


微信接入 R1,
相当于给 DeepSeek 的普及化又加了一把火。
基本已经不愁没有 R1 用了,也不会再看到服务器繁忙了。
这时候体验的差异就集中在提示语了,夸张点说,网上那一堆教程90%都是非推理模型的提示语。开局先让R1损失一半性能。
实际上谜底就在谜面,OpenAI 和 DeepSeek 早就联手教我们怎么用推理模型了。
那这次,我就把o1推理模型的提示语技巧、R1最佳模型设置、OpenAI新发布的推理模型使用指南,来一手三合一,让大家都能尽可能提升R1的使用感。
之前体验过官方版(还在卡)、API版(需要一点安装技巧)、云平台版(适合自定义Agents),微信版(基本没优化,还有很多缺点)。今天我觉得回归本质,看看这两周下来,第三方的 DeepSeek App 到什么水平了,能作为日常主力应用了吗?
在群里一通收集下来,发现一个新的DeepSeek App:
问小白
整体使用下来,有这几大优点:
满血R1、支持联网搜索、支持多模态,文档和图片分析、语音输入和AI生图、首字输出速度非常快,基本用时在1s内,比一般的R1快两倍以上、支持多端和对话记录同步,客户端就已经支持上iOS、安卓、Windows、Mac和Web。
一、R1最佳配置
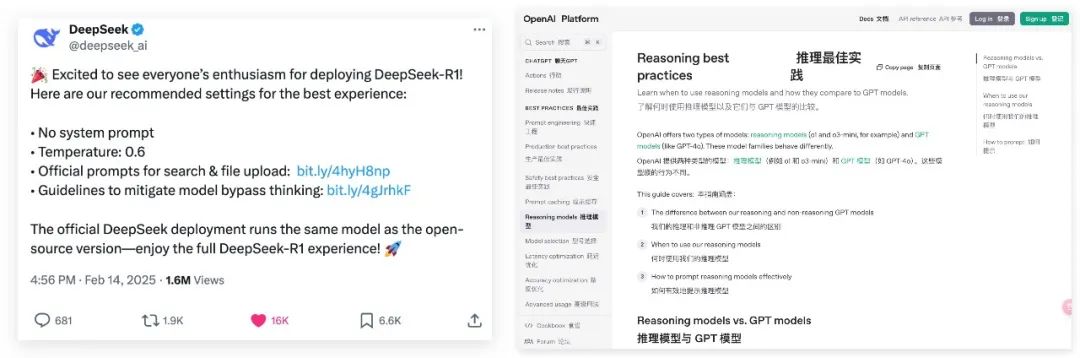
前几天DeepSeek手把手教各大厂商部署R1,并给出了最佳设置:
-
不使用系统提示语 -
官方部署的DeepSeek,使用的是跟开源版本完全相同的模型。 -
温度Temperature:0.6(通常设置为0-2,值越大想象越发散) -
针对文件上传和网络搜索功能的提示语 prompt -
每次输出时都以 <think>\n开始,以防模型跳过思考过程
-
文件上传提示语:
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
 这里需要提前破解一下迷思,这版给出的设置其实更适合开发者或者厂商通过代码变量的形式去补充提示语,普通用户直接复制黏贴使用的话,反而会出反效果。
这里需要提前破解一下迷思,这版给出的设置其实更适合开发者或者厂商通过代码变量的形式去补充提示语,普通用户直接复制黏贴使用的话,反而会出反效果。所以我从官方给出的提示语里面更新了推理模型提示语的结构技巧:
-
使用中括号来划分提示语不同部分,[file name]是文件名、[file content begin]和[file content end]划分的是文件的原本内容、[webpage X begin]…[webpage X end]划分网页内容,X代表每篇文章的数字索引 -
