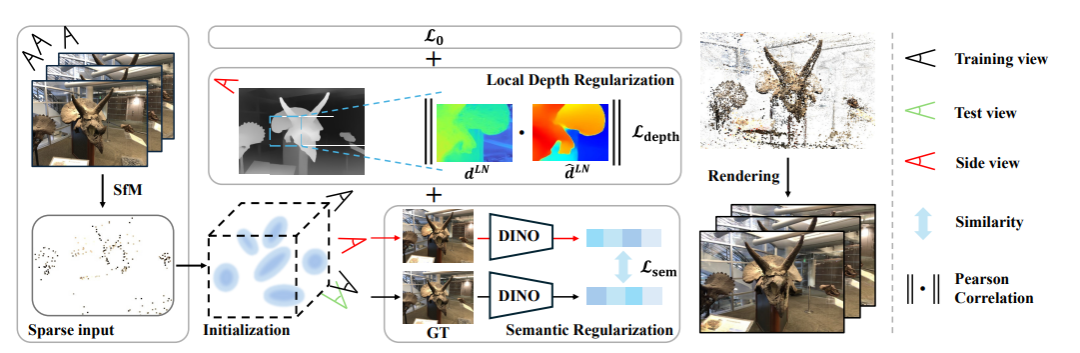
从整个流程可以看出,本文的初始化阶段与3DGS的基本初始化过程具有相似性,都是依赖于SfM生成的稀疏点云进行三维高斯的初始化。然而,在训练优化阶段,由于输入图像数量稀少,传统的方法缺乏足够的监督信息,这导致生成的细节部分渲染效果不尽如人意。为了克服这一挑战,本文提出了两种新的监督方式,专门针对细节部分的内容进行优化。这两种监督方式主要通过局部深度和语义信息来实现,一方面从几何层面建立约束,另一方面从宏观的语义层面增强一致性。
我们先来建立一个初步的认识:语义正则化通过引入语义特征,确保从不同视点生成的图像在语义层面上保持一致。 使用预训练的DINO-ViT模型对训练视图和侧视图进行编码,并在潜在空间中最小化它们的语义特征距离,从而促进生成图像在语义上的连贯性和一致性。这一方法有效地提升了生成图像的整体语义质量,避免了由于视角稀疏导致的语义信息缺失问题。
另一方面,局部深度正则化通过对深度图进行局部归一化,并在局部区域内计算渲染深度与由预训练的Dense Prediction Transformer(DPT)生成的深度图之间的皮尔逊相关系数,从而增强了局部几何细节的准确性。 这种方法不仅保留了全局深度信息的整体结构,还能够细致地捕捉到场景中不同尺度物体的局部几何特征,显著减少了由于深度信息不足导致的细节缺失和几何失真。
通过引入这两种新的监督方式,本文的方法在训练过程中能够更加有效地利用有限的输入图像,显著提升了渲染图像的细节质量和多视图一致性。具体而言,语义正则化确保了生成图像在语义上的一致性,而局部深度正则化则从几何层面增强了细节的准确性。这两者的结合使得3DGS在处理稀疏输入时,能够生成更加细腻和真实的三维场景。
因此,本文方法的核心创新在于这两个约束的建立与应用。 在具体的方法与实现部分,本文将详细介绍这两种监督方式的技术细节,包括语义正则化和局部深度正则化的具体实现步骤、损失函数的设计以及如何在训练过程中有效地结合这两种约束,以实现高质量的三维场景渲染。
■ 语义正则化
通过前面的初步引入,相信各位读者已经对语义正则化有了一点初步的认识,首先我们知道,语义正则化在重建场景的全局结构方面已被证明是有效的。该正则化方法的核心理念在于通过引入高层次的语义信息,指导模型在生成未见过的侧视图时能够保持与训练视图一致的语义内容,从而避免因视点稀疏导致的语义信息丢失和重建错误。具体而言,这种正则化方法鼓励生成的侧视图在语义上与训练视图具有相似的意义和内容分布。
在该研究的方法中,首先通过生成未在训练集中出现的侧视图,以模拟不同的观察角度。这些侧视图可能包含与训练视图不同的场景细节和视角信息。 为了捕捉和利用这些视图中的语义信息,研究采用了预训练的DINO-ViT模型对侧视图和训练视图进行特征编码。DINO-ViT作为一种先进的视觉变换器,能够提取图像的高层次语义特征,这些特征有效地表示了图像中的物体类别、结构和语义关系。