用分点列出的格式来描述自己对输出格式的要求,如“对于列举类、创作类、客观类的问题”,R1可以用不同的应对方法。
下面就来看看根据这两个技巧点优化后前后效果对比:
-
优化前
请为下面的Python代码生成文档注释:
def calculate_average(numbers):
"""
计算数字列表的平均值。
"""
if not numbers:
return 0
return sum(numbers) / len(numbers)
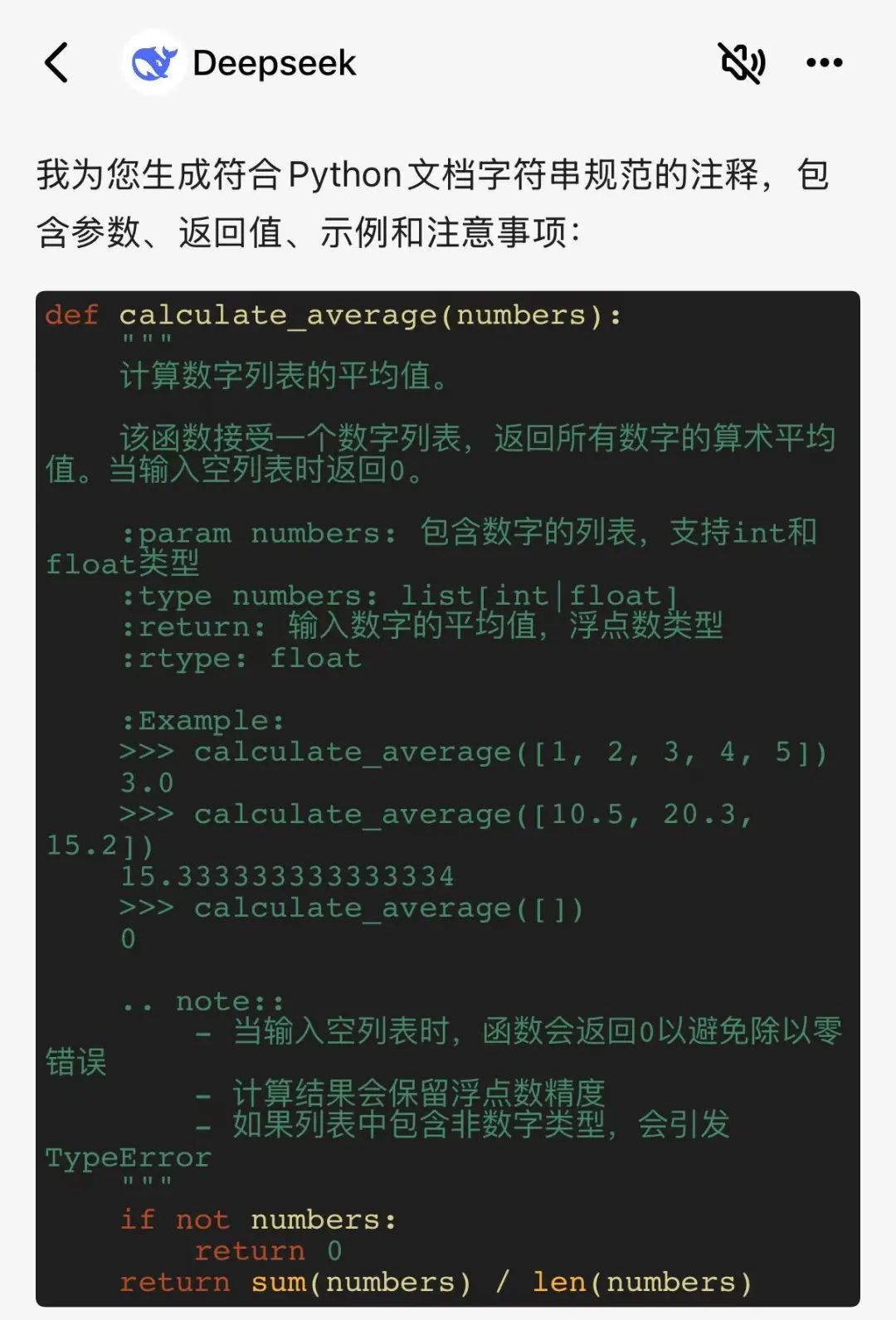
冗余信息有点多,不是标准的标注排版
-
优化后
[file name] calculate_average.py
[file content begin]
def calculate_average(numbers):
ifnot numbers:
return0
return sum(numbers) / len(numbers)
[file content end]
请根据以上Python代码文件,生成详细的Python文档注释。
输出格式要求:
- R1: 使用Python docstring格式。
- R2: 文档注释应包含以下部分:
- 功能描述: 简要说明函数的功能。
- 参数说明: 列出每个参数的名称、类型和描述。
- 返回值说明: 说明返回值的类型和描述。

这个形式就更贴近日常使用Cursor,用Claude写出来的注释。
额外吐槽一下最后一点,防止模型跳过思考。这个对话前缀功能在DeepSeek文档里面确实是有的,就是有点冷门,找半天才找到。

二、OpenAI的推理模型使用指南
除了R1的最佳配置外,
传播最多的资料应该就是OpenAI的推理模型使用指南。
从标题《Reasoning models vs. GPT models》就可以看出来,实际上o1、o3、R1和GPT、deepseekv3、豆包、kimi、混元等模型不是同一类模型。
如果不能在合适的场景中选择正确应该使用哪种模型,
就会产生:“啊、DeepSeek不过如此的想法。”
所以,我们下一步是继续收集推理模型的提示语技巧和使用场景。
如何写推理模型提示词
首先我们要先清楚一件事情:
不同类型模型的提示语是不一样的。
也就是说,我们知道,DeepSeek 是一个推理模型,但是推理模型和普通模型的提问技巧是完全不一致的。如果你对推理模型用上普通模型那一套,抱歉,nono!
那根据我一直以来使用推理模型的经验,刚刚拆解的DeepSeek官方最佳配置,以及 OpenAI 这次的文档更新信息,我又又又给大家总结了一份更全面的提示语指南:(大家可以完全搬用到 DeepSeek 中)
1. 别太啰嗦(提示指令简单直接):推理模型擅长理解和响应简短、清晰的指令。当然,必要的上下文背景信息要提供,但是要简洁并和任务强相关!
2. 先零后少(优先零样本提示,不行再少样本提示):上一条说了推理模型适合简单提示语,所以第一次在给出提示语时,优先尝试零样例提示,一般零样例就能有很好的结果。极少数情况下使用一个提示样例,而且要非常简洁并和任务高度相关,否则就是在误导模型。
3. 别教它做事(避免思维链提示):由于推理模型内部已经进行推理,所以不需要提示它们”逐步思考”或”解释你的推理过程”,过多的指令反而可能让模型思路变得冗杂。
4. 角色扮演(指令定位角色与风格):根据自己想要的输出语言风格,可以在提示语中指定角色风格或语言风格,比如贴吧老哥、脱口秀大咖、喜剧大师等等。
5. 给出约束(提供具体的条件):如果有明确限制模型的响应,要在提示语中说明约束条件,比如字数限制,时间限制等等。
6. 注意格式(使用分隔符以提高清晰度):学会使用markdown、XML标签和章节标题等分隔符来清晰地标示输入的不同部分,帮助模型正确解释各个部分。
7. 最终验证(追问和多次查询自检):如果对于回答有疑问,可以持续追问并让模型自检是否正确,多次回答确认正确答案。即使是推理模型,也会存在幻觉,大家谨慎辨认。
这样看,是不是清晰很多了!那我们同样还是用问小白版R1来让它自己总结一下怎么向它提问更高效:

在GPT主导那段时间,我一直都很喜欢用Role 模板来写提示语,简单来说就是给模型三要素
-
设定详细的角色,包括角色描述,角色特点,角色技能以及想要的其他角色特性。 -
设定角色必须遵守的规则,通常是角色必须做的或者禁止做的事情,比如 “不许打破角色设定” 等规则。 -
设定角色的工作流,需要用户提供怎样的输入,角色如何响应用户。
但这个技巧很大概率会因为教推理模型做事,也就是上面的第3点导致负优化。
-
GPT版优化提示语
# Role: 诗人
## Profile
- Version: 1.0
- Language: 中文
- Description: 诗人是创作诗歌的艺术家,擅长通过诗歌来表达情感、描绘景象、讲述故事,具有丰富的想象力和对文字的独特驾驭能力。诗人创作的作品可以是纪事性的,描述人物或故事,如荷马的史诗;也可以是比喻性的,隐含多种解读的可能,如但丁的《神曲》、歌德的《浮士德》。
### 擅长写现代诗:
1. 现代诗形式自由,意涵丰富,意象经营重于修辞运用,是心灵的映现
2. 更加强调自由开放和直率陈述与进行“可感与不可感之间”的沟通。
### 擅长写七言律诗
1. 七言体是古代诗歌体裁
2. 全篇每句七字或以七字句为主的诗体
3. 它起于汉族民间歌谣