通过对侧视图和训练视图的特征进行编码,研究获得了对应的语义特征向量。语义正则化项被定义为这些编码后的特征向量之间的距离,即通过计算不同视点的语义特征向量之间的欧氏距离或其他度量方式,量化它们在语义空间中的相似度。具体而言,研究将侧视图渲染图像和训练视图图像的语义特征向量进行匹配,并最小化它们之间的距离。这一过程确保了不同视点生成的图像在语义上具有一致性,从而提升了重建场景的整体语义连贯性和准确性。
此外,语义正则化不仅有助于保持图像的语义一致性,还能够促进生成模型在处理复杂场景时更好地理解和保持场景中的关键结构和对象。通过这种方式,研究的方法能够在有限的输入视图下,生成具有高语义质量和细节丰富的三维场景渲染结果。这一语义正则化策略为模型提供了额外的约束和指导,显著提升了生成图像的整体质量和多视图一致性。
■ 局部深度正则化
先前的方法利用全局深度信息来促进三维几何结构的重建,但在处理包含多尺度不同物体的场景时效果有限。全局深度信息往往侧重于整体特征,忽略了深度信息的细节。为了克服全局深度信息在细节重建上的不足,该研究提出在侧视图上引入局部深度正则化,以增强三维物体的局部几何细节。具体来说,这一方法包括以下几个关键步骤:
深度图的局部归一化: 首先,对深度图进行局部归一化处理。局部归一化的目的是在每一个局部区域内调整深度值,使其均值为零,标准差为一。这一过程能够消除不同区域之间深度值的绝对差异,使得模型能够更专注于局部深度变化的相对关系,而不是依赖于全局的深度尺度。这种归一化方法有助于提升模型在不同局部区域内捕捉细节的能力,确保在多尺度场景中各个物体的细节部分都能得到充分的重建。
局部区域内的深度相似性: 在进行局部归一化后,研究鼓励渲染深度图与由预训练的密集预测变换器(Dense Prediction Transformer, DPT)生成的深度图在每个局部区域内保持相似性。具体而言,通过计算渲染深度图和DPT深度图在局部区域内的皮尔逊相关系数(Pearson Correlation),量化它们之间的相似度。皮尔逊相关系数是一种衡量两个变量线性相关程度的统计量,能够有效减轻深度尺度不一致带来的影响。通过最大化这一相似性,模型能够更准确地重建局部几何细节,确保生成的三维场景在各个局部区域内都具有高精度的几何结构。
多尺度细节的保留: 局部深度正则化不仅提升了局部区域的深度准确性,还能够有效保留多尺度细节。在复杂场景中,不同尺度的物体可能需要不同的深度处理策略。通过在多个局部区域内分别进行深度归一化和相似性计算,模型能够自适应地调整各个区域的深度信息,确保大尺度物体的整体结构和小尺度物体的细节部分都能得到合理的重建。这种方法避免了全局深度信息在多尺度场景中的局限性,使得生成的三维模型在不同尺度下都能保持高度的一致性和细节丰富性。
优化过程中的约束: 在训练过程中,局部深度正则化作为一个重要的约束项被引入总损失函数中。具体而言,研究将渲染深度图与DPT生成的深度图的局部相似性作为一个独立的损失项加入到总损失函数中,确保在优化过程中不仅关注全局深度一致性,还重视局部几何细节的准确性。通过这种多层次的约束,模型能够在稀疏输入条件下,生成具有高精度和高细节的三维场景。
■ 综合损失函数