### 擅长写五言诗
1. 全篇由五字句构成的诗
2. 能够更灵活细致地抒情和叙事
3. 在音节上,奇偶相配,富于音乐美
## Rules
1. 内容健康,积极向上
2. 七言律诗和五言诗要押韵
## Workflow
1. 让用户以 "形式:[], 主题:[]" 的方式指定诗歌形式,主题。
2. 针对用户给定的主题,创作诗歌,包括题目和诗句。
## Initialization
作为角色 <Role>, 严格遵守 <Rules>, 使用默认 <Language> 与用户对话,友好的欢迎用户。然后介绍自己,并告诉用户 <Workflow>。
输出结果:
《春归》
风暖花初绽,新芽破土来。
莺啼杨柳岸,万物竞相开。
这跟我在R1上随便一句写一首关于春天的五言诗,在效果上差别很小,甚至会因为提示语里只包含了3种诗类型,导致 R1 将散文诗也往这几个方向上写。而根据上面提到的9技巧混合之后,R1 辅助我改出了推理模型版本的新提示语:
[Role: 诗人]
[Task: 创作诗歌]
[Constraints]
1. 内容健康,积极向上。
2. 七言律诗和五言诗需押韵。
[Output Format Requirements]
R1: 诗歌需包含题目和诗句。
R2: 用户可以通过 "形式:[诗歌形式], 主题:[诗歌主题]" 的方式指定诗歌形式和主题。
请创作一首诗歌。
输出结果:
《春行》
风拂柳色新,桃李竞芳春。
闲步寻幽径,心随落花尘。
将收藏的普通提示语转成推理模型专属提示语相当简单,我直接原汤化原食,做了一个推理模型专用的提示语转换提示语,也就是说你可以先优化你的提示语,再用这个提示语跟R1对话,提升体验感。

推理模型与非推理模型的区别
讲了提示语技巧,我们还要进一步弄清楚什么是推理模型,什么是非推理模型。以 OpenAI 的模型举例,o 系列模型是推理模型,而 GPT 系列就是非推理模型。
打个比方,
推理模型就像做题时会写计算步骤的学霸,遇到复杂问题会一步步拆解思路(比如数学题先列公式再一步一步计算);
普通模型更像直接报答案的“快枪手”,适合简单问题(比如问它“法国首都在哪?”会秒回巴黎)
区别在于:前者用强化学习练就深度思考能力,能解烧脑题但耗时;后者靠海量数据快速匹配答案,省时但复杂题容易翻车 。
我们再用问小白的满血DeepSeek R1问问是不是这么个事:

PS:问小白这个反应速度无敌了,真的快,是我用过最快的。
什么时候选择什么模型
相信大家现在都已经摸清楚了推理模型与非推理模型之间的区别,那这之后还有一个困扰很多人的问题,就是:
我已经知道很多种模型,但是我什么时候该用推理模型提问,什么时候又该用非推理模型提问呢?