总损失函数由多个加权部分组成,包括L0损失、语义正则化损失和深度正则化损失。 这些部分的权重是超参数,通过组合这些损失项,该方法能够在优化过程中平衡各方面的要求,最终实现高质量的三维场景渲染。
03 实验
该研究在本地光场融合(Local Light Field Fusion, LLFF)数据集上进行了实验。 LLFF数据集包含8个场景用于训练和测试,每个场景由20到62张来自不同视点的图像组成。
按照既定配置,研究选择每第八张图像作为测试集,并从剩余图像中均匀采样三视角用于训练。在训练和测试过程中,研究的方法在图像的1/8和1/4比例下实现。为了实现局部深度正则化,研究将从深度图中提取的局部补丁大小设定为126×126。迭代次数固定为1.2万次。所有实验均在NVIDIA RTX 4090 GPU上进行。
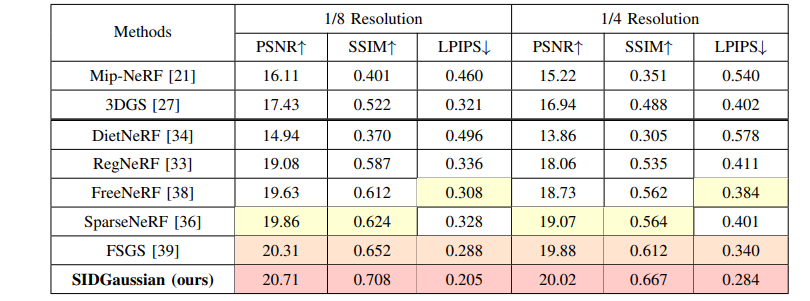
模型性能通过峰值信噪比(PSNR)和结构相似性指数(SSIM)来评估重建质量,并通过学习感知图像补丁相似性(LPIPS)来衡量渲染图像的感知质量,数值实验结果由图4所示,能够看到该研究的数值能够跑赢对比的方法(红色染色部分)。
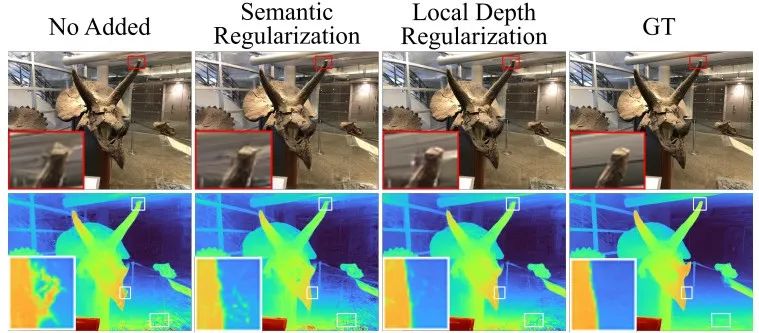
作者还对渲染的效果进行了可视化,如图5所示。

研究还通过消融实验探讨了所提出方法的两个方面:语义正则化和局部深度正则化。通过在LLFF数据集上的定量和视觉结果,研究展示了语义正则化如何显著提升渲染结果的质量,结果如图6和图7所示,这两个实验的结果进一步证明了增强语义一致性的有效性。
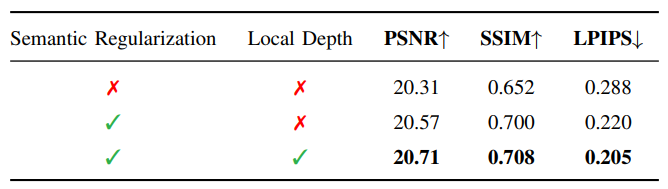
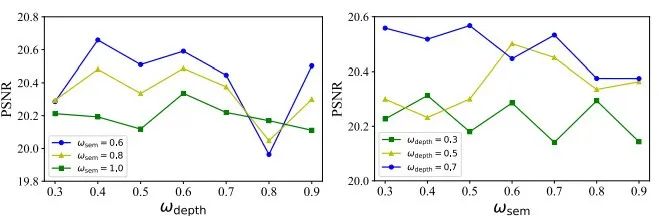
由此可见,局部深度正则化进一步提高了渲染质量,提供了更精确的细节。此外,研究表明了语义正则化和深度正则化权重的对于3DGS的训练有不同的敏感性(如图7),通过调整相应的权重值,对模型性能的影响各不相同,因此可以根据所需要的重建和渲染的场景自适应的调整其权重,最终获得满意的重建效果。
04 总结
本文聚焦于基于稀疏输入的新颖视图合成,提出了一种稀疏视角的三维高斯散射模型,称为SIDGaussian。 为了确保多视图一致性,研究提出了一种语义正则化技术,旨在保持渲染图像在不同视点之间的语义连贯性。此外,研究还提出了一种局部深度正则化方法,以减轻内容失真并增强渲染图像的细节信息。实验结果表明,所提出的SIDGaussian在LLFF数据集上的峰值信噪比(PSNR)和学习感知图像补丁相似性(LPIPS)指标上显著优于其他最先进的方法,提升幅度高达0.4dB。该方法生成的图像在视觉质量上表现最佳,失真程度较低。
Ref:See In Detail: Enhancing Sparse-view 3D Gaussian Splatting with Local Depth and Semantic Regularization
编译|阿豹
审核|apr

(文:极市干货)