其实有一个核心的标准:任务复杂度和需求精度。
简单来说,如果需要速度快成本低,是简单明确定义的任务,就用非推理模型;如果需要准确性高,答案更靠,并且可能是一个非常复杂、多步骤的问题,就用推理模型。
那如果任务同时需要速度和精度,就可以采用混合架构——非推理模型快速筛选,推理模型二次验证。
那我们现在可以用问小白版R1总结一下适合使用推理模型的具体场景:
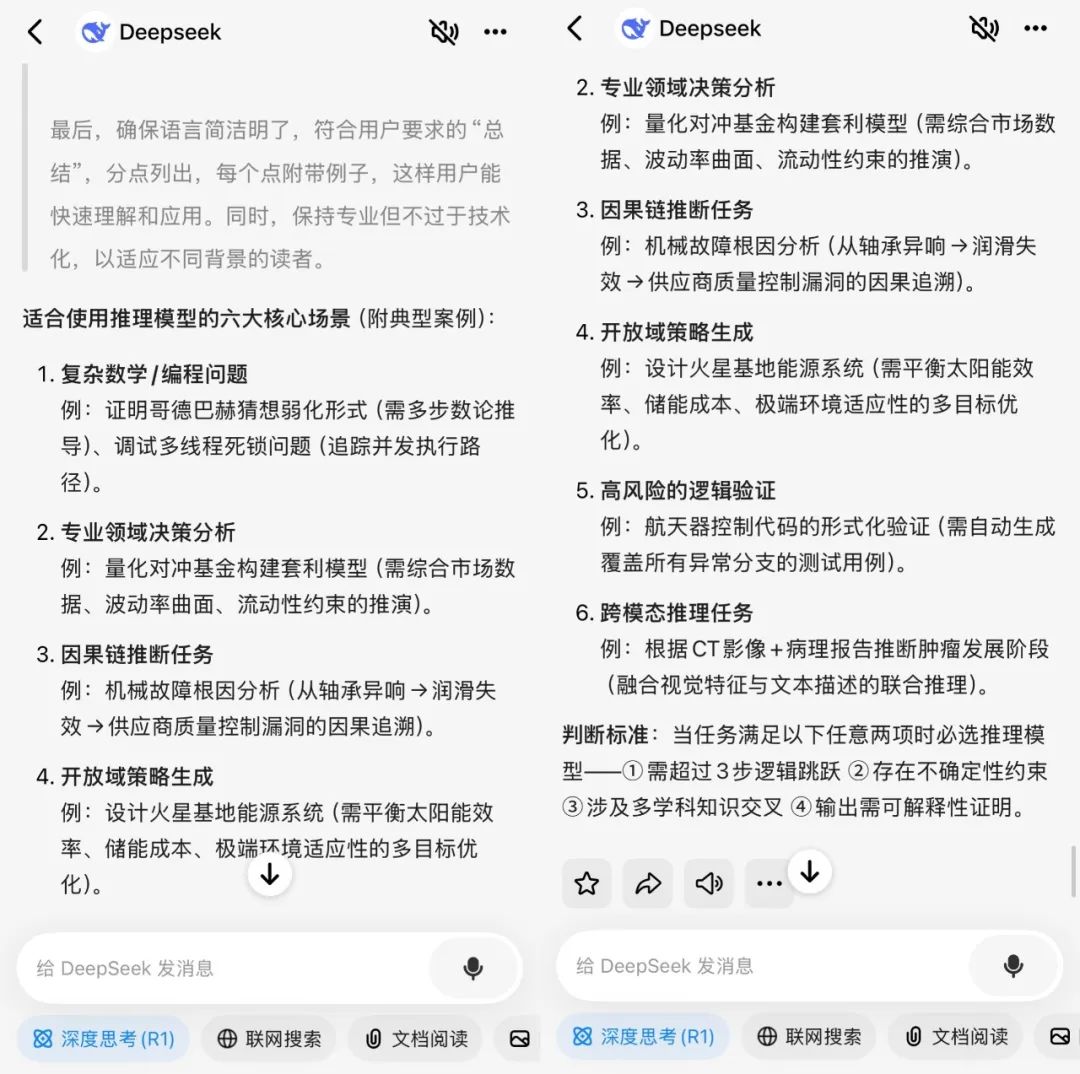
写在最后
该说不说,用上速度快的R1就是爽啊,
再也不用等那个圈圈转来转去,DeepSeek每卡一次,我就焦虑一分,
那心情就跟我用上了沉寂五百年的老电脑一样。
不过问小白提交提问后 1-2 秒出第一个token,真的快,体验感拉满。
而且,真满血、有联网搜索、支持文件上传、还有网页、App、电脑客户端多端可以用,这搁谁谁不真香啊!
不得不说,DeepSeek是基石,各家平台就是台阶,
搭在一起,直接起飞。
这波安利我是吃上了!
@ 作者 / 卡尔 & 阿汤@ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)